📝 Paper Summary
Continual Pre-training (CPT)
Scaling Laws
Data Mixture Ratios
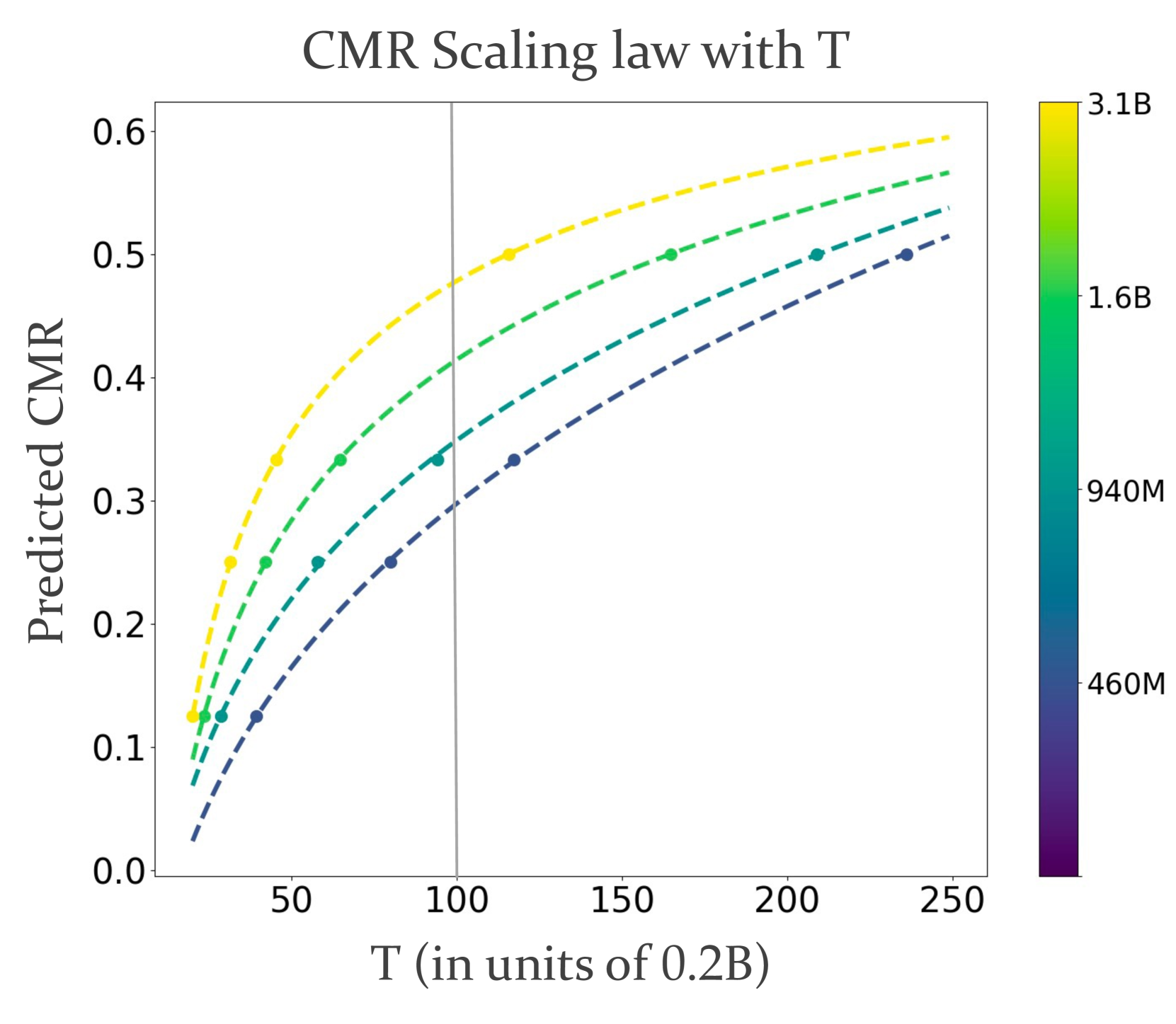
The paper identifies a power-law relationship in continual pre-training that predicts the Critical Mixture Ratio (CMR)—the maximum proportion of domain data a model can ingest without degrading general performance.
Core Problem
Current continual pre-training (CPT) practices use heuristic data mixture ratios, leading to either inefficient domain adaptation (too little domain data) or catastrophic forgetting (too much domain data).
Why it matters:
- LLMs often underperform in specialized fields (law, medicine) due to limited domain knowledge
- Heuristic data mixtures waste compute by failing to strike the right balance between learning new information and retaining general capabilities
- Retraining from scratch is prohibitively expensive, making efficient CPT crucial for domain transfer
Concrete Example:
A 940M model trained with a 1/3 domain mixture ratio maintains general performance, while a smaller model collapses under the same ratio, showing that optimal mixtures depend on scale and are not universal constants.
Key Novelty
CMR Scaling Law for Continual Pre-training
- Formalizes the CPT trade-off as a constrained optimization problem: minimize domain loss while keeping general loss bounded
- Defines Critical Mixture Ratio (CMR) as the maximum feasible ratio of domain data before general capabilities degrade beyond a tolerance threshold
- Discovers a power-law relationship linking loss, mixture ratio, and training tokens, allowing prediction of the optimal CMR for larger scales using smaller experiments
Architecture
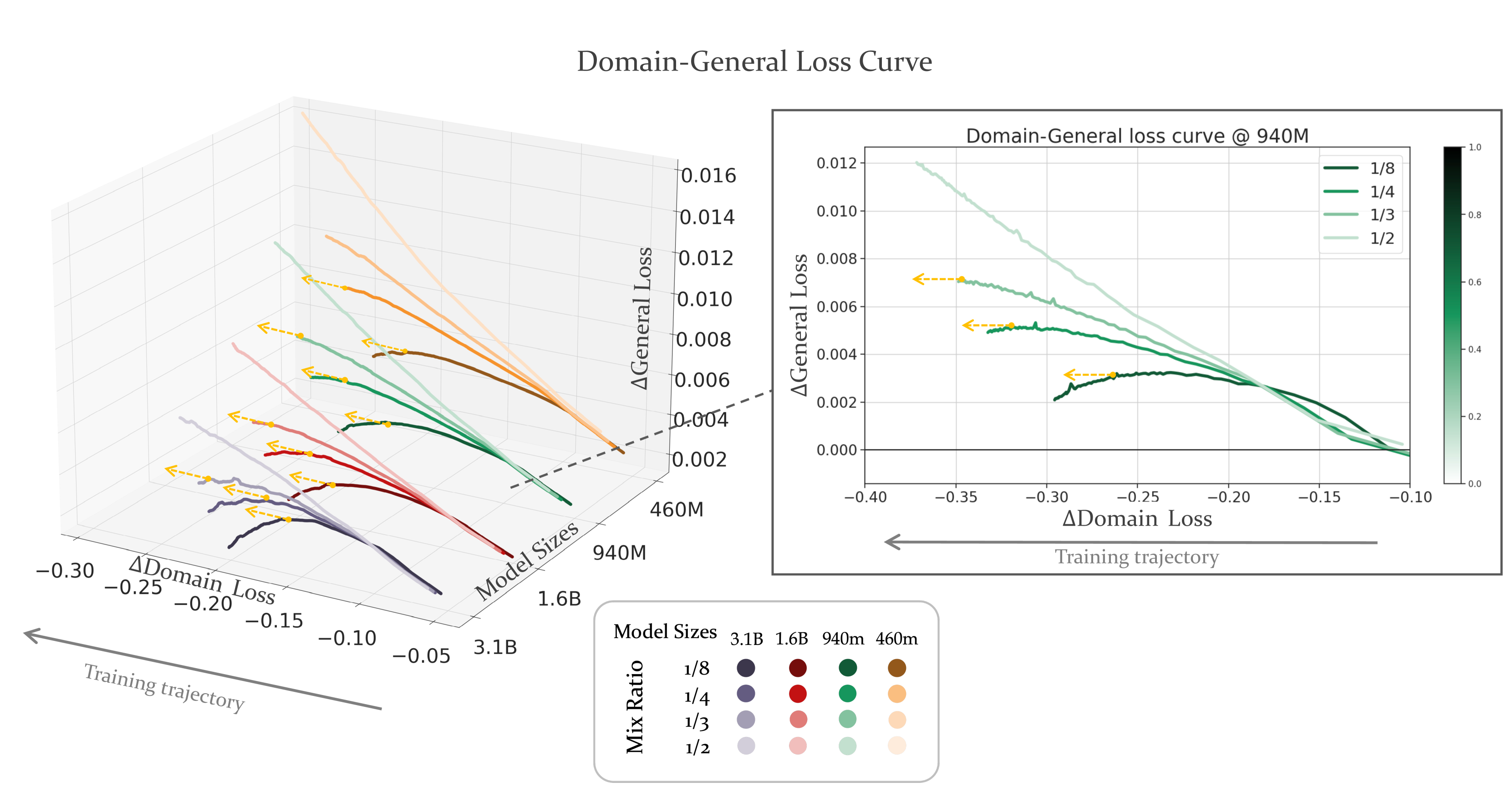
3D plots illustrating the trade-off between General Loss and Domain Loss across different Mixture Ratios and Training Steps
Evaluation Highlights
- CMR increases with model scale: 29.8% for a 460M model vs. 34.9% for a 940M model on Finance data
- CMR is higher for domains closer to pre-training distribution: 460M model tolerates 36.7% for Academic Papers vs. only 29.8% for Finance
- Verified across model sizes from 460M to 3.1B parameters, demonstrating consistent scaling behavior
Breakthrough Assessment
7/10
Provides a principled, predictable scaling law for a previously heuristic hyperparameter (data mixture). While limited to CPT, it offers significant practical value for efficient domain adaptation.