📝 Paper Summary
Modularized RAG pipeline
Information Gain Pruning (IGP) replaces relevance-based reranking with a generator-aligned utility signal—measured by the reduction in uncertainty (entropy) of the generator's next-token distribution—to filter out weak or harmful evidence before truncation.
Core Problem
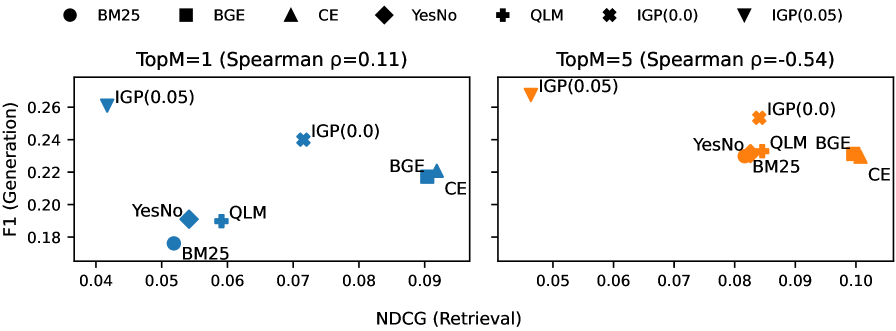
In RAG systems with limited context budgets, standard relevance metrics (e.g., NDCG) often correlate weakly or negatively with end-to-end generation quality because highly relevant documents can introduce redundancy, ambiguity, or conflicts that destabilize the generator.
Why it matters:
- Improving retrieval relevance does not reliably improve answer quality (Relevance-Utility Mismatch).
- Injecting multiple pieces of evidence often introduces noise that consumes budget without adding marginal utility.
- Existing rerankers focus on relevance rather than the generator's actual need for information to resolve uncertainty.
Key Novelty
Generator-Aligned Information Gain Pruning (IGP)
- Define 'Information Gain' (IG) as the reduction in the generator's normalized uncertainty (entropy over Top-K tokens) when conditioned on a candidate passage versus no context.
- Rerank passages by IG and apply a pruning threshold to discard negative-utility or weak-utility passages before the final Top-M truncation.
- The method is label-free, training-free, and parameter-free, relying only on black-box access to step-wise logits.
Architecture
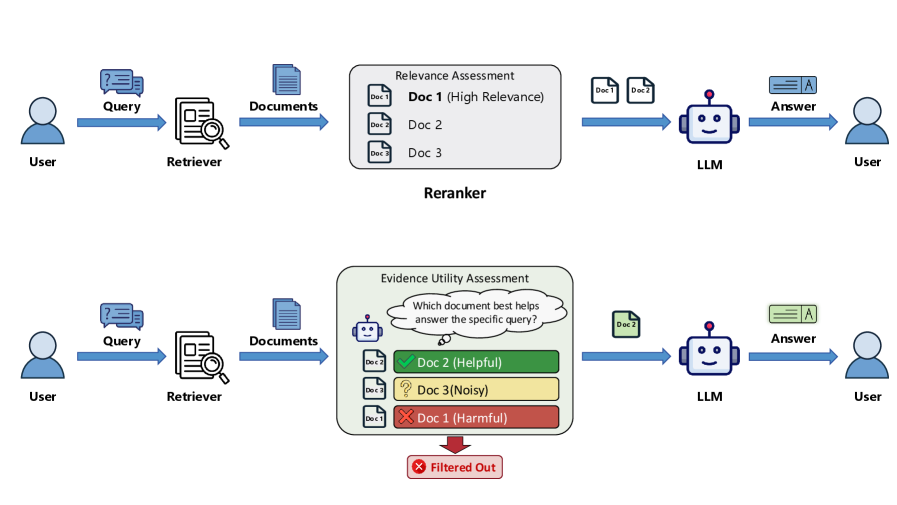
Comparison of standard relevance reranking pipeline versus IGP. IGP introduces an 'Evidence Utility Assessment' step that filters out 'Helpful' vs 'Harmful' docs based on uncertainty reduction.
Evaluation Highlights
- Relevance-Utility Mismatch: On NQ, higher NDCG@5 often correlates with lower F1 (Spearman = -0.54), proving relevance != utility.
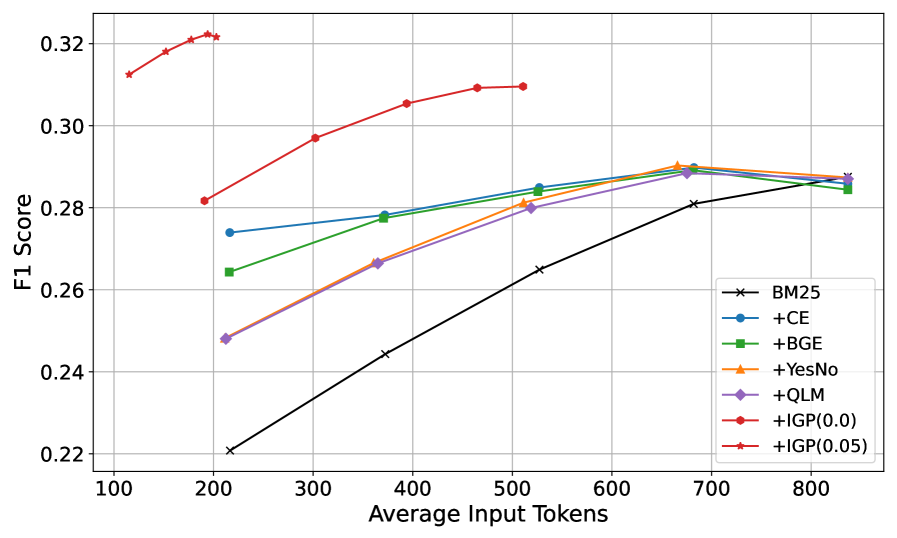
- Multi-evidence (TopM=5) Win-Win: On average across 5 datasets (BM25 retriever), IGP(0.05) improves F1 from ~0.288 (BM25) to ~0.322 while reducing input tokens from ~836 to ~202 (approx. 76% reduction).
- Tight Budget (TopM=1): IGP(0.05) improves average F1 from ~0.221 to ~0.312 compared to BM25 baseline.
- Scale Efficiency: Qwen-1.5B with IGP outperforms Qwen-7B without IGP on NQ (F1 ~0.2 vs ~0.17).
- Robustness: Improvements persist across different retrievers (BM25 vs Contriever) and generator families (Qwen2.5 vs Llama-3.x).
Breakthrough Assessment
7/10
The paper identifies a critical misalignment in standard RAG (relevance vs. utility) and provides a highly practical, training-free solution that significantly improves the cost-quality Pareto frontier. While the core idea of entropy reduction isn't theoretically new, its application as a pre-generation pruning mechanism for RAG is impactful and deployment-friendly.