📝 Paper Summary
Agentic RAG pipeline
Reasoning-search interleaved agents
Reinforcement Learning for RAG
REX-RAG improves reinforcement learning for retrieval-augmented generation by using a mixed sampling strategy to escape reasoning dead ends, coupled with importance sampling to correct the resulting policy gradient bias.
Core Problem
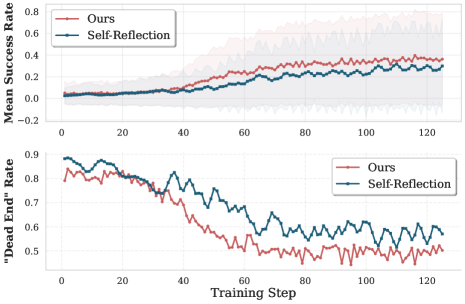
During RL training, LLMs frequently get trapped in 'dead ends'—reasoning paths where the model consistently reaches incorrect conclusions across all rollouts due to premature or overconfident decisions.
Why it matters:
- Dead ends affect over 85% of training instances in early RL phases, severely hampering exploration and policy optimization
- Existing self-reflection methods often produce only slight perturbations of the original failed path, failing to provide the diversity needed to escape local optima
- Aggressive exploration strategies (like multi-agent systems) often break the end-to-end optimization paradigm or introduce instability
Concrete Example:
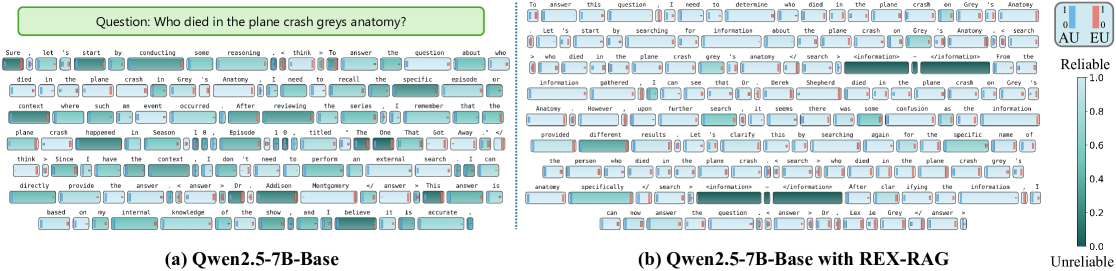
In a multi-hop question, an LLM might prematurely conclude an answer after retrieving only partial evidence. Self-reflection typically generates a similar reasoning chain that reaches the same wrong conclusion. REX-RAG injects a specific 'hint' prompt to force a different retrieval angle, breaking the loop.
Key Novelty
Mixed Sampling with Policy Correction for RL-RAG
- Combines the target policy with an exploratory 'probe policy' that injects diverse chain-of-thought prompts when the model hits a dead end (incorrect answer)
- Applies a Policy Correction Mechanism using multiple importance sampling to mathematically correct the distribution shift caused by using the probe policy, ensuring the gradient remains unbiased
Architecture
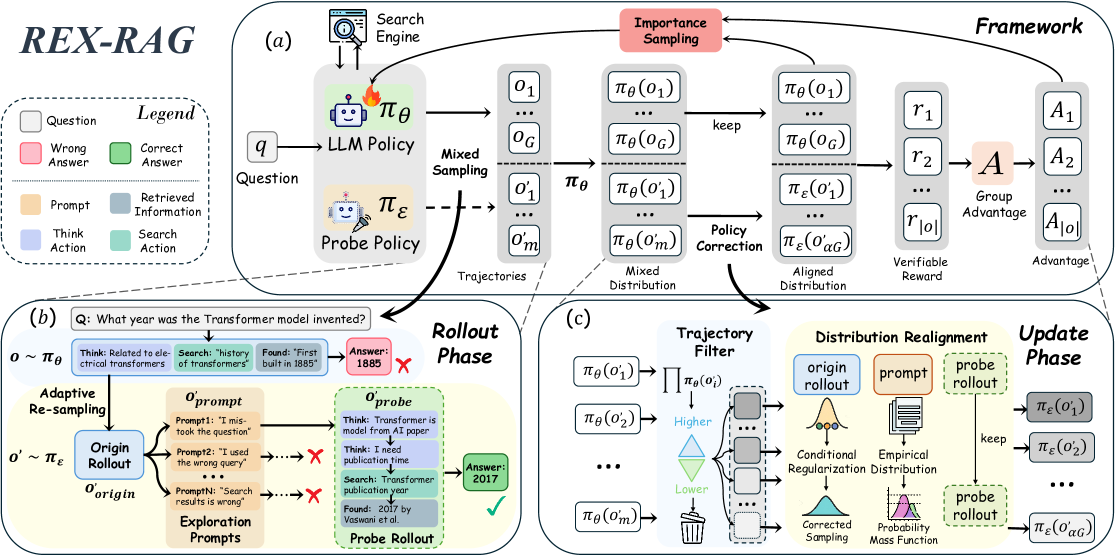
The REX-RAG training framework, illustrating the two main phases: Rollout Phase with Mixed Sampling and Update Phase with Policy Correction.
Evaluation Highlights
- +5.1% average improvement on Qwen2.5-3B and +3.6% on Qwen2.5-7B over the strong Search-R1 baseline across seven benchmarks
- +8.7% improvement on 2WikiMultiHopQA (multi-hop reasoning) using Qwen2.5-3B, demonstrating effectiveness in complex reasoning tasks
- Achieves 13.2% higher average performance than the best non-fine-tuned RAG method on 3B models
Breakthrough Assessment
8/10
Addresses a fundamental stability issue in RL for reasoning (exploration vs. bias) with a theoretically grounded correction mechanism. Shows significant gains on standard benchmarks.