📝 Paper Summary
LLM Evaluation
Emotion Analysis
Model Calibration
Large language models struggle to capture human annotation disagreement in emotion analysis without supervised fine-tuning, but their distributional alignment can be improved through lightweight post-hoc calibration.
Core Problem
Human annotators frequently disagree on emotion labels due to genuine interpretive differences, but standard Large Language Model (LLM) evaluations collapse these distributions into a single majority label, obscuring whether models actually capture human uncertainty.
Why it matters:
- Discarding annotator disagreement masks critical differences in emotional perception, cultural background, and text ambiguity
- Prior work evaluating LLMs as annotators primarily tests majority-vote accuracy, ignoring the structural nuances of Human Label Variation (HLV)
Concrete Example:
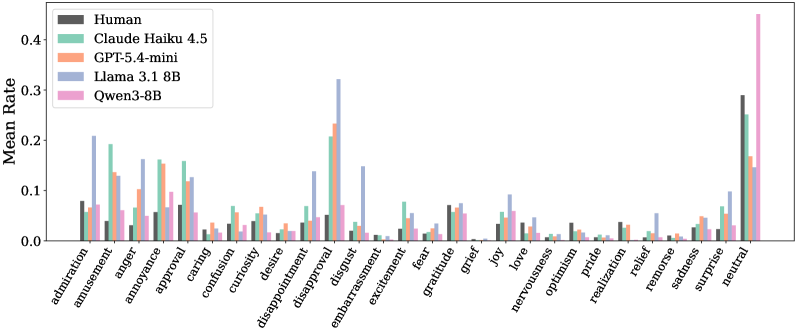
A sarcastic Reddit comment may be judged as amusement, annoyance, and neutral by different human annotators. Zero-shot LLMs systematically fail to capture this uncertainty spread, instead collapsing predictions toward specific biases like negative emotions.
Key Novelty
Distributional evaluation and lexical transparency profiling for LLM emotion annotation
- Treats both human judgments (from multiple annotators) and LLM outputs (via temperature sampling) as full probability distributions for direct structural comparison
- Introduces a lexical transparency score that predicts which emotion categories an LLM can reliably annotate based on explicit lexical markers
Architecture
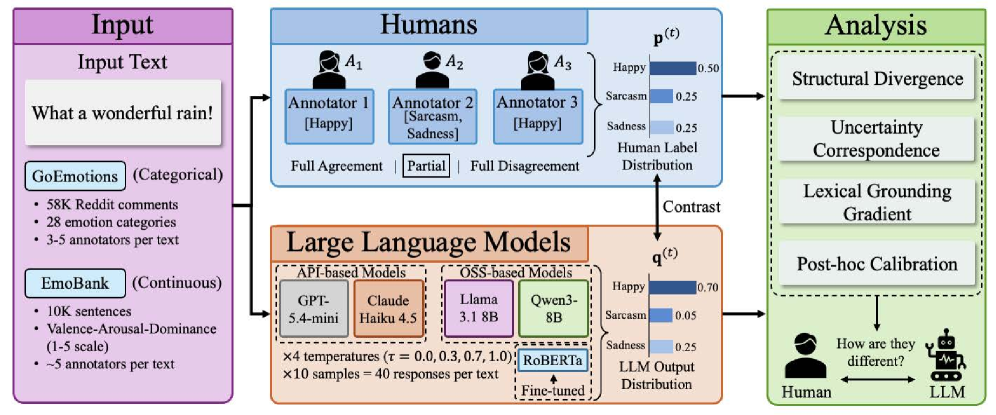
The overall evaluation pipeline comparing human annotations and LLM outputs as probability distributions over emotion categories.
Evaluation Highlights
- Zero-shot LLMs show substantial divergence from human distributions, with Jensen-Shannon Divergence (JSD) greater than 0.45 on the GoEmotions benchmark
- In-domain fine-tuned RoBERTa achieves roughly half the distributional gap of the best zero-shot LLMs
- Post-hoc calibration via isotonic regression reduces the human-LLM distributional gap by up to 14% across models
Breakthrough Assessment
7/10
Provides a strong framework for evaluating LLM uncertainty against human disagreement, verifying that current zero-shot models fundamentally lack human-like nuance while offering practical calibration fixes.