📝 Paper Summary
Memory recall
Sparse memory QA
MoWE decouples model capacity from compute by using a massive number of word-specific experts routed via a static, knowledge-rich vocabulary, effectively acting as an integrated sparse memory.
Core Problem
Dense language models require proportionally more FLOPs to scale parameters for knowledge-intensive tasks, while standard MoEs struggle with routing efficiency and lack semantic specialization in their experts.
Why it matters:
- Increasing parameter count improves world knowledge retention but drastically increases training and inference costs
- Existing memory-augmented models often require complex external retrieval mechanisms (like k-NN search) or specialized training losses
- Standard MoE routing doesn't guarantee that experts specialize in specific concepts, limiting their ability to act as interpretable memory key-value pairs
Concrete Example:
In TriviaQA, answering 'What is Neptune's main satellite?' requires retrieving the specific entity 'Triton'. A standard dense model must process this with all parameters. MoWE routes the token 'Neptune' to a specific expert capable of recalling 'Triton', while skipping irrelevant experts, achieving T5-XXL performance with T5-Large compute.
Key Novelty
Mixture-of-Word-Experts (MoWE)
- Replaces dynamic learned routing with a fixed routing function based on a large 'knowledge-rich' vocabulary (~1M tokens derived from Wikidata/C4)
- Assigns specific words/entities to specific Feed-Forward Network (FFN) experts, encouraging them to act as static key-value memory slots for those concepts
- Uses a hierarchical lookup (Frequency Bucketing + Expert Blocks) to handle massive expert counts (up to 1M) efficiently despite Zipfian word distributions
Architecture
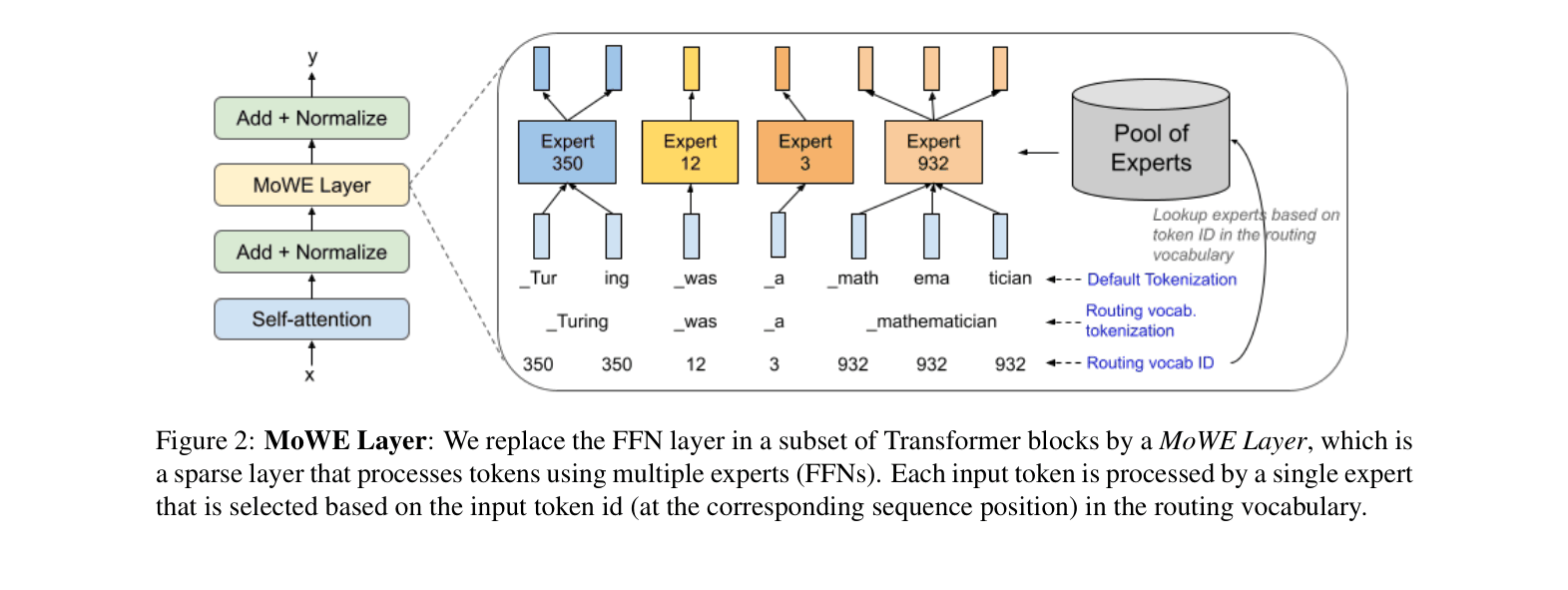
Schematic of the MoWE Layer replacing the FFN layer in Transformer blocks.
Evaluation Highlights
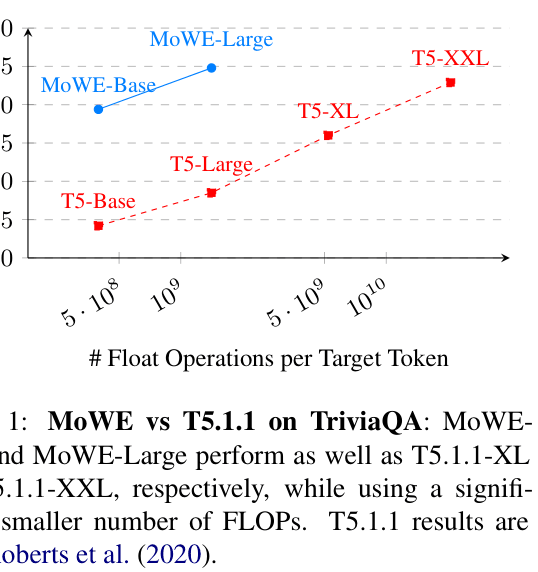
- MoWE-Base outperforms T5-XL on TriviaQA (39.4 vs 36.0 Exact Match) while using ~8.6x fewer FLOPs during training
- MoWE-Large achieves 44.8 EM on TriviaQA, outperforming T5-XXL (42.9 EM) with significantly faster training (6.6x speedup)
- Outperforms standard MoE baselines (GShard Top-2) on knowledge-intensive tasks (e.g., +3.2 EM on TriviaQA vs Top-2 MoE)
Breakthrough Assessment
7/10
Strong empirical results on efficiency vs. performance trade-offs for knowledge tasks. The fixed semantic routing is a clever simplification of MoE, though limited by the static vocabulary constraint.