📝 Paper Summary
Agentic RAG pipeline
RPG is an iterative framework that alternates between generating a high-level plan and retrieving fine-grained evidence to guide long-form text generation, preventing topic drift caused by irrelevant retrieved content.
Core Problem
Standard RAG systems often retrieve entire documents containing off-topic paragraphs, which can mislead LLMs during long generation tasks, causing the model to drift from the main topic.
Why it matters:
- Lengthy retrieved documents often contain irrelevant details that distract the model, leading to factual errors and hallucinations
- Single-step retrieval fails to adapt to the evolving information needs of long-form answers
- Existing dynamic retrieval methods struggle to filter out irrelevant specific details within generally relevant documents
Concrete Example:
When asked 'How do jellyfish function without brains?', a standard RAG model retrieves a document mentioning jellyfish lifespans and bioluminescence. The model gets distracted by these details, generating text about 'illuminating the dark' instead of focusing on the nervous system mechanisms requested by the user.
Key Novelty
Iterative Retrieve-Plan-Generate (RPG) Framework
- Decomposes generation into alternating 'Plan' and 'Answer' stages: the model first predicts a specific sub-topic (Plan), then selects relevant sentences (fine-grained evidence) to generate that section
- Uses a multi-task prompt tuning strategy where a single frozen LLM learns distinct 'Plan' and 'Answer' prompts simultaneously, sharing a soft prompt base but using different low-rank projections
Architecture
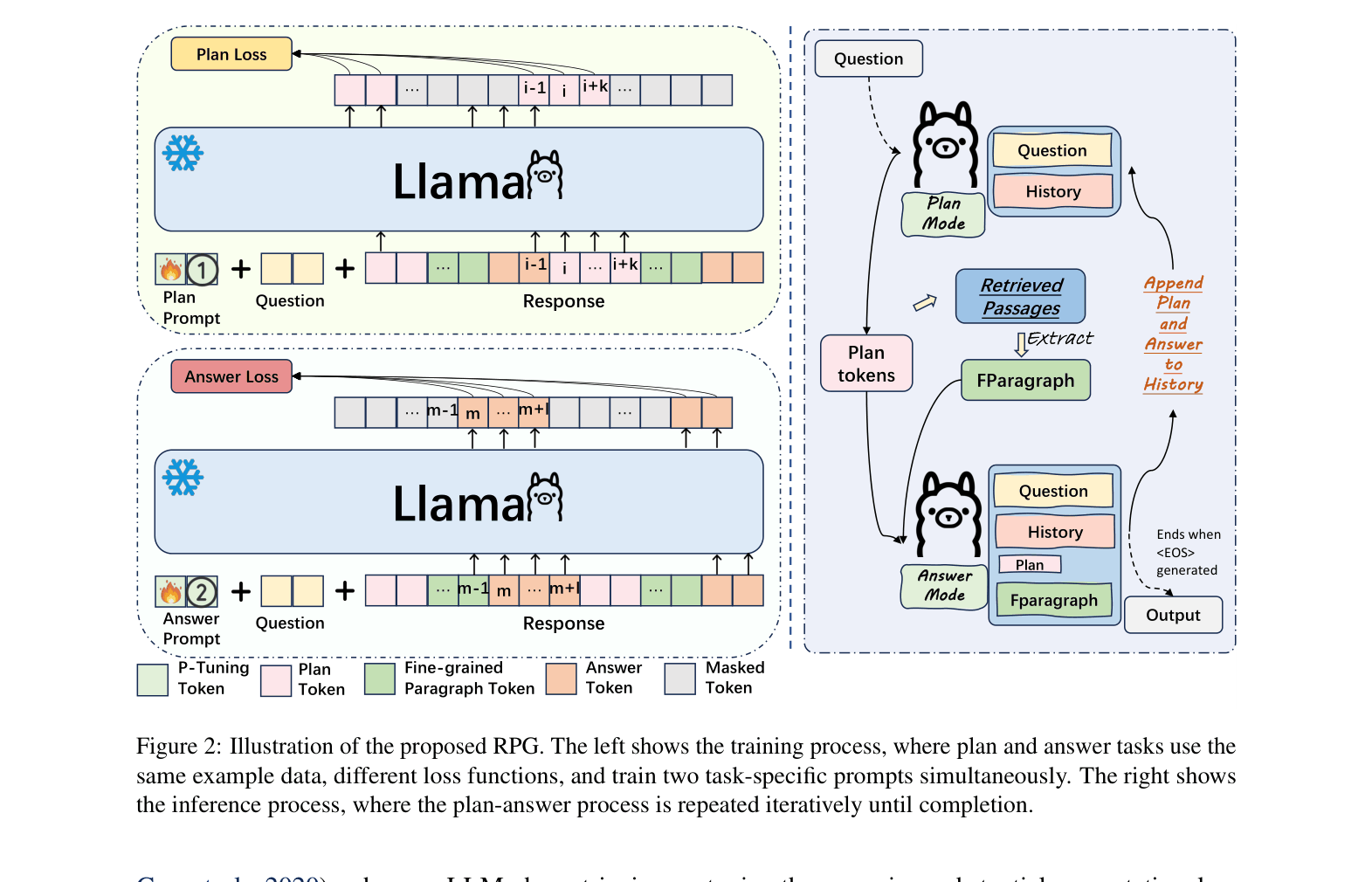
The RPG training and inference pipeline. Left: Training two task-specific prompts (Plan, Answer) using masked losses on the same data. Right: Inference loop alternating between Plan generation, Fine-grained Paragraph selection, and Answer generation.
Evaluation Highlights
- +1.8 to +2.7 ROUGE-L improvement over Self-RAG baseline on ASQA (long-form QA)
- +8.5 F1 score improvement over Self-RAG on 2WikiMultiHopQA (multi-hop reasoning)
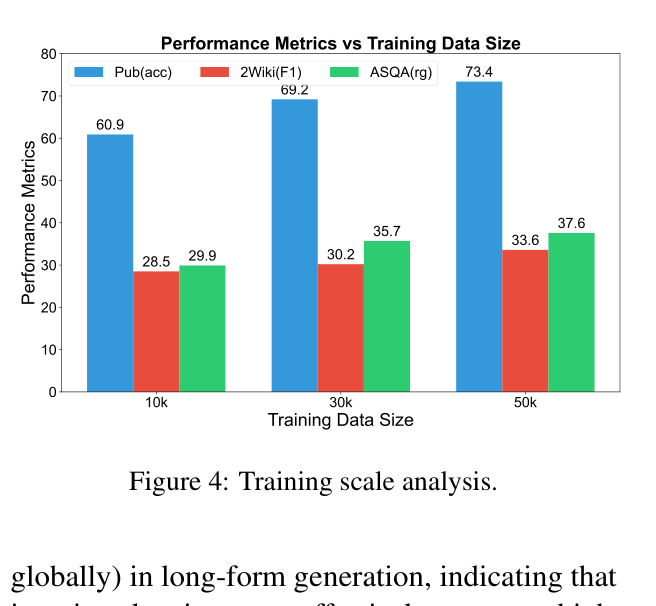
- Generalizes to short-form tasks with +1.0% accuracy on PubHealth compared to Self-RAG
Breakthrough Assessment
7/10
Strong improvements in long-form generation coherence by explicit planning. The multi-task prompt tuning approach is an efficient way to add planning capabilities to frozen LLMs.