📝 Paper Summary
Modularized RAG pipeline
ActiShade improves multi-hop reasoning by detecting keyphrases in queries that models ignore (overshadowed knowledge), then retrieving specific documents for those phrases to guide subsequent reasoning steps.
Core Problem
In multi-hop reasoning, dominant conditions in a query often 'overshadow' other critical details, causing the LLM to ignore them when generating the next retrieval query.
Why it matters:
- Standard multi-round RAG methods rely on LLM-generated content for the next step; if the LLM ignores a condition, the subsequent retrieval becomes irrelevant
- This leads to error accumulation where the reasoning chain breaks early because necessary supporting information was never retrieved
- Existing detection methods (like removing tokens) can disrupt the semantic structure of the query, making them less effective for complex reasoning
Concrete Example:
In the query 'Who is the director of the film featuring the song Te Deum in D Major and Gloria in D Major?', the dominant condition 'Te Deum' might overshadow 'Gloria'. The LLM then retrieves only about 'Te Deum', misses the 'Gloria' connection, and fails to find the film featuring *both*.
Key Novelty
Iterative Detection and Activation of Overshadowed Knowledge
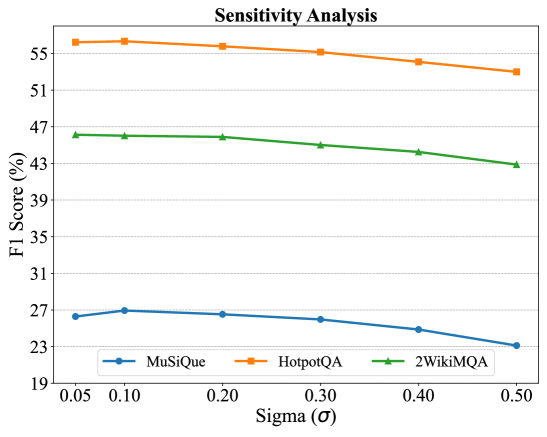
- Detects overshadowed information by adding Gaussian noise to specific keyphrases in the query and measuring how stable the LLM's output is; high stability implies the phrase was ignored (overshadowed)
- Activates this knowledge by training a specialized retriever to find documents relevant to *both* the query and the neglected keyphrase, forcing the model to attend to it
Architecture
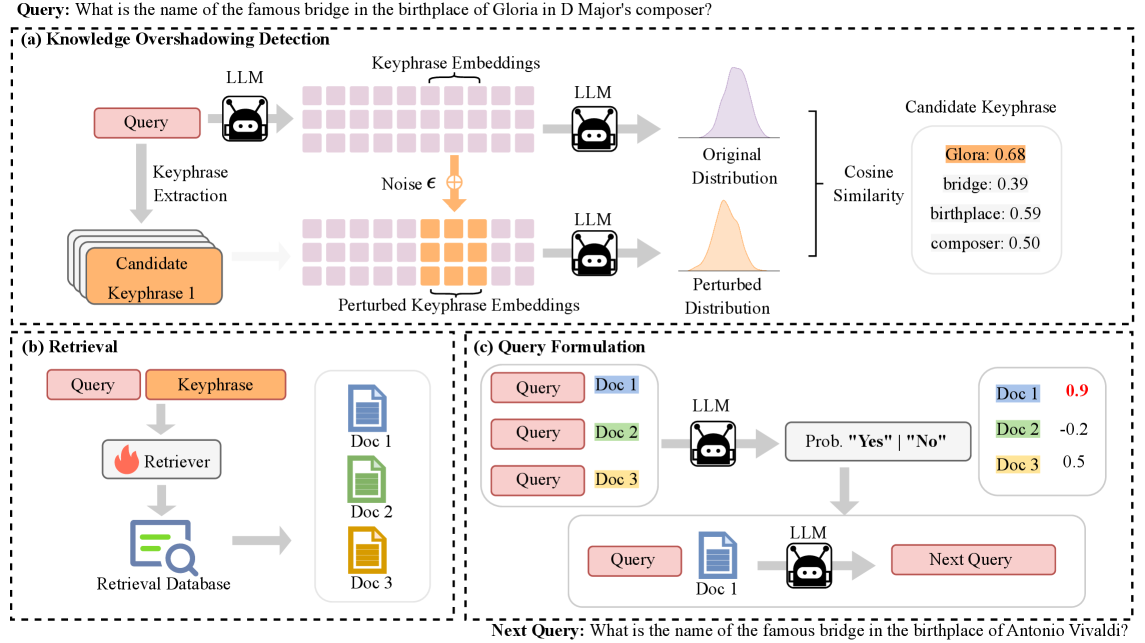
Overview of the ActiShade framework, detailing the iterative process of detection, retrieval, and query formulation.
Evaluation Highlights
- Outperforms state-of-the-art DRAGIN and IRCoT methods across HotpotQA, 2WikiMQA, and MuSiQue datasets on both Llama-3 and Qwen2.5 models
- Achieves higher F1 scores than decomposition-based methods like Self-Ask, suggesting implicit reasoning with targeted retrieval is more effective than explicit sub-question decomposition
- Demonstrates robustness across model sizes, with performance gains scaling from 7B to 14B parameter models
Breakthrough Assessment
7/10
Offers a clever, theoretically grounded perturbation method for detecting hallucinations in reasoning chains. While a solid incremental improvement in RAG, it relies on standard iterative frameworks.