📝 Paper Summary
Language Model Evaluation
Self-Refinement
Multi-turn Interaction
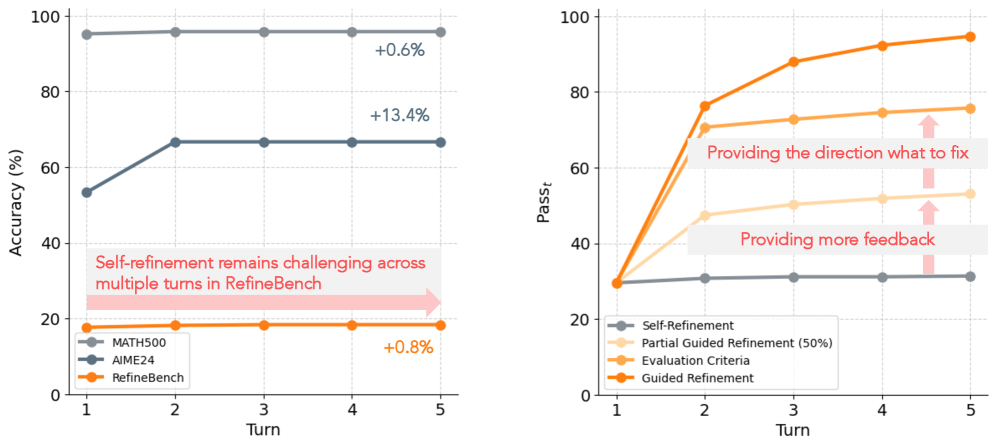
RefineBench reveals that while frontier LMs struggle to self-refine without guidance, they achieve near-perfect performance when provided with specific checklist-based feedback.
Core Problem
It is unclear if language models can effectively refine their own outputs, as prior studies focus on verifiable tasks (math/code) rather than open-ended queries where feedback varies.
Why it matters:
- Real-world user interactions often involve refinement requests (10.24% of WildChat queries), yet models' ability to handle them remains inconsistent
- Existing benchmarks focus on extrinsic critique or short cycles, lacking a unified framework to test both self-refinement and guided refinement across diverse domains
- The emergence of reasoning models (e.g., DeepSeek-R1, o1) necessitates re-evaluating refinement capabilities beyond standard instruction-tuned models
Concrete Example:
Claude-Sonnet-4 successfully refines math problems (AIME24) but fails on RefineBench's open-ended tasks, improving only +0.8% over five turns without feedback, whereas guided feedback boosts performance significantly.
Key Novelty
RefineBench: A Multi-Turn Checklist-Based Refinement Benchmark
- Introduces a unified evaluation framework using checklist items to assess both verifiable (exact match) and non-verifiable (free-form) tasks across 11 domains
- Controls feedback granularity to test three modes: self-refinement (no feedback), guided refinement (specific feedback), and partially guided refinement
- Evaluates refinement as a multi-turn process (5 turns) rather than a single critique-correct step, revealing asymptotic performance limits
Architecture
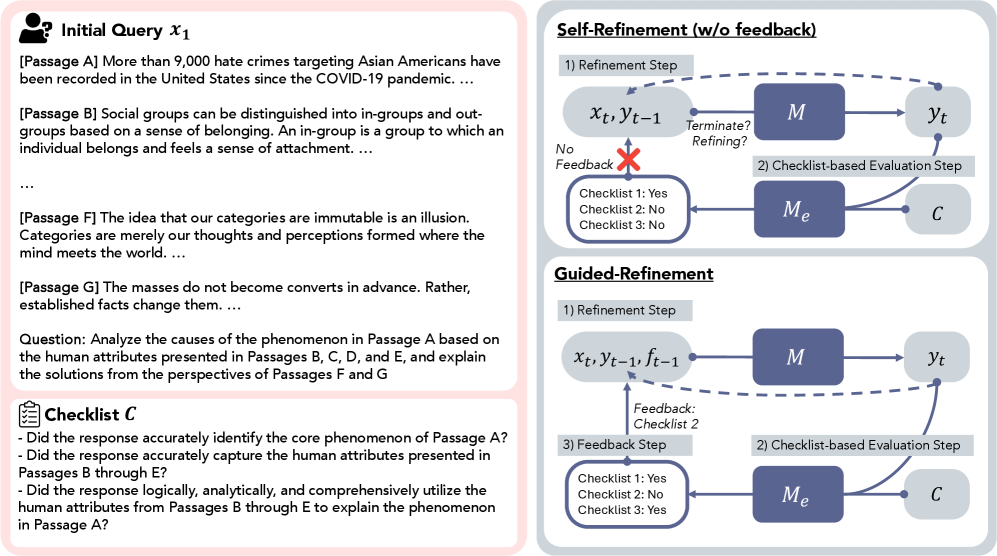
The evaluation protocol for RefineBench, illustrating the loop between the Target LM, Evaluator LM, and Feedback mechanism.
Evaluation Highlights
- In self-refinement (no feedback), frontier LMs stagnate or decline: Gemini-2.5-Pro gains only +1.8%, while DeepSeek-R1 declines by -0.1% over 5 turns
- In guided refinement (feedback provided), models reach near-perfection: Claude-Opus-4.1 improves from ~18% to 98.4% (+79.7%) by turn 5
- Reasoning models (e.g., o1, DeepSeek-R1) generally fail to self-refine effectively on this benchmark, contradicting their success on math-heavy tasks
Breakthrough Assessment
8/10
Provides a definitive, rigorous benchmark that exposes the stark gap between self-refinement hype and reality for open-ended tasks. The checklist methodology offers a reliable automated metric for subjective domains.