📝 Paper Summary
Data Discovery
Table Representation Learning
TabSketchFM pretrains a transformer model using statistical sketches (MinHash, numeric distributions) rather than raw cell values to overcome token limits and improve numerical representation for data discovery tasks.
Core Problem
Existing tabular models treat table cells as text sequences, which fails for large tables due to token limits and loses numerical semantics, hindering discovery tasks like finding joinable or unionable tables.
Why it matters:
- Enterprises need to discover related tables (joins, unions, subsets) in massive data lakes for analytics and governance.
- Current encoder-only models (e.g., BERT) have severe context limits (512 tokens), forcing truncation that discards critical table content.
- Treating numbers as text tokens ignores their statistical properties, leading to poor matching of numerical columns.
Concrete Example:
A column named 'Age' is ambiguous; it could refer to people or buildings. Values distinguish them (e.g., 20-80 vs. 100-500). Standard LMs truncating after 512 tokens might miss these values, whereas TabSketchFM's numerical sketch (capturing min, max, mean) instantly differentiates them.
Key Novelty
Sketch-based Tabular Foundation Model (TabSketchFM)
- Replaces raw cell values with compact 'sketches' (MinHash for sets, statistical vectors for numbers) as inputs to the transformer, bypassing token length limits.
- Uses a novel embedding summation strategy that combines token, position, column type, and sketch embeddings (MinHash/Numeric) to represent table columns.
- Augments tabular structural embeddings with off-the-shelf sentence embeddings (SBERT) during search to capture semantic meaning when value overlap is unnecessary (e.g., Union search).
Architecture
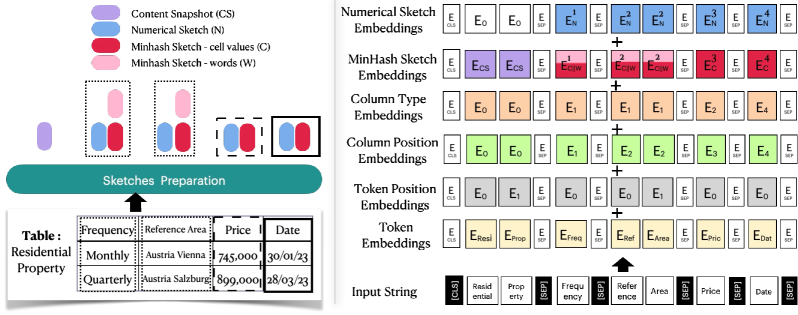
Left: Sketch generation process (Content Snapshot, MinHash, Numerical). Right: TabSketchFM input embedding architecture showing how sketches are projected and summed with token embeddings.
Evaluation Highlights
- Outperforms state-of-the-art neural and traditional methods by up to 70% in F1 scores for search tasks.
- Fine-tuned models improve over previous tabular neural models by up to 55% in F1 on data discovery benchmarks.
- Ablation reveals MinHash sketches are crucial for join search (value overlap), while numerical sketches are essential for subset search.
Breakthrough Assessment
7/10
Significant practical improvement for data discovery by solving the token-limit bottleneck via sketching. The finding that simple sentence embeddings outperform complex models for Union search is a valuable negative result.