📝 Paper Summary
Machine Unlearning in Generative Language Models
Privacy and Compliance (GDPR, Right To Be Forgotten)
ICU enables generative models to forget sensitive data by iteratively optimizing an unlearning loss while simultaneously maintaining linguistic capabilities through contrastive learning on analogous, safe text pairs.
Core Problem
Existing unlearning methods either require access to the full original training data (often unavailable) or, when applied to generative models, cause 'model collapse' where general linguistic capabilities are lost.
Why it matters:
- Regulations like GDPR require the 'Right To Be Forgotten,' forcing AI developers to delete specific private data from trained models
- Directly maximizing negative log-likelihood on forget sets often destroys the model's ability to generate coherent text, leading to repetitive or nonsensical outputs
- Retraining large models from scratch for every deletion request is computationally prohibitive
Concrete Example:
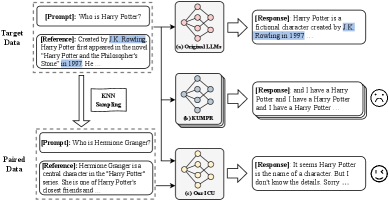
When trying to make a model forget 'Harry Potter' details, a standard unlearning method (KUMPR) causes the model to collapse and repeat 'and I have a Harry Potter' endlessly. ICU successfully forgets the specific facts (e.g., 'J.K. Rowling') while retaining the ability to write grammatically correct sentences about similar topics.
Key Novelty
Iterative Contrastive Unlearning (ICU)
- Constructs an 'Analogous Set' of data related to the forget set but containing different facts, used to anchor the model's general capabilities
- Applies a three-part loss: maximizing error on forget data (unlearning), minimizing error on analogous data (learning), and minimizing KL divergence from the original model (stability)
- Iteratively updates the forget set by removing samples that are successfully forgotten based on dynamic thresholds, preventing over-unlearning
Architecture
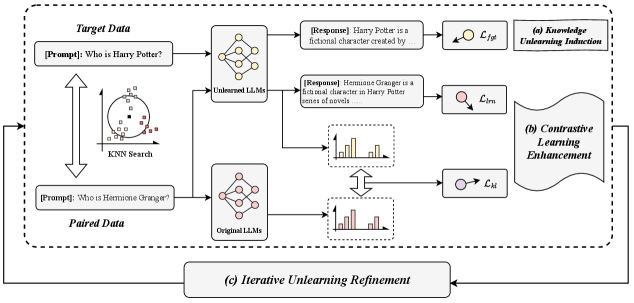
The ICU framework pipeline showing the three main modules: Knowledge Unlearning Induction, Contrastive Learning Enhancement, and Iterative Unlearning Refinement.
Evaluation Highlights
- Achieves best normalized score (0.64) balancing unlearning and performance on GPT-Neo 1.3B, surpassing the KUMPR baseline (-0.37)
- Maintains low perplexity (16.20 on Pile-val) comparable to the original model (16.03), whereas KUMPR degrades to 41.76
- Effective unlearning: Extraction Likelihood drops from 0.40 (Original) to 0.04, matching the dedicated unlearning baseline KUMPR (0.04)
Breakthrough Assessment
7/10
Offers a practical, effective solution for the 'model collapse' problem in unlearning without needing original training data. Strong empirical results on balancing forgetting vs. utility.