📊 Experiments & Results
Evaluation Setup
Instruction following and dialogue quality evaluation using LLM-based judging.
Benchmarks:
- AlpacaEval 2.0 (Instruction Following)
- Arena-Hard-v0.1 (Complex Query Handling)
- MT-Bench (Multi-turn Dialogue)
Metrics:
- Win Rate (vs GPT-4-Preview)
- Length-Controlled Win Rate
- Average Score (1-10)
- Statistical methodology: Not explicitly reported in the paper
Key Results
| Benchmark | Metric | Baseline | This Paper | Δ |
|---|---|---|---|---|
| Main comparison on Llama3.1-8B shows Temporal SR consistently outperforming standard Self-Rewarding and other baselines. | ||||
| AlpacaEval 2.0 | Win Rate (%) | 19.69 | 29.44 | +9.75 |
| Arena-Hard-v0.1 | Score (Win Rate) | 9.4 | 14.6 | +5.2 |
| MT-Bench | Average Score | 8.09 | 8.27 | +0.18 |
| Cross-model generalization confirms the method works on Qwen and Mistral architectures. | ||||
| Arena-Hard-v0.1 | Score | 21.5 | 34.4 | +12.9 |
| AlpacaEval 2.0 | Win Rate (%) | 20.44 | 23.47 | +3.03 |
Experiment Figures
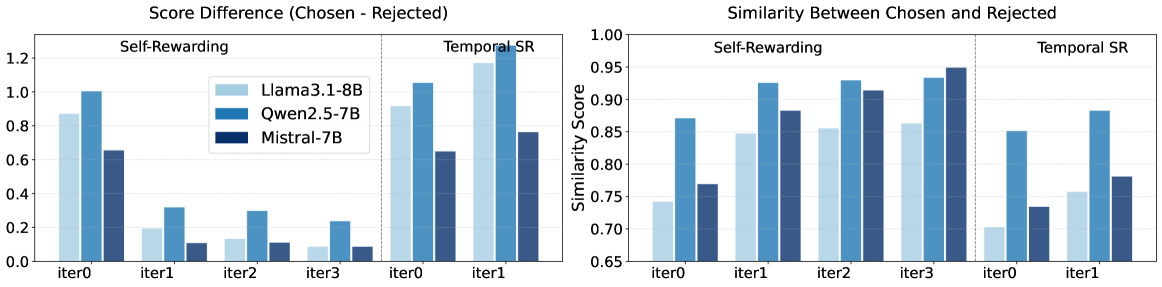
Comparison of representational similarity between chosen and rejected responses over training iterations for Standard Self-Rewarding vs. Temporal Self-Rewarding.
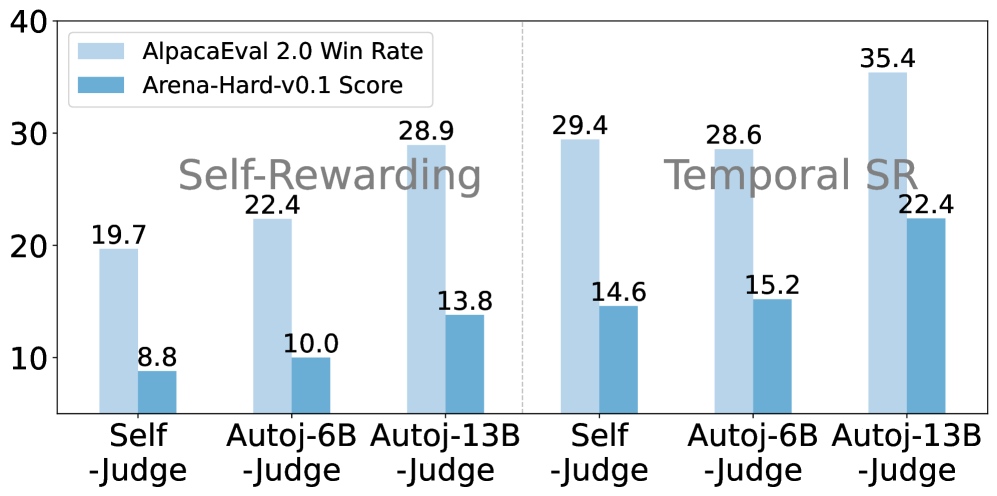
Ablation of Judge Model (Self-Judge vs. External AutoJ).
Main Takeaways
- Temporal coordination resolves the gradient collapse issue: Figure 1 analysis proves that standard SR leads to converging representations, while Temporal SR maintains a healthy gap.
- Efficiency: Temporal SR achieves better results in fewer iterations (1-2) than standard SR requires (3-4), balancing out the cost of the extra 'future model' training step.
- Robustness: The method works across different model families (Llama, Qwen, Mistral) and sizes (3B, 8B, 70B).
- Unexpected OOD gains: The method improves performance on math (GSM8K) and code (HumanEval) even though the iterative training data (OpenAssistant/UltraFeedback) targets general instruction following.