📝 Paper Summary
Knowledge Graph-based Recommendation
Reinforcement Learning for Recommendation
CADRL combines a category-aware graph neural network with a dual-agent reinforcement learning framework to efficiently traverse long paths in knowledge graphs for explainable recommendations.
Core Problem
Existing RL-based recommendation methods on Knowledge Graphs fail to capture contextual dependencies from neighboring information and rely excessively on short paths due to efficiency concerns.
Why it matters:
- Short paths (typically limited to 3 hops) restrict the discovery of distant but relevant items, reducing recommendation accuracy.
- Ignoring neighboring entity and category context leads to noisy or incomplete item representations.
- Single-agent RL struggles with the large action spaces inherent in long-path reasoning, leading to sparse rewards and inefficiency.
Concrete Example:
A user might be interested in 'Michael Jordan's Jersey' (5 hops away via 'AJ III' and 'Bulls Shorts'), but a short-path method stops at 'AJ Headband' (3 hops), which is irrelevant. The method fails to see the 'Basketball equipment' category connection.
Key Novelty
Category-aware Dual-Agent Reinforcement Learning (CADRL)
- CGGNN (Category-aware Gated Graph Neural Network): Jointly learns item representations from both neighboring entities (low-noise topology) and neighboring categories (high-order semantics).
- DARL (Dual-Agent Reinforcement Learning): Two collaborative agents traverse the Knowledge Graph; sharing intelligence allows them to navigate long paths efficiently without the action space explosion of single agents.
Architecture
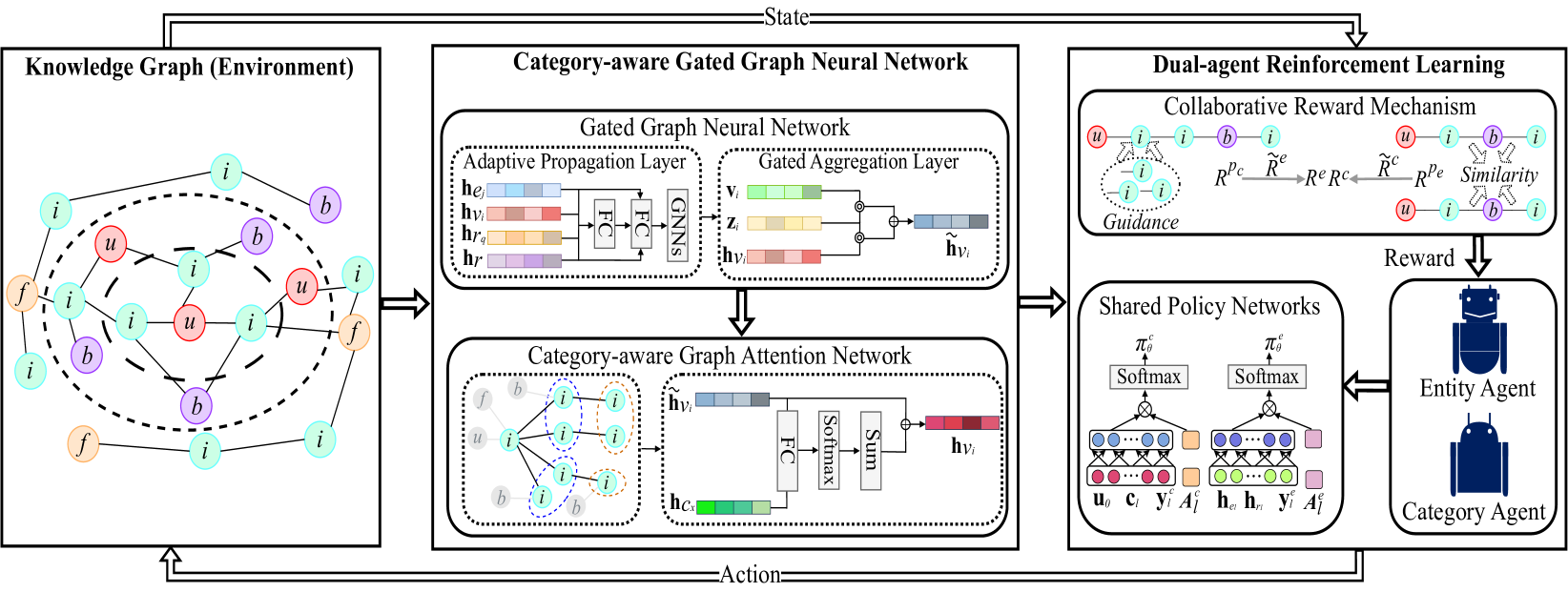
The overall framework of CADRL comprising the CGGNN component and the DARL component.
Evaluation Highlights
- Outperforms state-of-the-art baselines in effectiveness on large-scale datasets.
- Outperforms state-of-the-art baselines in efficiency on large-scale datasets.
- Specific numeric results are not provided in the snippet, but the text claims superiority over PGPR, ADAC, and others.
Breakthrough Assessment
6/10
Proposes a logical evolution (dual-agent RL) to address the specific limitation of path length in KG reasoning. While the architecture seems sound, the provided text lacks specific numeric evidence to validate the magnitude of the improvement.