📝 Paper Summary
In-Context Learning (ICL)
Passage Ranking
DemoRank improves few-shot passage ranking by retrieving candidate demonstrations and then reranking them using a dependency-aware reranker trained with a novel list-pairwise approach.
Core Problem
Existing demonstration selection methods retrieve examples independently based on relevance, ignoring the critical dependencies between demonstrations in the prompt sequence.
Why it matters:
- In passage ranking, combining diverse demonstrations (e.g., opposite labels, distinct queries) often helps the LLM understand relevance better than just stacking high-confidence examples.
- Choosing demonstrations independently leads to redundancy and suboptimal k-shot prompts.
- Identifying the optimal permutation of k demonstrations is an NP-hard problem, making it difficult to generate training data for selection models.
Concrete Example:
When ranking a relevant query-passage pair, standard retrievers might select two positive demonstrations with similar queries. However, pairing one positive example with a negative example (having opposite outputs) provides richer signals about the decision boundary, which independent selection misses.
Key Novelty
Dependency-Aware Demonstration Reranking (DemoRank)
- Transforms demonstration selection into a 'retrieve-then-rerank' pipeline: first retrieve candidates, then iteratively rerank them to build a sequence.
- Approximates the optimal demonstration sequence via an iterative search (scoring lists that differ only in the last item) to create training data efficiently.
- Uses a list-pairwise training objective where the model learns to choose the best 'next' demonstration given the context of previously selected ones.
Architecture
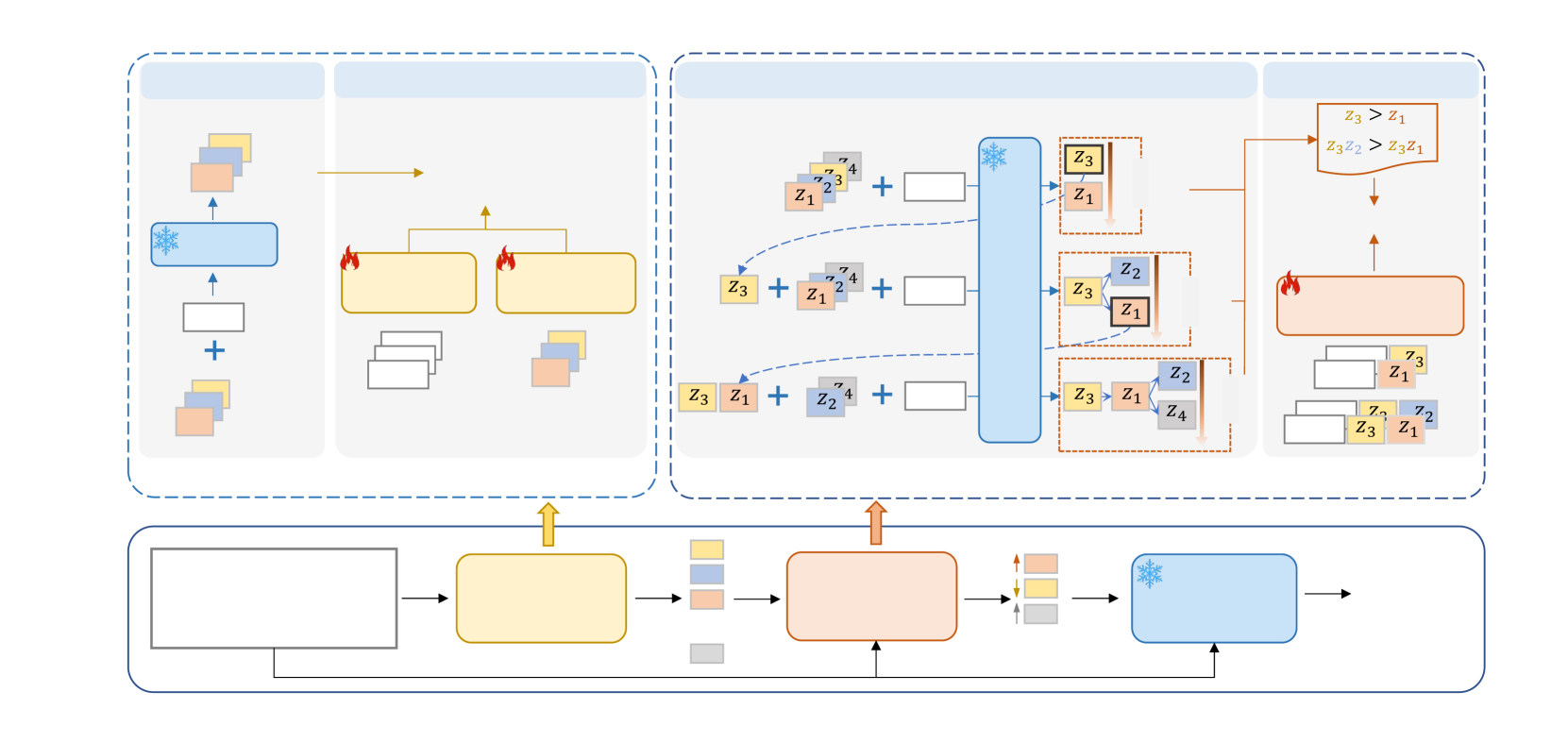
The DemoRank framework pipeline, illustrating the two-stage process: Demonstration Retrieval followed by Dependency-Aware Reranking.
Evaluation Highlights
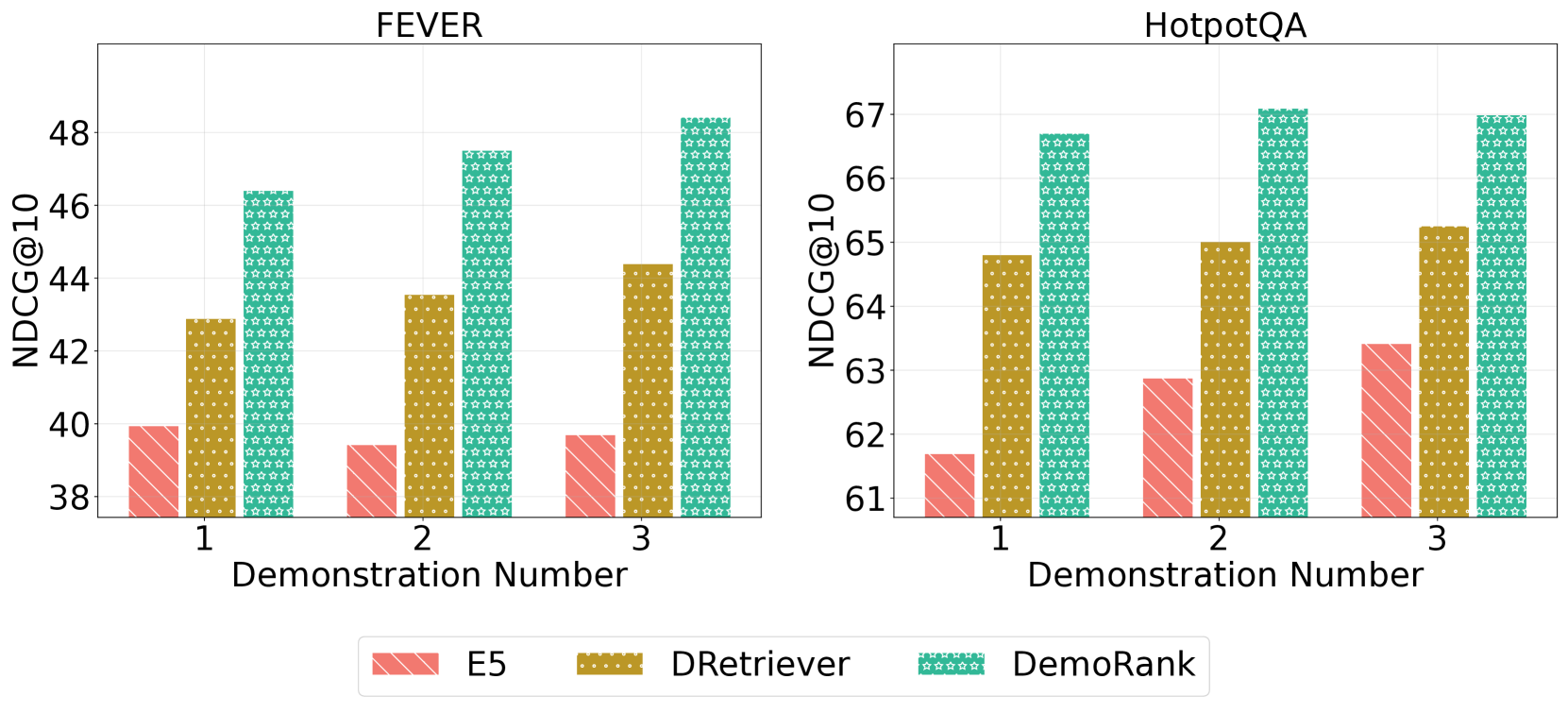
- Outperforms state-of-the-art baselines like EPR and UDR on MS MARCO and TREC benchmarks, achieving 75.33 NDCG@10 on MS MARCO (dev).
- Achieves significant gains in few-shot settings; for example, on TREC-DL 2019, DemoRank reaches 74.00 NDCG@10 compared to 71.85 for UDR.
- Demonstrates strong transferability across different LLM rankers (e.g., testing on LLaMA-2-13B with a reranker trained for LLaMA-2-7B).
Breakthrough Assessment
7/10
Novel formulation of demonstration selection as a sequential reranking problem with a clever approximation for generating training data. Strong empirical results on standard benchmarks.