📝 Paper Summary
LLM Routing / Selection
Efficient Inference
Ensemble Methods
SelectLLM employs a lightweight multi-label classifier to route queries to the most suitable subset of LLMs, improving accuracy and reducing latency compared to querying all models.
Core Problem
Individual LLMs have diverse strengths and weaknesses, but querying a full ensemble of models to find the best answer is computationally expensive and slow.
Why it matters:
- No single open-source LLM dominates across all benchmarks; different models excel at different reasoning tasks
- Ensembling all available models increases inference costs and latency linearly with the number of models
- Routing queries efficiently can unlock the collective intelligence of smaller models without the cost of giant monolithic models
Concrete Example:
For a complex math problem, a general-purpose model might fail while a math-specialized model succeeds. A brute-force ensemble queries both (wasting resources), whereas SelectLLM identifies the math query and routes it only to the math specialist.
Key Novelty
Supervised Multi-Label Classification for LLM Routing
- Trains a lightweight classifier (RoBERTa-based) on query-response pairs to predict which LLMs in a pool are likely to answer a specific query correctly
- Uses confidence scores from this classifier to select a dynamic subset of models (rather than a fixed number or single model) for each query
- Introduces a weighted majority voting scheme that adjusts vote strength based on the router's confidence in each selected model
Architecture
The SelectLLM inference workflow.
Evaluation Highlights
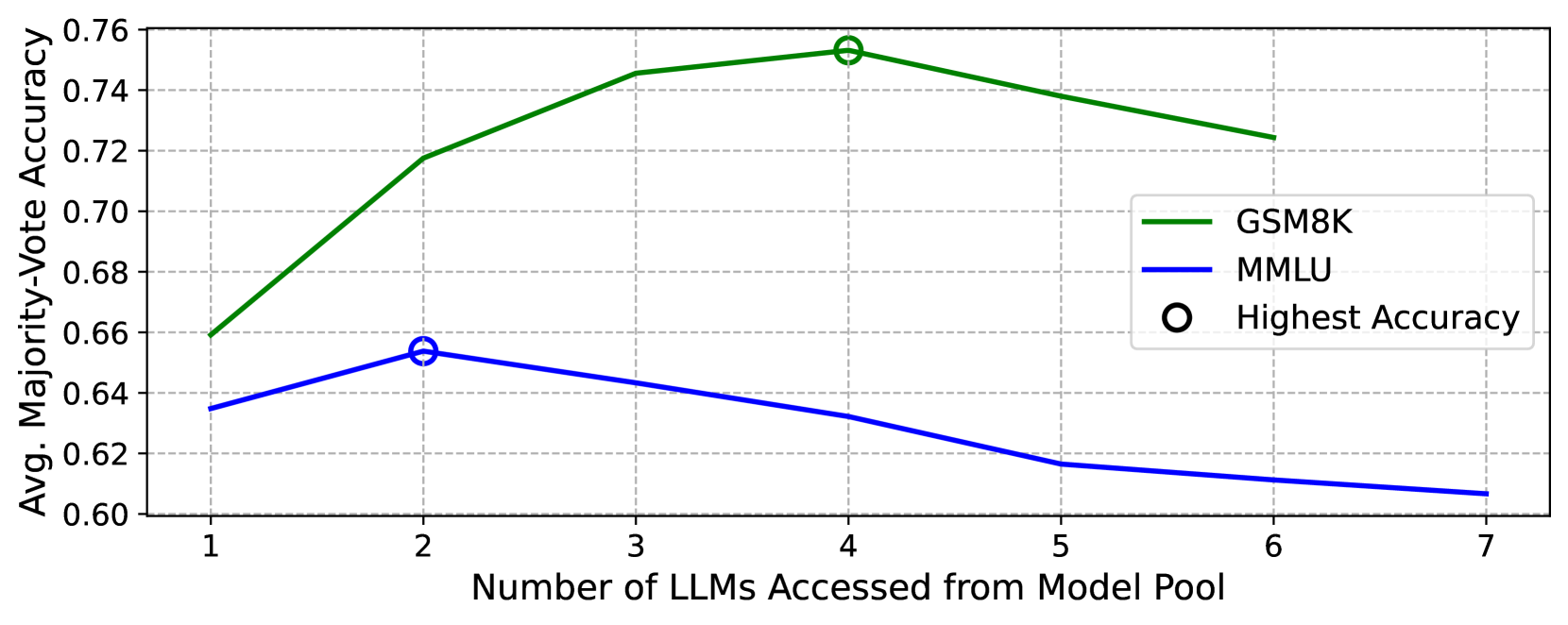
- Reduces inference latency by 70% on MMLU and 13% on GSM8K compared to the top-performing baseline while maintaining or improving accuracy
- Achieves +4.89% accuracy improvement on MMLU compared to strong ensemble baselines
- Outperforms similarly sized top-performing LLM subsets, demonstrating that dynamic selection is superior to static model choices
Breakthrough Assessment
7/10
Strong practical results in efficiency and accuracy for LLM routing. The approach is straightforward but effective, addressing a major bottleneck in deploying ensembles.