📊 Experiments & Results
Evaluation Setup
Zero-shot recommendation (training on one subset, testing on unseen users/items) and text-enhanced collaborative filtering integration.
Benchmarks:
- Amazon-Beauty (Zero-shot Recommendation)
- Amazon-Toys (Zero-shot Recommendation)
- Yelp (Zero-shot Recommendation)
Metrics:
- Recall@10
- NDCG@10
- Statistical methodology: Not explicitly reported in the paper
Key Results
| Benchmark | Metric | Baseline | This Paper | Δ |
|---|---|---|---|---|
| Zero-shot recommendation performance comparing EasyRec against baselines across multiple datasets. | ||||
Experiment Figures
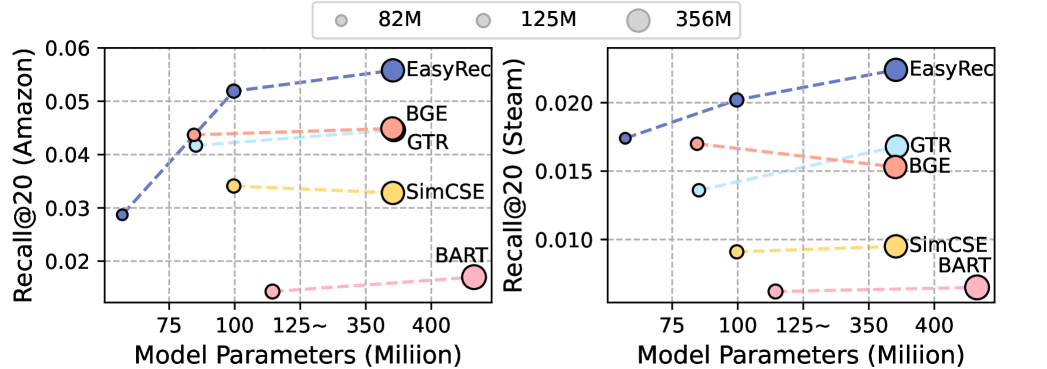
Performance vs. Parameter Size/Efficiency comparison.
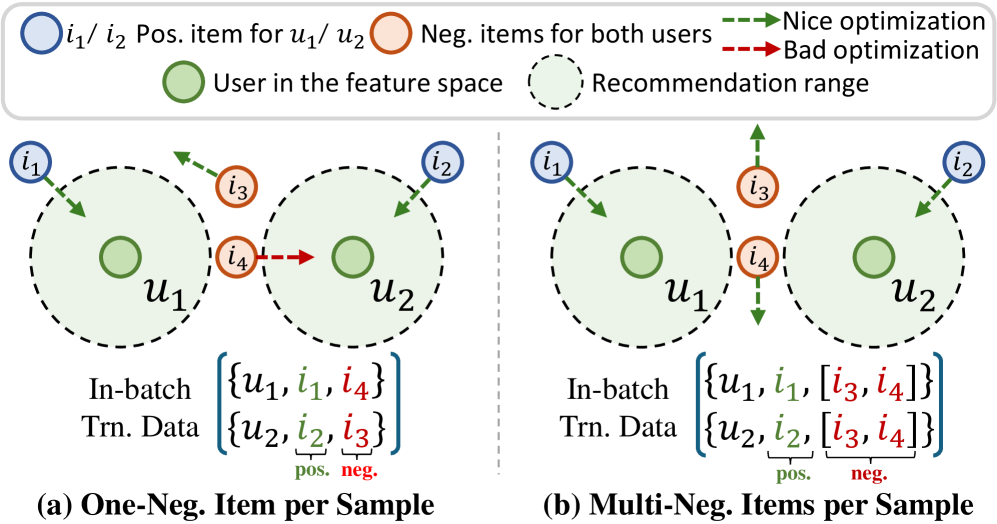
Illustration of Contrastive Learning vs. BPR.
Main Takeaways
- EasyRec significantly outperforms traditional zero-shot baselines (BM25, BERT) and competitive models (UniSRec), demonstrating the value of aligning text with collaborative signals.
- The model exhibits scaling law properties: performance improves monotonically as the parameter size increases from 100M to 400M.
- Ablation studies confirm that both the collaborative profiling (incorporating reviews) and the contrastive learning objective are critical for performance.
- Profile diversification (rephrasing) acts as an effective data augmentation strategy, enhancing robustness and generalization.