📝 Paper Summary
Self-Improving LLMs
RLHF / Preference Optimization
LLM-as-a-Judge
Meta-Rewarding improves language models by adding a meta-judge role that evaluates the model's own judgments, creating preference data to train the judge alongside the actor.
Core Problem
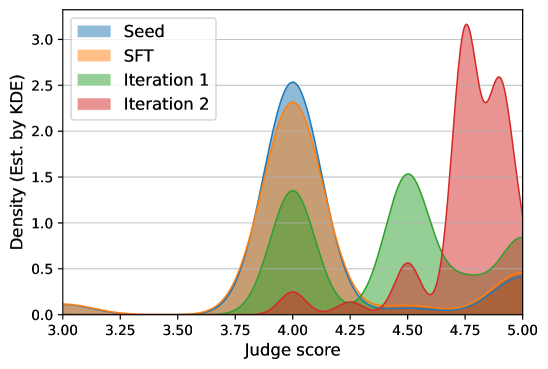
Existing self-rewarding methods improve the model's acting ability but neglect its judging ability, causing the judge to saturate or become susceptible to reward hacking.
Why it matters:
- If the judge's quality stagnates, the actor's improvement saturates quickly during iterative training
- Reliance on human data for training reward models is costly and unscalable ('Super Alignment' challenge)
- Models tend to 'reward hack' by generating longer responses rather than better ones (length bias)
Concrete Example:
In standard self-rewarding loops, a model might learn to generate verbose responses because its internal judge mistakenly favors length. Without a mechanism to correct the judge, the model just gets wordier without getting smarter.
Key Novelty
Meta-Rewarding (Judge-the-Judge)
- Introduce a third role, 'meta-judge', which evaluates the quality of the model's own judgments (acting as a judge)
- Use this meta-judge to create preference pairs of judgments (e.g., 'Judgment A explains the error better than Judgment B'), enabling the model to train its own judging capability via DPO
Architecture
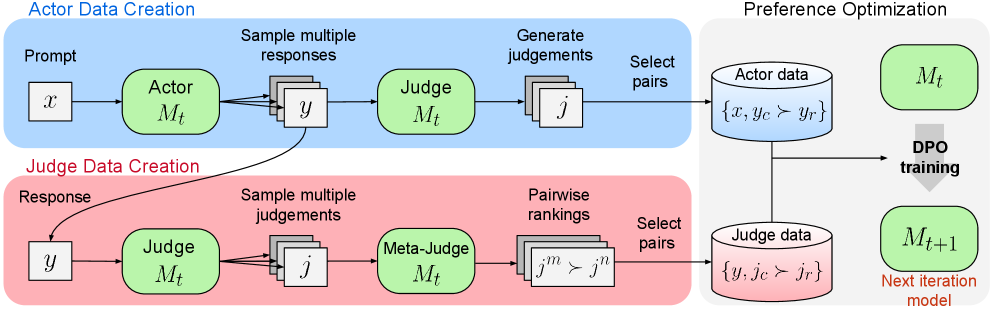
The Meta-Rewarding pipeline. Top: Actor generates responses, Judge scores them. Bottom: Meta-Judge compares two judgments (Judge outputs) to determine the better judgment. Both streams create preference data for DPO training.
Evaluation Highlights
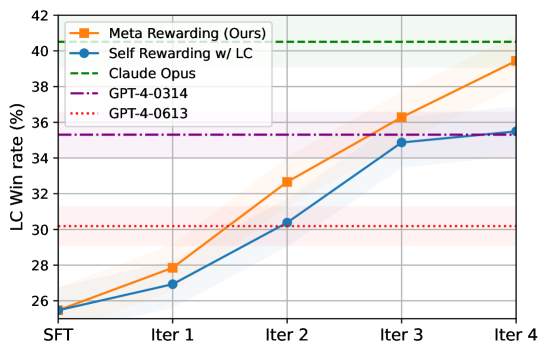
- Improves Llama-3-8B-Instruct's length-controlled win rate on AlpacaEval 2 from 22.9% to 39.4%
- Outperforms GPT-4-0314 on AlpacaEval 2 (39.4% vs 22.9% baseline)
- Achieves +8.5% improvement on Arena-Hard benchmark compared to the seed model (20.6% to 29.1%)
Breakthrough Assessment
8/10
Significant unsupervised improvement over a strong base model (Llama-3). Successfully addresses the 'stagnating judge' problem in self-play, a critical bottleneck for autonomous AI improvement.