📊 Experiments & Results
Evaluation Setup
Zero-shot and few-shot evaluation on multiple-choice QA and reasoning tasks.
Benchmarks:
- MedMCQA-ITA (Biomedical Question Answering) [New]
- MMLU-IT (General Knowledge (Multi-task))
- ARC-IT (Science Reasoning)
- HELLASWAG-IT (Commonsense Reasoning)
Metrics:
- Accuracy (Normalized)
- Loss
- Statistical methodology: Not explicitly reported in the paper
Key Results
| Benchmark | Metric | Baseline | This Paper | Δ |
|---|---|---|---|---|
| Biomedical domain performance shows Igea improving over the general-purpose base model. | ||||
| MedMCQA-ITA (0-shot) | Accuracy | 29.3 | 31.3 | +2.0 |
| General knowledge retention tests show only minor degradation after medical training. | ||||
| MMLU_IT (5-shot) | Average Accuracy | 36.2 | 34.3 | -1.9 |
| HELLASWAG_IT (0-shot) | Accuracy | 51.9 | 49.1 | -2.8 |
| ARC_IT (0-shot) | Accuracy | 26.1 | 28.7 | +2.6 |
| Scaling laws are observed within the Igea family. | ||||
| MedMCQA-ITA (0-shot) | Accuracy | 25.0 | 31.3 | +6.3 |
Experiment Figures
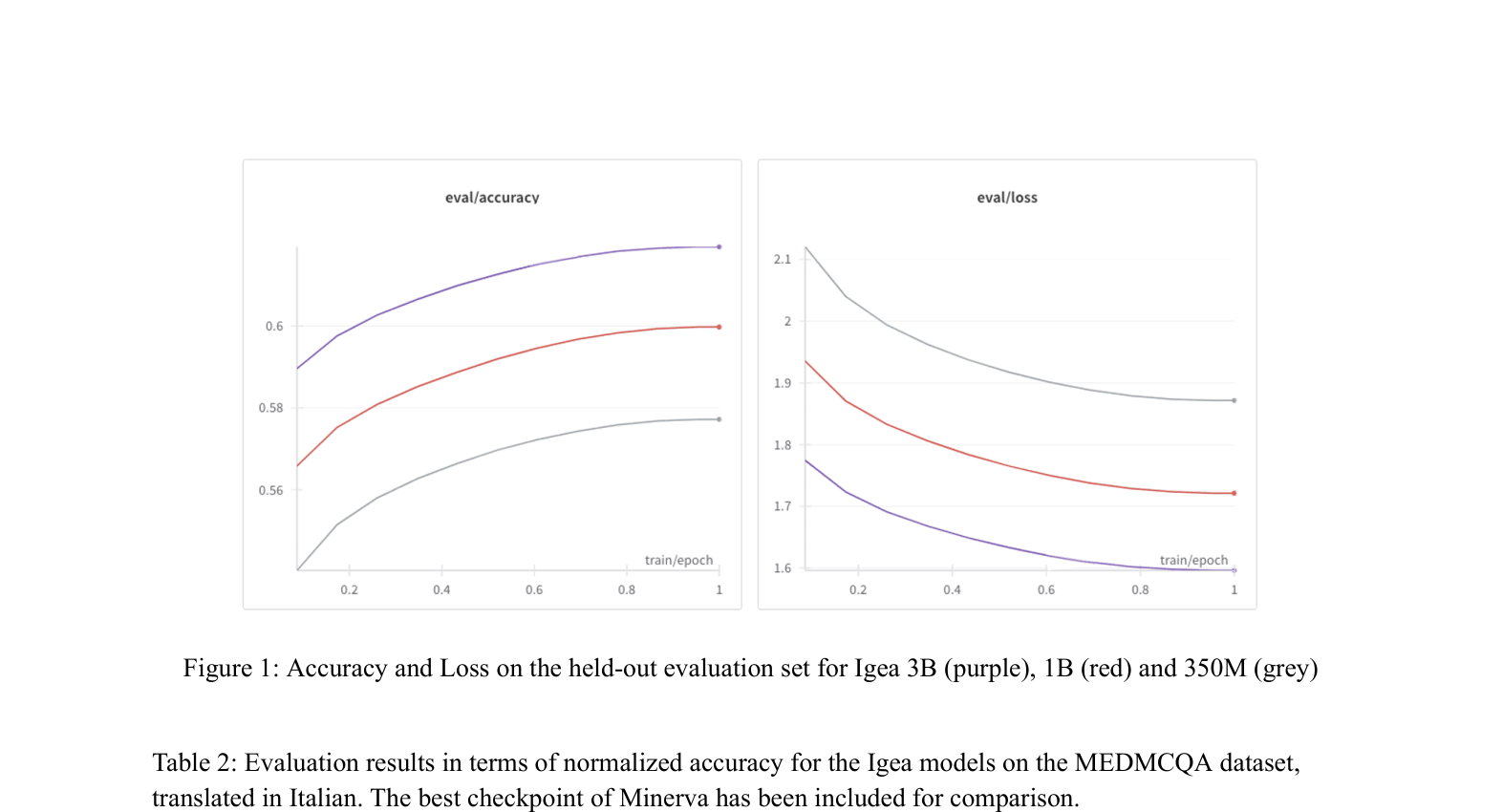
Accuracy and Loss curves on the held-out evaluation set for Igea 3B, 1B, and 350M.
Main Takeaways
- Domain adaptation succeeds: Igea outperforms its base model (Minerva) on the medical task (MedMCQA-ITA).
- Knowledge retention is robust: General benchmarks (MMLU, HELLASWAG) show only minor drops or even improvements (ARC), indicating no severe catastrophic forgetting.
- Model scaling matters: The 3B parameter model consistently outperforms 350M and 1B versions across all tasks.
- The lack of native Italian biomedical benchmarks necessitates translation-based evaluation, which introduces noise (12.5% of training / 47% of eval discarded due to errors).