📝 Paper Summary
Alignment training
Objective conflict in fine-tuning
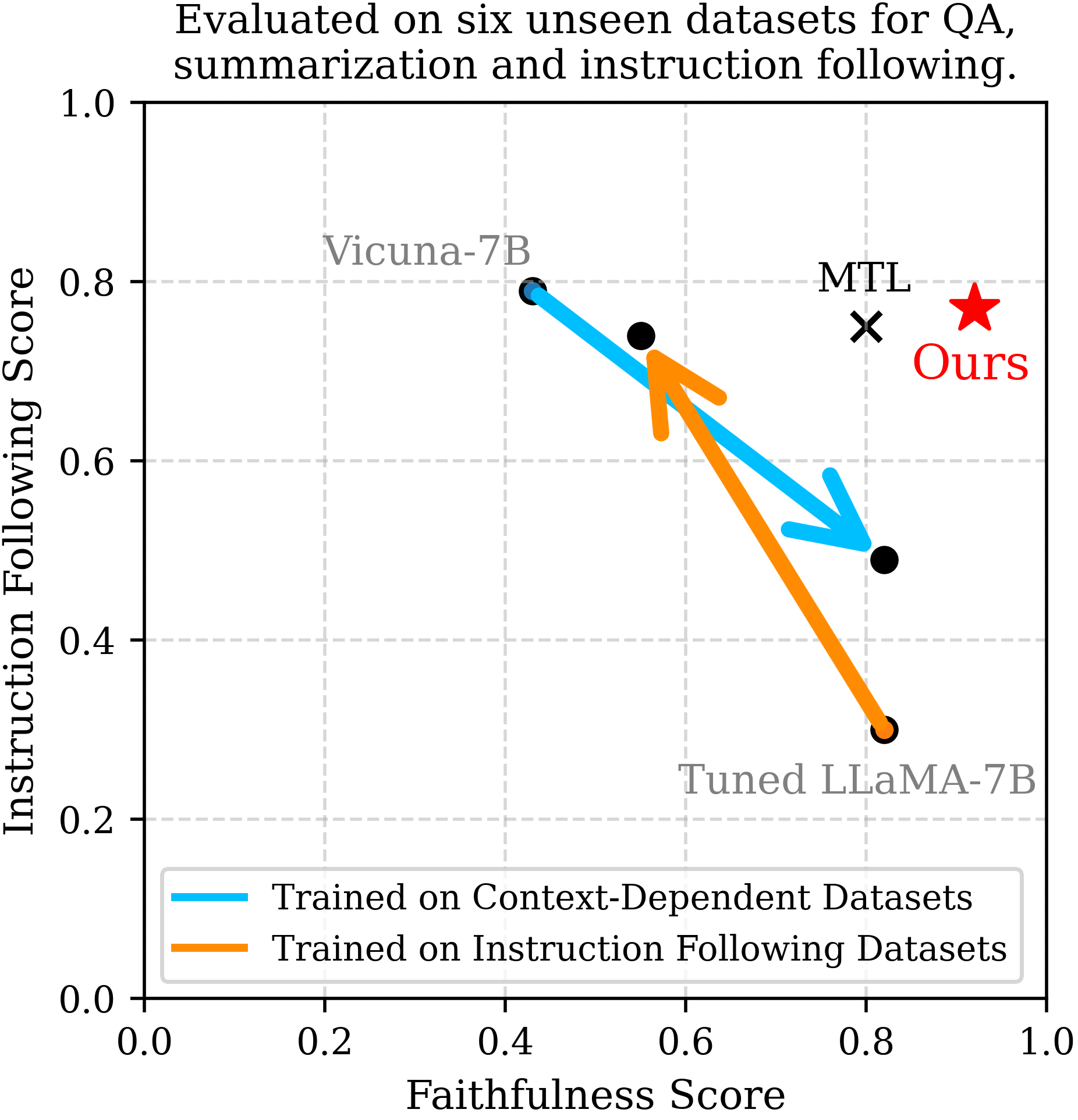
ReSet reconciles the trade-off between instruction following and faithfulness by using rejection sampling to curate high-quality fine-tuning data that aligns both objectives.
Core Problem
Training language models on instruction-following data degrades their faithfulness to context, while training on context-dependent data degrades their ability to follow open-ended instructions.
Why it matters:
- Modern LMs must be both helpful (follow instructions) and reliable (faithful to context), but current alignment methods often sacrifice one for the other
- Mixing disparate datasets (creative writing vs. extractive QA) creates objective conflicts, confusing the model's internal optimization
- Existing solutions like simple Multi-Task Learning (MTL) are sub-optimal and fail to fully resolve the interference between these competing goals
Concrete Example:
When a model fine-tuned for faithfulness (context-dependent QA) is further trained on Alpaca (instruction following), its faithfulness score drops from 0.82 to 0.55 on abstractive tasks because it learns to hallucinate rather than ground its answers.
Key Novelty
Rejection Sampling for Continued Self-instruction Tuning (ReSet)
- Instead of just mixing datasets, the method uses the model itself to generate multiple candidate responses for training prompts, varying decoding parameters like temperature
- External judges (like GPT-4) score these generations on both instruction following and faithfulness, and only the highest-rated responses are kept
- The model is then fine-tuned on this small, high-quality filtered dataset, effectively aligning it to the intersection of both objectives without massive retraining
Architecture

The ReSet pipeline: sampling generations from an MTL checkpoint, scoring them with judges, and filtering for continued fine-tuning.
Evaluation Highlights
- +18.8% faithfulness improvement over Multi-Task Learning (MTL) baseline on unseen datasets using ReSet
- +31.3% faithfulness improvement using ReSet-S (higher quality, 3x less data) compared to MTL
- Maintains high instruction-following scores (0.75+) while significantly recovering the faithfulness lost during standard instruction tuning
Breakthrough Assessment
7/10
Provides clear empirical evidence of the trade-off between key alignment objectives and proposes a practical, data-efficient solution (ReSet) that outperforms standard MTL.