📝 Paper Summary
Visual Language Models (VLMs)
Visual Reasoning
DualMindVLM is a visual language model trained to automatically switch between concise responses (System 1) and detailed reasoning chains (System 2) based on problem difficulty, optimizing both accuracy and token efficiency.
Core Problem
Current reasoning-oriented VLMs are trained to always output long, step-by-step reasoning chains (System 2), even for simple perceptual tasks where such detail is unnecessary.
Why it matters:
- Excessive token generation increases computational costs and latency for end-users
- Existing models lack the human-like ability to dynamically allocate cognitive resources based on task difficulty
- Forcing complex reasoning on simple tasks (overthinking) creates redundancy without improving accuracy
Concrete Example:
When asking a model to recognize a simple emoji, a standard reasoning model (like one trained with GRPO) generates a long chain of thought analyzing pixel details before answering, whereas a human would recognize it instantly. The proposed model outputs 'Short Thinking:' and the answer immediately.
Key Novelty
Two-stage RL framework for automatic thinking-mode switching
- Auto-labeling stage: Uses the base model's natural response length to classify training data as requiring 'fast' or 'slow' thinking without external supervision
- Dual-mode RL stage: Trains the model to output a specific mode prefix ('Short Thinking' or 'Long Thinking') and switch strategies, using hybrid sampling where half the training rollouts are forced into the correct mode and half are free-form
Architecture
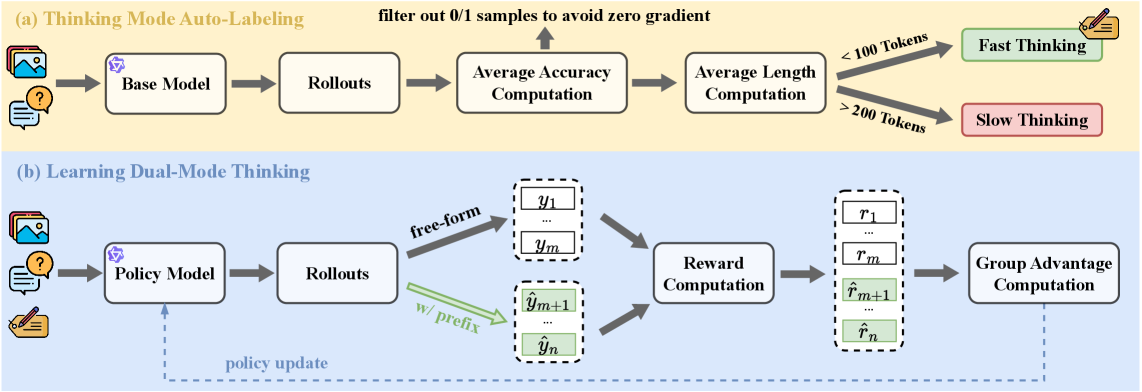
The two-stage training pipeline: Thinking Mode Auto-Labeling and Learning Dual-Mode Thinking.
Evaluation Highlights
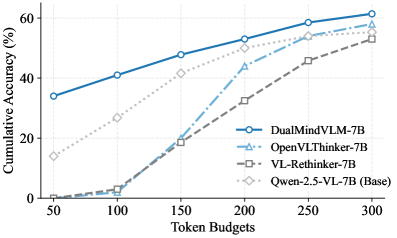
- +7.4% accuracy improvement on MathVista (Testmini) compared to the base Qwen2.5-VL-7B model
- Reduces token usage by ~40% on average compared to the best-performing reasoning baselines while maintaining competitive accuracy
- Outperforms state-of-the-art reasoning models on 4 out of 6 benchmarks (MathVista, MMStar, ScienceQA, AI2D)
Breakthrough Assessment
8/10
Elegantly solves the 'overthinking' problem in reasoning models using a self-supervised labeling approach. Achieves SOTA accuracy with significantly lower compute, a critical step for practical deployment.