📝 Paper Summary
Vision-Language-Action (VLA) models
Goal-Conditioned Reinforcement Learning
Robotic Foundation Models
PRTS reformulates VLA pretraining using goal-conditioned contrastive reinforcement learning, enabling models to learn goal-reachability awareness directly from offline trajectories without requiring explicit reward annotations.
Core Problem
Existing Vision-Language-Action (VLA) models pretrain almost exclusively via supervised behavior cloning, which teaches static semantic understanding but fails to capture the temporal, goal-reaching nature of robotic trajectories.
Why it matters:
- Robotic execution is inherently a goal-reaching process over time, requiring temporal awareness of how close the current state is to the objective
- Without quantitative goal-reachability awareness, models cannot evaluate execution difficulty or distinguish difficult-yet-reachable states from easy-yet-erroneous ones
- Prior value-augmented approaches require costly manual reward annotations, curated pairwise progress labels, or auxiliary value networks that double training costs
Concrete Example:
When an agent is trained purely on behavior cloning, it only learns 'what to do' (semantic reasoning). If it encounters a state slightly off the optimal path, it lacks a quantitative estimate of 'how likely it is to still reach the goal.' In contrast, PRTS learns a unified embedding space where the inner product of state-action and goal embeddings explicitly estimates this probability, guiding more robust task execution.
Key Novelty
Goal-Conditioned Contrastive Representation Learning for VLAs
- Treats language instructions as shared goals across a trajectory, using a temporal weighting scheme to emulate the geometric sampling used in standard contrastive reinforcement learning
- Appends specialized token blocks evaluated with a custom role-aware causal mask to compute goal reachability and predict actions simultaneously in a single forward pass
- Extracts dense goal-reachability supervision directly from trajectory data without any manual reward labels, folding value-based planning directly into the vision-language backbone
Architecture
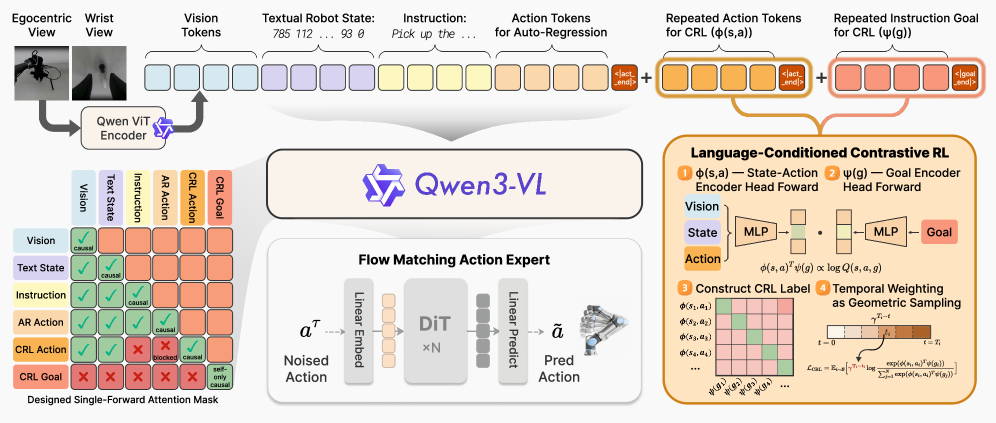
The unified VLA architecture combining Auto-Regressive token generation and Contrastive Reinforcement Learning in a single forward pass using a structurally sparse role-aware attention mask
Breakthrough Assessment
8/10
Offers a highly efficient, single-forward-pass integration of goal-conditioned contrastive reinforcement learning into VLM pretraining, bypassing the need for explicit reward labels while demonstrably improving long-horizon reasoning.