📝 Paper Summary
Query Expansion (QE)
Sparse Retrieval
ReAL enhances retrieval accuracy by using a relevance classifier to iteratively learn and assign importance weights to expanded query terms, separating helpful terms from noise.
Core Problem
PLM-aided query expansion methods treat all generated terms uniformly, but many expanded terms are irrelevant or noisy, leading to suboptimal retrieval when used with sparse retrievers.
Why it matters:
- Word mismatches in sparse retrieval lead to poor recall, which downstream readers cannot recover from
- Current LLM-based expansions generate many common or weakly relevant words that dilute the impact of critical terms if not weighted properly
- Existing term weighting methods (like SPLADE) are not designed to dynamically adapt to the specific relevance signals of PLM-generated expansions
Concrete Example:
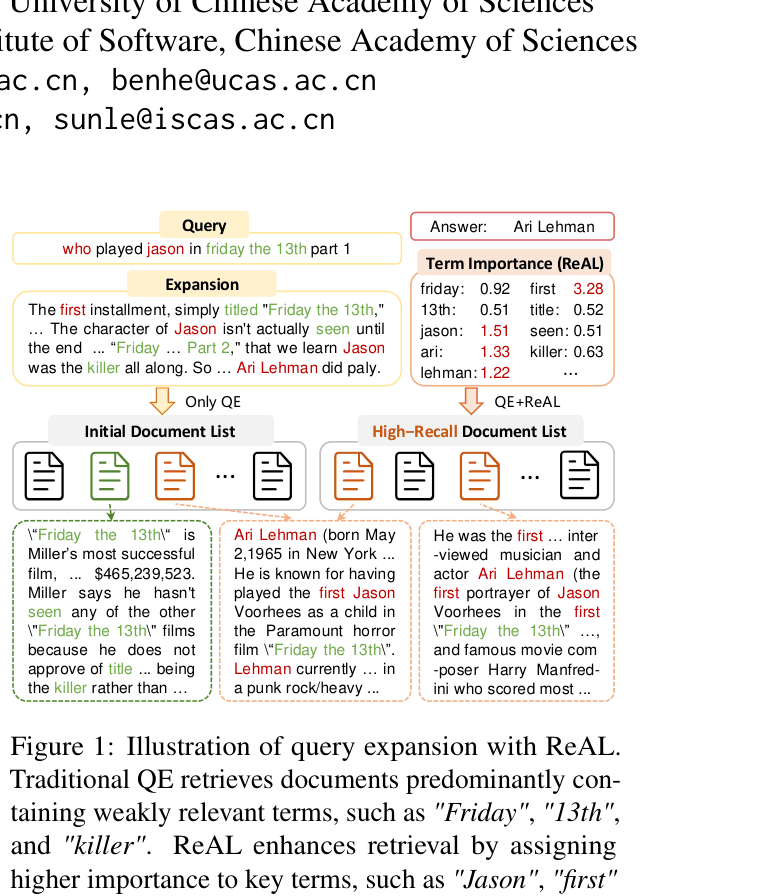
For the query 'who played jason in friday the 13th part 1', standard expansion adds terms like 'Friday', '13th', and 'killer'. A uniform-weight retriever retrieves documents about the movie franchise generally rather than the specific actor 'Ari Lehman', causing the reader to extract the wrong answer.
Key Novelty
Recall-oriented Adaptive Learning (ReAL)
- Classify initial retrieved documents into pseudo-relevant and pseudo-irrelevant sets using a strong relevance model (like a cross-encoder)
- Iteratively optimize a term weight vector to maximize the score gap between these two sets, effectively learning which expansion terms drive true relevance
Architecture
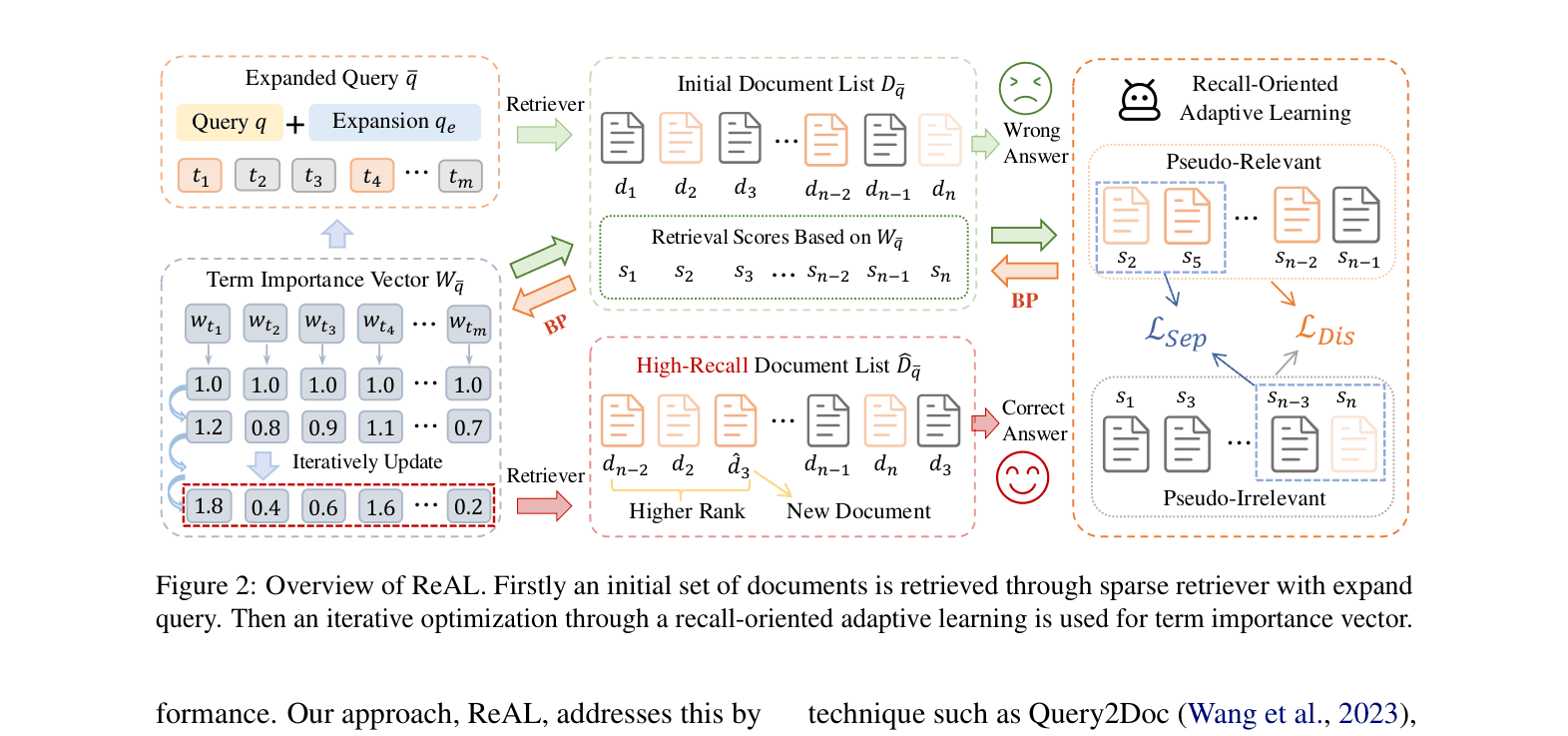
The iterative workflow of ReAL. It shows how the expanded query retrieves an initial list, which is then classified and used to optimize term weights.
Evaluation Highlights
- +2.6% Hit@20 improvement on Natural Questions when applying ReAL to standard BM25 retrieval without query expansion
- +1.4% Hit@20 gain on Natural Questions when adding ReAL to the state-of-the-art Query2Doc method
- Consistent improvements across four ODQA datasets (NQ, TriviaQA, WebQuestions, CuratedTREC) and five different query expansion baselines
Breakthrough Assessment
7/10
Solid methodological improvement for sparse retrieval. It effectively bridges the gap between generative query expansion and lexical retrieval constraints, showing consistent gains across multiple baselines.