📝 Paper Summary
Knowledge Reasoning
Knowledge Graph reasoning in LLMs
Chain-of-Knowledge (CoK) enhances LLM reasoning by constructing a rule-based dataset from Knowledge Graphs and training models via a trial-and-error mechanism to simulate human-like internal knowledge exploration.
Core Problem
LLMs often struggle with multi-hop knowledge reasoning and suffer from 'rule overfitting' where they memorize reasoning patterns (rules) without verifying if the necessary supporting facts are actually present in their internal knowledge.
Why it matters:
- Current LLMs hallucinate by blindly applying learned rules even when premises are missing
- Knowledge reasoning (deriving new facts from existing ones) is a critical capability underexplored in LLMs compared to KGs
- Behavior cloning on reasoning paths leads to path dependency rather than true exploration
Concrete Example:
If a model learns the rule 'LiveIn(X,Y) <- WorkFor(X,Z) ^ LocateIn(Z,Y)', it might incorrectly conclude a person lives in a city just because they work for a company there, even if the model doesn't actually 'know' the company's location, leading to hallucinated reasoning.
Key Novelty
Chain-of-Knowledge (CoK) Framework
- Mines compositional logical rules (e.g., A implies B if C) from Knowledge Graphs and converts them into natural language reasoning chains
- Introduces a 'trial-and-error' training mechanism where a symbolic agent guides the LLM to explore different reasoning paths, backtracking when internal knowledge is missing, rather than blindly following a single path
Architecture
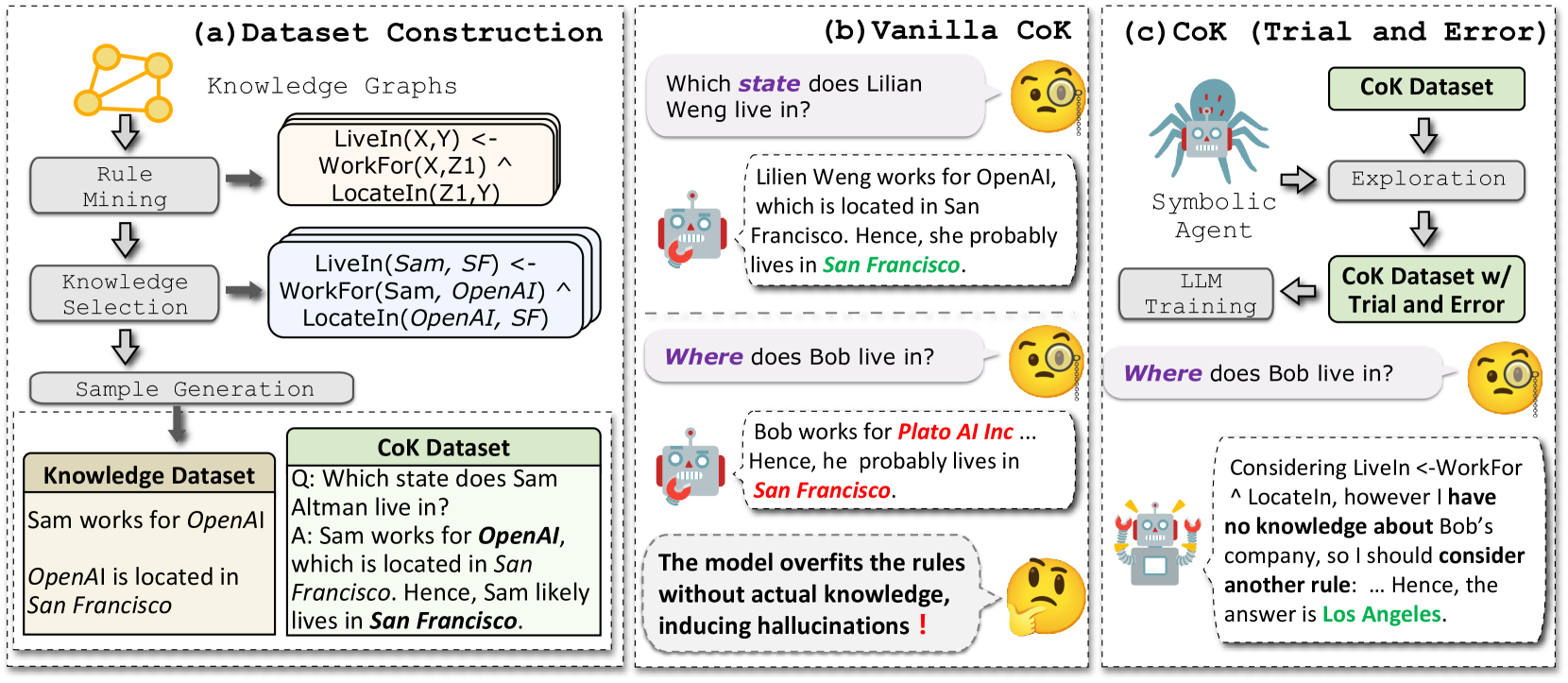
The CoK framework pipeline: Rule Mining -> Knowledge Selection -> Sample Generation -> Model Learning.
Evaluation Highlights
- +13.51% accuracy improvement on the KnowReason dataset (regular setting) over standard CoT prompting with Llama3-8B-Instruct
- Consistent improvements across general reasoning benchmarks, including +9.35% on Big-Bench Hard (BBH) compared to standard prompting
- Effectively mitigates rule overfitting: the trial-and-error mechanism improves performance by 10.95% over naive behavior cloning in anonymized settings
Breakthrough Assessment
7/10
Solid methodological contribution in bridging KGs and LLMs. The trial-and-error mechanism addresses a specific failure mode (rule overfitting), and the dataset construction pipeline is rigorous.