📝 Paper Summary
Vision-Language Models (VLMs)
Efficient Inference
Token Pruning
OC-VTP improves VLM efficiency by using a lightweight, pre-trained object-centric module to select the most representative vision tokens based on reconstruction error, without fine-tuning the VLM.
Core Problem
Vision tokens in VLMs are computationally expensive and information-redundant, but existing pruning methods rely on heuristic attention metrics that do not guarantee the selection of the most representative tokens.
Why it matters:
- Vision tokens dominate inference cost (e.g., 2880 tokens in LLaVA-NeXT), creating a bottleneck for high-resolution or multi-image tasks.
- Existing methods rely on indirect criteria (like attention averages) without optimality guarantees, potentially discarding important information.
- Current approaches often require fine-tuning the VLM or accessing text tokens, limiting flexibility and increasing deployment complexity.
Concrete Example:
In an image with a small fence, heuristic methods might discard the fence tokens because they have low attention scores compared to the background. Consequently, the VLM fails to answer questions about the fence (as seen in failure cases in Figure 4), whereas OC-VTP aims to preserve such distinct object features.
Key Novelty
Object-Centric Vision Token Pruning (OC-VTP)
- Uses Slot Attention to aggregate vision tokens into object-centric slots, ensuring the selected tokens mathematically minimize the reconstruction error of the original features.
- Introduces an Area-Weighted MSE loss during training to ensure small but important objects (which might be ignored by standard MSE) are preserved.
- Designed as a plug-and-play module trained once on COCO, generalizable to various VLMs without requiring model-specific fine-tuning.
Architecture
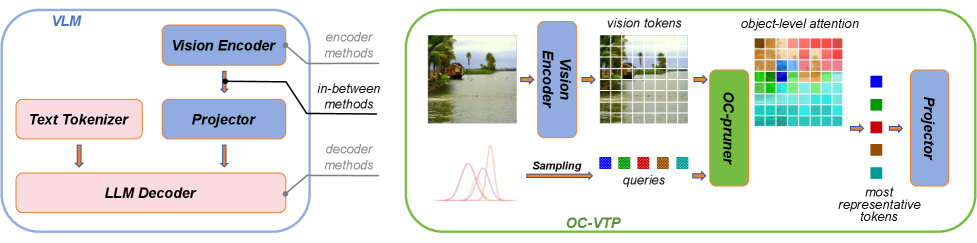
The integration of the OC-Pruner into the VLM architecture.
Evaluation Highlights
- Retaining only 11.1% of vision tokens on LLaVA-1.5 maintains 95.5% of original performance, outperforming the second-best method (VisionZip) which holds 93.1%.
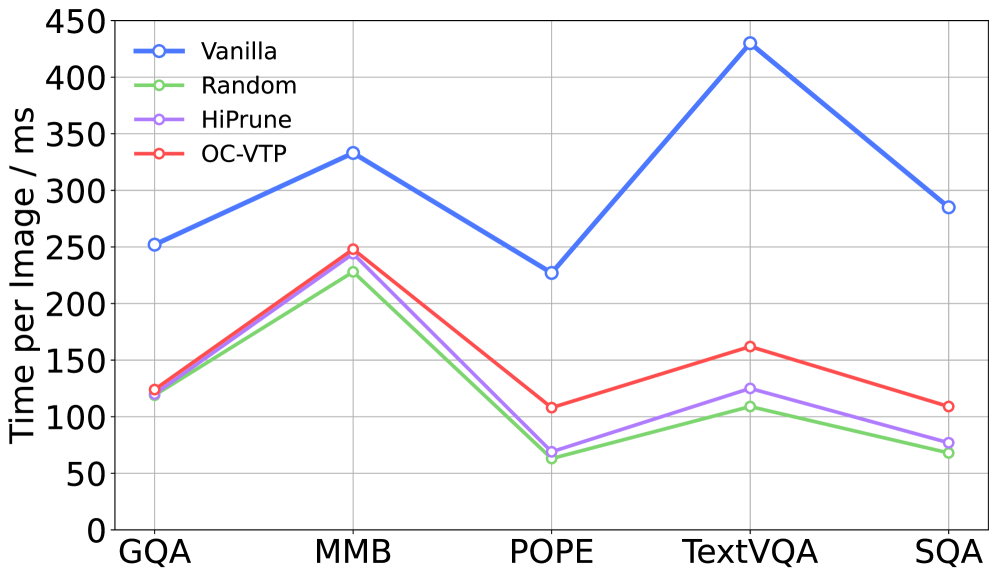
- Reduces inference latency by 65% (811.8 ms to 287.3 ms) on LLaVA-NeXT while preserving accuracy comparable to the full model.
- Achieves a 17x reduction in prefill FLOPs (33.76 T to 1.95 T) for LLaVA-NeXT with negligible overhead from the pruner itself.
Breakthrough Assessment
8/10
Strong empirical results with a theoretically grounded approach (reconstruction minimization) rather than heuristics. The plug-and-play nature without VLM fine-tuning is highly practical.