📝 Paper Summary
Modularized RAG pipeline
Benchmark datasets
Metrics and evaluation
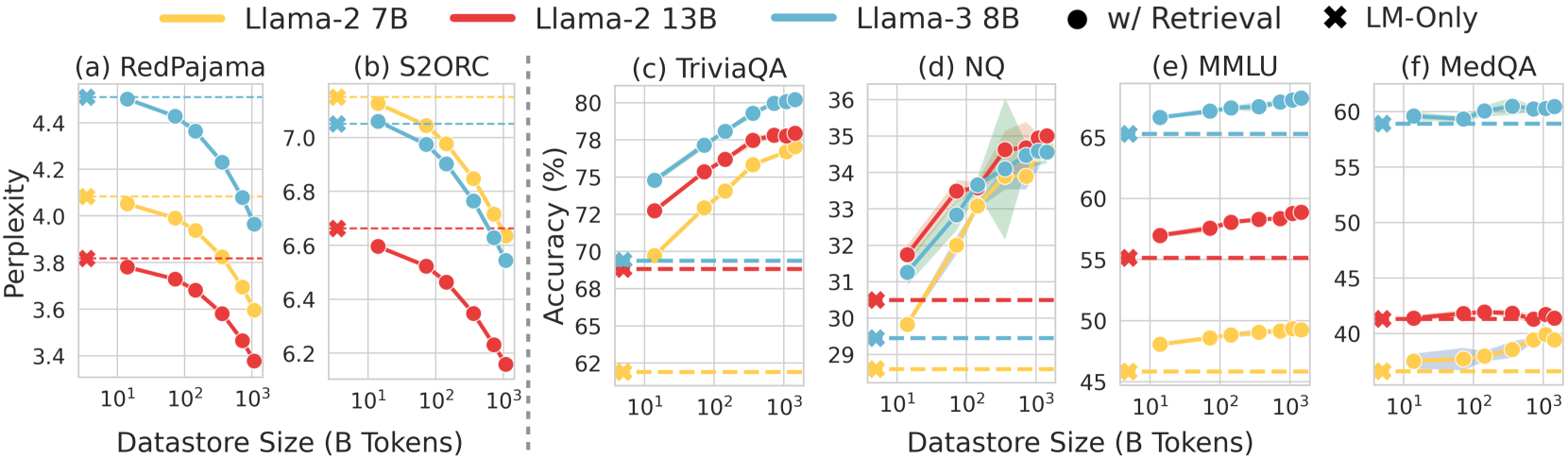
Scaling the inference-time datastore size for retrieval-based language models monotonically improves performance and offers better compute-optimal trade-offs than scaling model parameters or pretraining data alone.
Core Problem
Current scaling laws focus on pretraining data and parameter counts, ignoring inference-time datastore size, while existing large datastores (like RETRO) are proprietary or lack comprehensive downstream evaluation.
Why it matters:
- Training large LMs is prohibitively expensive; finding efficiency gains through retrieval could reduce compute costs
- It is unknown how datastore scaling affects dominant retrieve-in-context approaches across diverse tasks beyond simple language modeling
- Prior open-source datastores are small (Wiki-scale) or lack diverse domain coverage, limiting research on trillion-token retrieval
Concrete Example:
A small Llama-2 7B model using a massive datastore outperforms a larger Llama-2 13B model (without retrieval) on knowledge-intensive tasks like TriviaQA, showing that external memory can substitute for model scale.
Key Novelty
Inference-Time Datastore Scaling Laws
- Treats the size of the retrieval datastore as a primary scaling dimension alongside model size and pretraining data size
- Demonstrates that indexing data for retrieval is more compute-efficient than training on it, allowing smaller models with large datastores to beat larger LM-only models
- Introduces MassiveDS, a 1.4 trillion-token open-source datastore with diverse domains (code, math, science, web), and an efficient pipeline to study scaling without repeated expensive indexing
Architecture
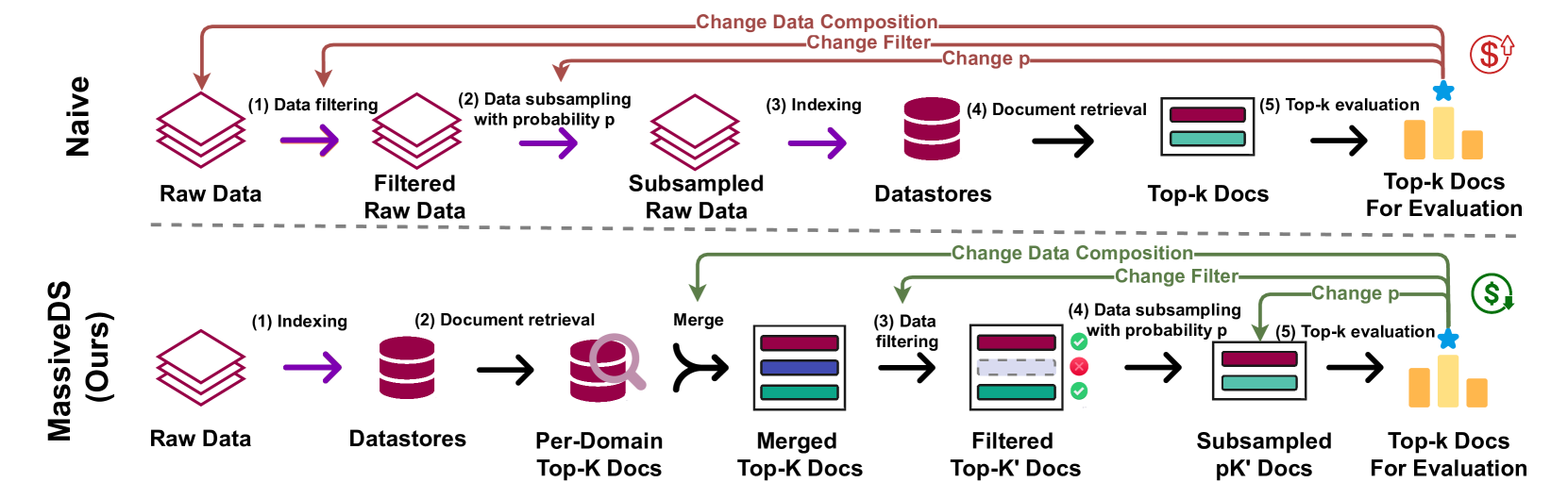
Comparison between the naive datastore scaling pipeline and the proposed efficient MassiveDS pipeline.
Evaluation Highlights
- Llama-2 7B with MassiveDS outperforms the larger Llama-2 13B LM-only baseline on TriviaQA and Natural Questions
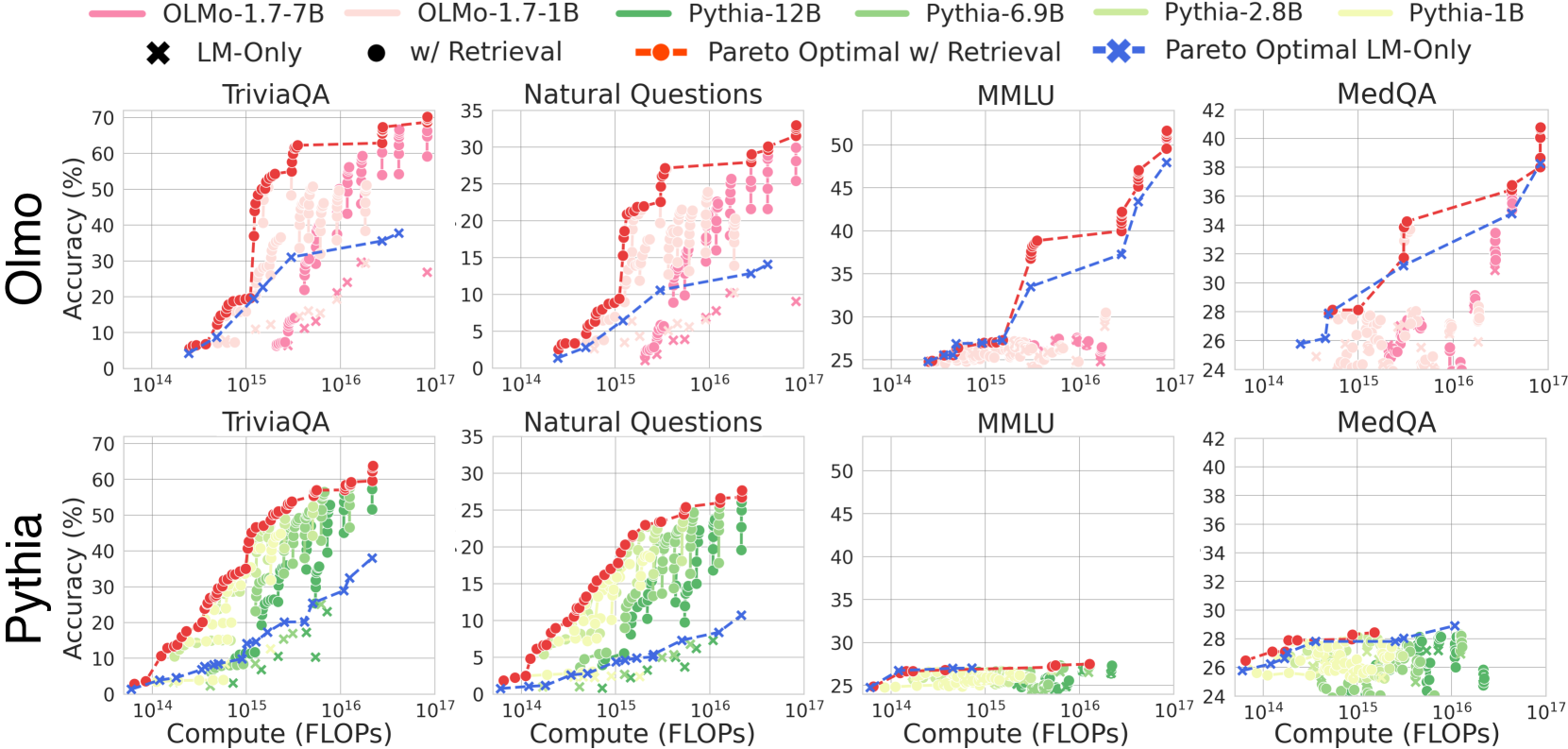
- Retrieval-based LMs achieve better compute-optimal performance than LM-only models, reaching lower perplexity/higher accuracy for the same training FLOPs
- Datastore scaling shows no saturation up to 1.4T tokens for language modeling perplexity and knowledge-intensive QA tasks
Breakthrough Assessment
8/10
Provides the first comprehensive open-source study and dataset (MassiveDS) for trillion-token datastore scaling, establishing new scaling laws for RAG that challenge the 'scale parameters only' paradigm.