📝 Paper Summary
Agentic reasoning over Knowledge Graphs (KGQA)
Neural-symbolic reasoning
DARA is a hierarchical agent framework that improves knowledge graph question answering by disentangling high-level iterative planning from low-level schema alignment and logical reasoning, finetuned on open-source LLMs.
Core Problem
Existing LLM agents for KGQA struggle with structured data environments because they mix planning and grounding, or rely on expensive proprietary models (GPT-4) via In-Context Learning which perform poorly compared to classical methods.
Why it matters:
- Classical ranking-based methods are brittle and require expert rules, while current LLM agents lag in accuracy on structured tasks.
- ICL-based agents using commercial models raise privacy/cost concerns (e.g., ~$1,300 for one test run vs ~$30 for DARA).
- Previous fine-tuned agents (e.g., AgentBench) fail to capture the hierarchical nature of KGQA, leading to subpar performance on unseen schemas.
Concrete Example:
For the question 'Who is the vice president serving under the president represented by localized_1?', a standard agent might hallucinate relations or fail to decompose the multi-hop requirement. DARA first identifies the task 'Find president represented by localized_1', grounds it to 'find_president', then iteratively identifies the next task 'Find vice president serving under...', effectively chaining the logic.
Key Novelty
Hierarchical Decomposition-Alignment-Reasoning
- Explicitly separates high-level planning (what to do next) from low-level grounding (interacting with the KG to find specific schema items), unlike previous flat reasoning chains.
- Introduces a 'skim-then-deep-reading' strategy for relation selection: the agent scans many relations quickly, selects top candidates, and only then reads full descriptions to finalize the choice.
- Uses iterative task decomposition where the agent generates one subtask at a time based on the execution result of the previous step, rather than planning everything upfront.
Architecture
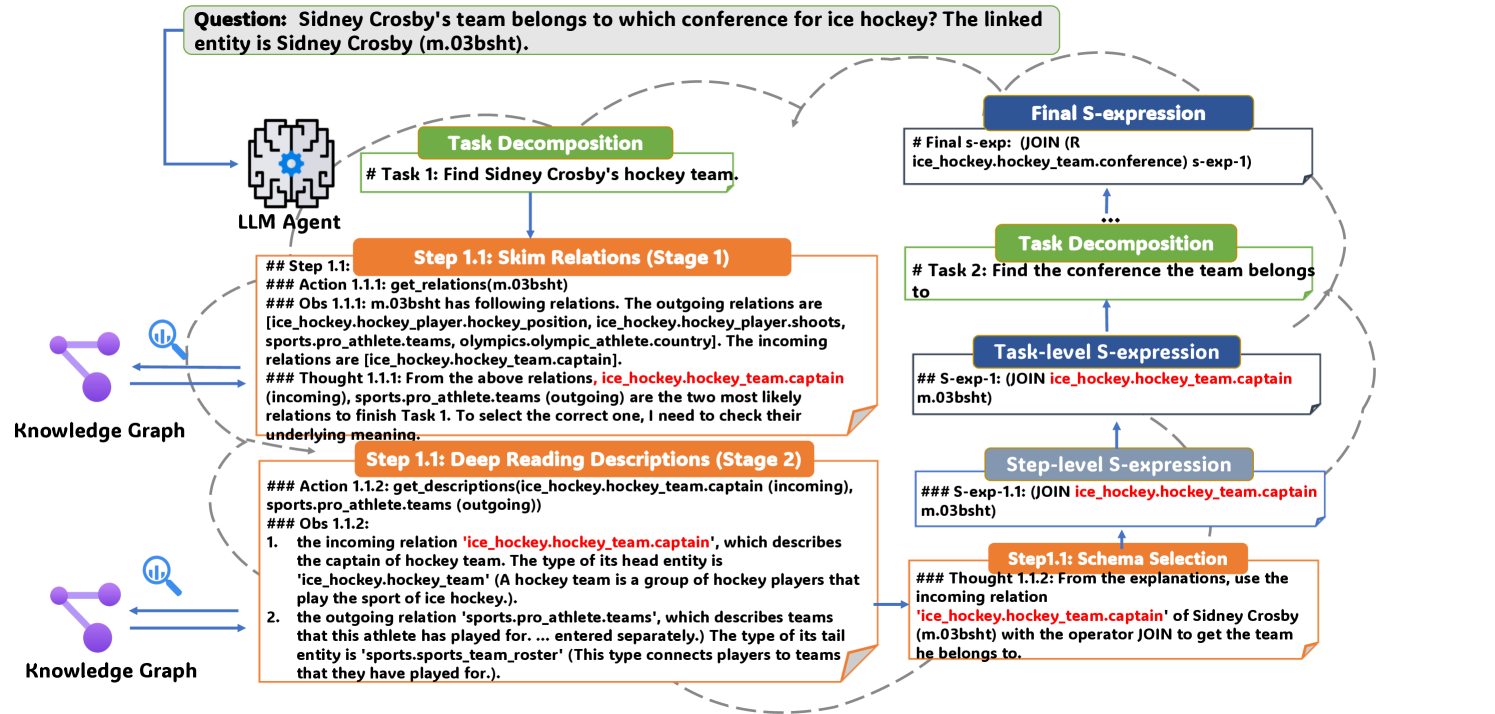
The iterative workflow of DARA interacting with a knowledge graph.
Evaluation Highlights
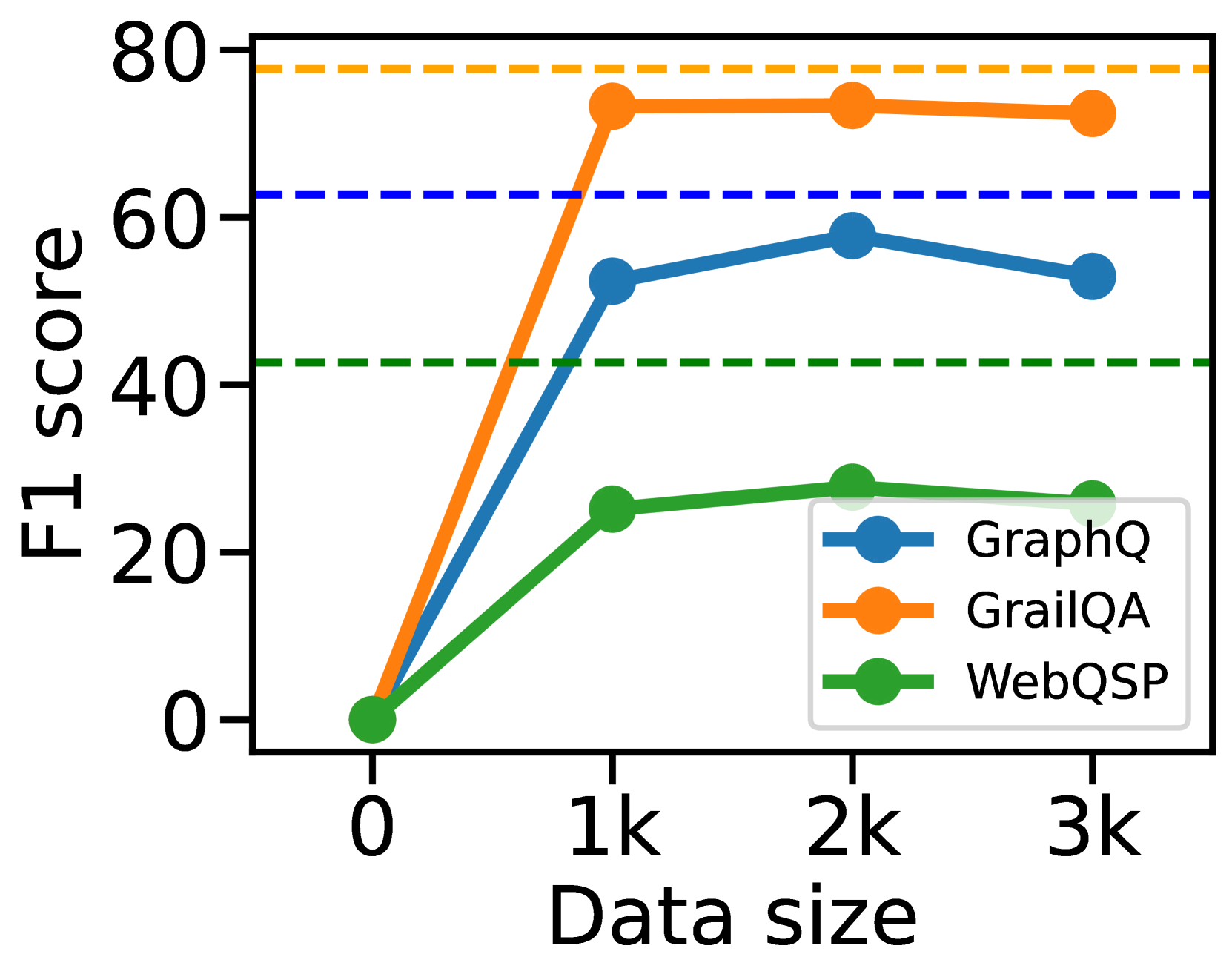
- Outperforms GPT-4 (ICL) by +7.7% F1 on GrailQA and +14.6% F1 on WebQSP in zero-shot settings using a much smaller Llama-2-7B base.
- Surpasses fine-tuned AgentBench-7B by ~15-20% F1 across benchmarks, proving the superiority of the hierarchical framework over flat agent tuning.
- Achieves parity with state-of-the-art ranking-based methods (Pangu) on GrailQA (79.0 vs 77.2 F1) while using significantly less training data (768 trajectories vs fully supervised).
Breakthrough Assessment
8/10
Significantly closes the gap between LLM agents and specialized symbolic solvers for KGQA. Demonstrates that small open-source models can beat GPT-4 on structured reasoning if the agentic framework is well-designed.