📝 Paper Summary
Knowledge Distillation
Small Language Models (SLMs)
Multi-Hop Question Answering
D&R Distillation splits reasoning into two interacting small student models—a Decomposer that asks sub-questions and a Responser that answers them using retrieval—allowing small models to solve complex multi-hop tasks efficiently.
Core Problem
Chain-of-Thought Distillation (CoTD) fails for small language models on knowledge-intensive multi-hop tasks because SLMs lack the capacity to memorize vast knowledge and struggle to learn integrated decomposition and reasoning simultaneously.
Why it matters:
- Existing CoT distillation methods work well for arithmetic but fail when heavy external knowledge is required
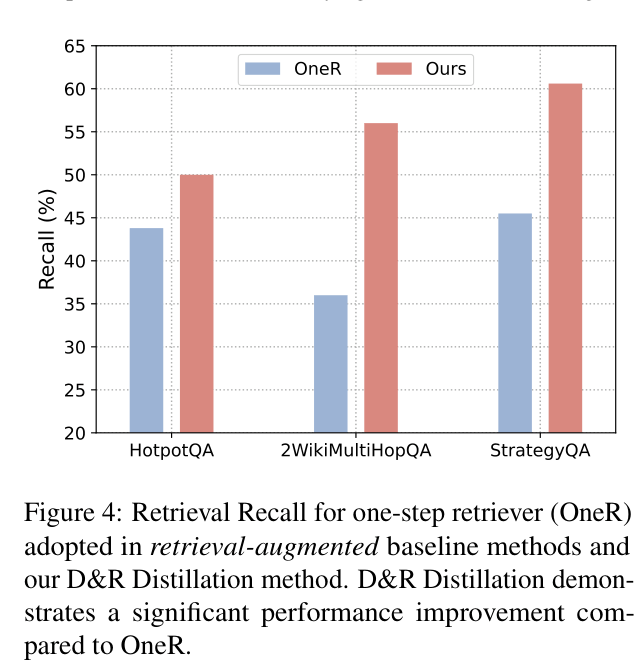
- Small models cannot effectively utilize one-step retrieval because relevance often depends on intermediate reasoning steps
- Learning all sub-tasks (decomposition, retrieval, reasoning) in a single model is inefficient and requires massive training data
Concrete Example:
For the question 'What is the elevation range for the area that the eastern sector of the Colorado orogeny extends into?', a standard CoT-distilled small model fails to retrieve the necessary intermediate fact ('extends into the High Plains') and cannot answer. The proposed method decomposes this into 'What does the eastern sector... extend into?' first, retrieves 'High Plains', then asks about the elevation of High Plains.
Key Novelty
Decompose-and-Response (D&R) Distillation
- Decouples the reasoning process into two separate student models: a Decomposer (asks sub-questions) and a Responser (answers sub-questions using retrieval)
- Transforms complex multi-hop reasoning into an interactive dialogue where the Responser provides external knowledge at every step, reducing the cognitive load on each individual small model
Architecture
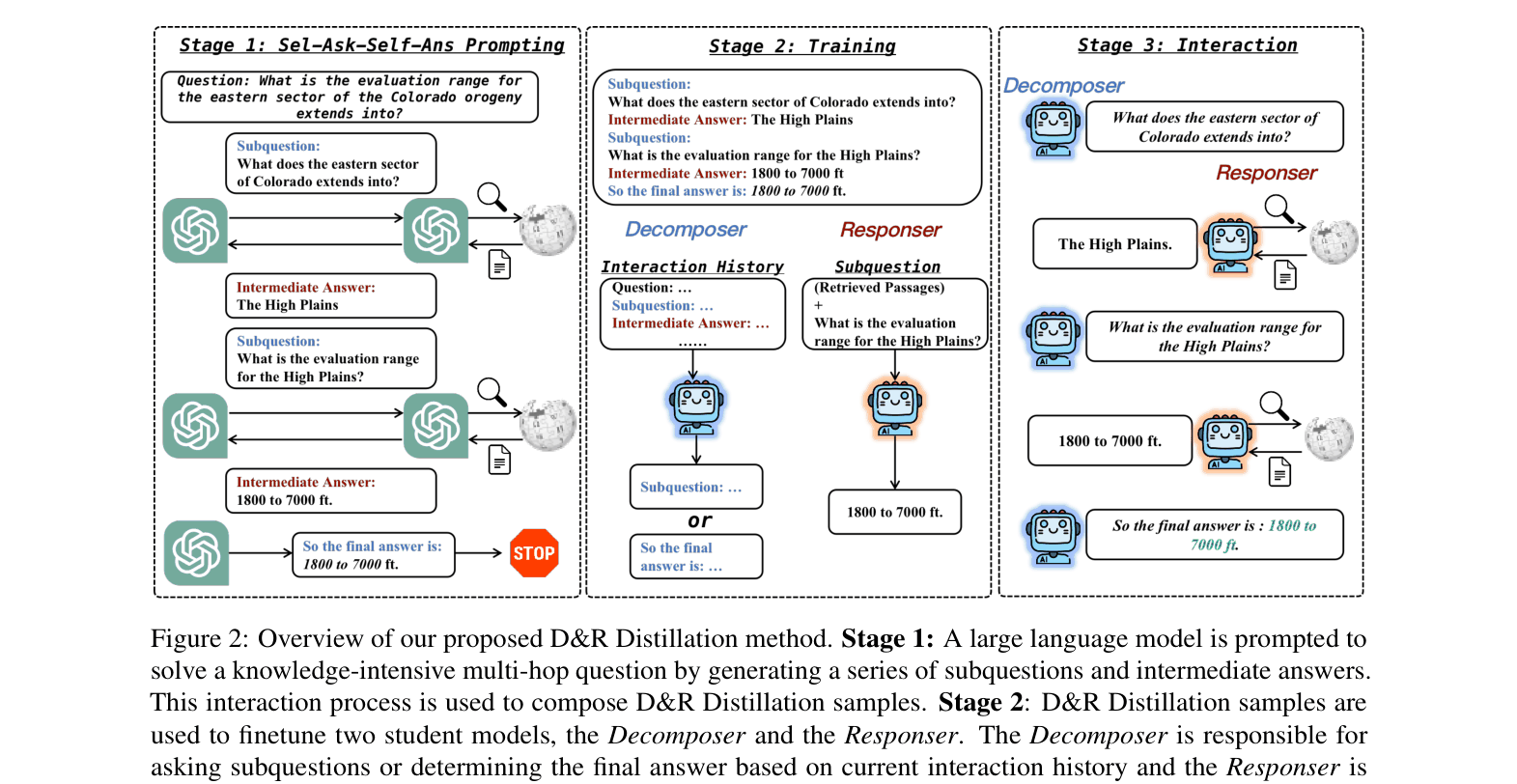
The three-stage pipeline: (1) Generating data with LLM self-ask prompting, (2) Distilling the Decomposer and Responser separately, (3) Interactive inference where Decomposer asks and Responser answers.
Evaluation Highlights
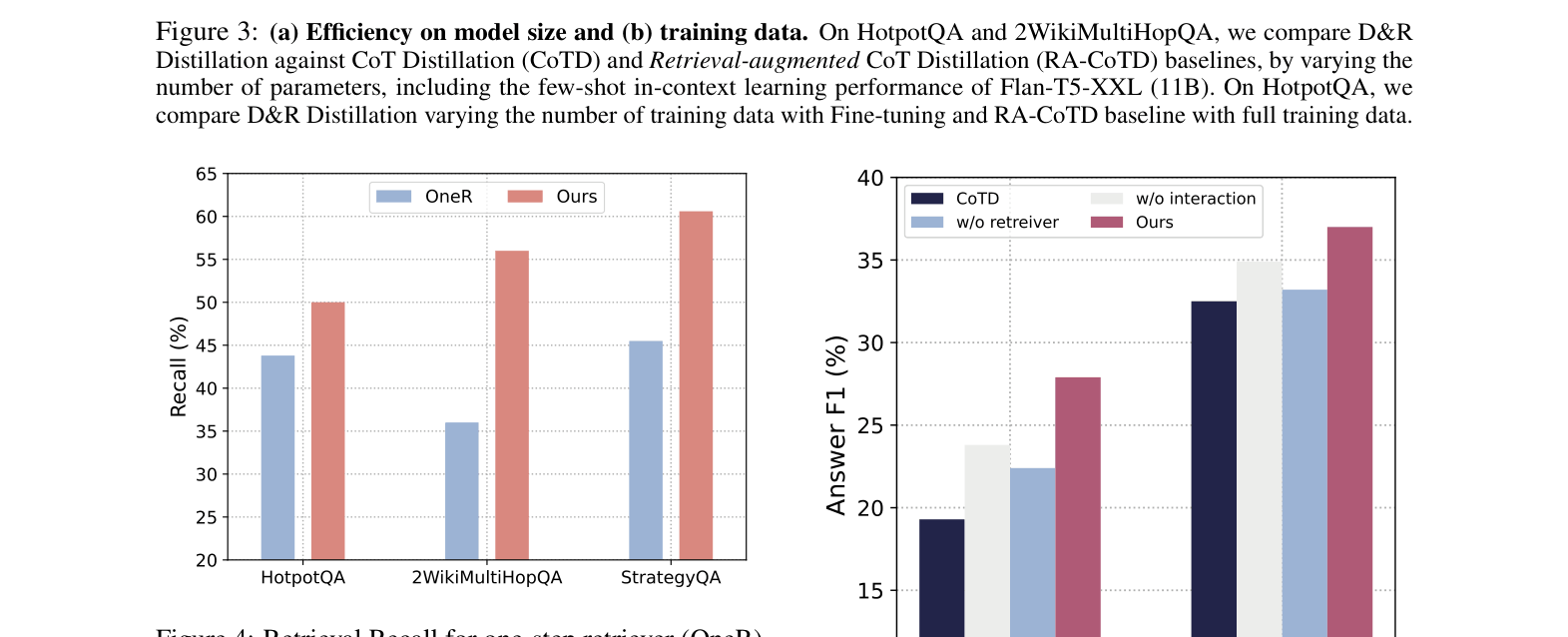
- Outperforms 11B FLAN-T5-XXL (few-shot) using only two 220M T5-Base models on HotpotQA and 2WikiMultiHopQA
- +8.2% Answer F1 improvement over Fine-tuning baseline on 2WikiMultiHopQA with T5-Base
- Achieves superior performance using only 1/10th of the training data compared to standard Chain-of-Thought Distillation (CoTD) baselines
Breakthrough Assessment
7/10
Strong practical contribution for deploying efficient small models. Effectively solves the 'knowledge gap' in distillation by architectural decomposition, though the core components (T5, BM25) are standard.