📝 Paper Summary
Language Model Training
Reinforcement Learning (RLHF/RLAIF)
Reasoning
PCL extends training beyond the standard end-of-sequence token, allowing models to generate and learn from hidden self-evaluations and reward predictions that are discarded during inference to maintain efficiency.
Core Problem
Standard LLM training stops immediately at the end-of-sequence token, preventing models from learning to reflect on or evaluate their completed outputs.
Why it matters:
- Current methods like SFT foster passive mimicry rather than active self-assessment
- Reinforcement learning usually relies on opaque external reward models, lacking transparency
- Valuable 'post-thinking' opportunities for quality assessment are wasted by premature sequence termination
Concrete Example:
A model answers a math problem incorrectly but stops generating immediately. It never gets the chance to review its steps, realize the logic error, and calculate a low reward score, which would reinforce the internal concept of 'bad reasoning'.
Key Novelty
Post-Completion Learning (PCL)
- Defines a 'post-completion' space after the answer where the model generates self-evaluations and reward predictions during training
- Uses a 'white-box' RL approach where the model explicitly learns to calculate its own rewards (accuracy, format, consistency) rather than relying on a black-box external model
- Uses a temporary stop token (<post-completion>) to separate inference content from training-only reflection content, ensuring zero inference overhead
Architecture
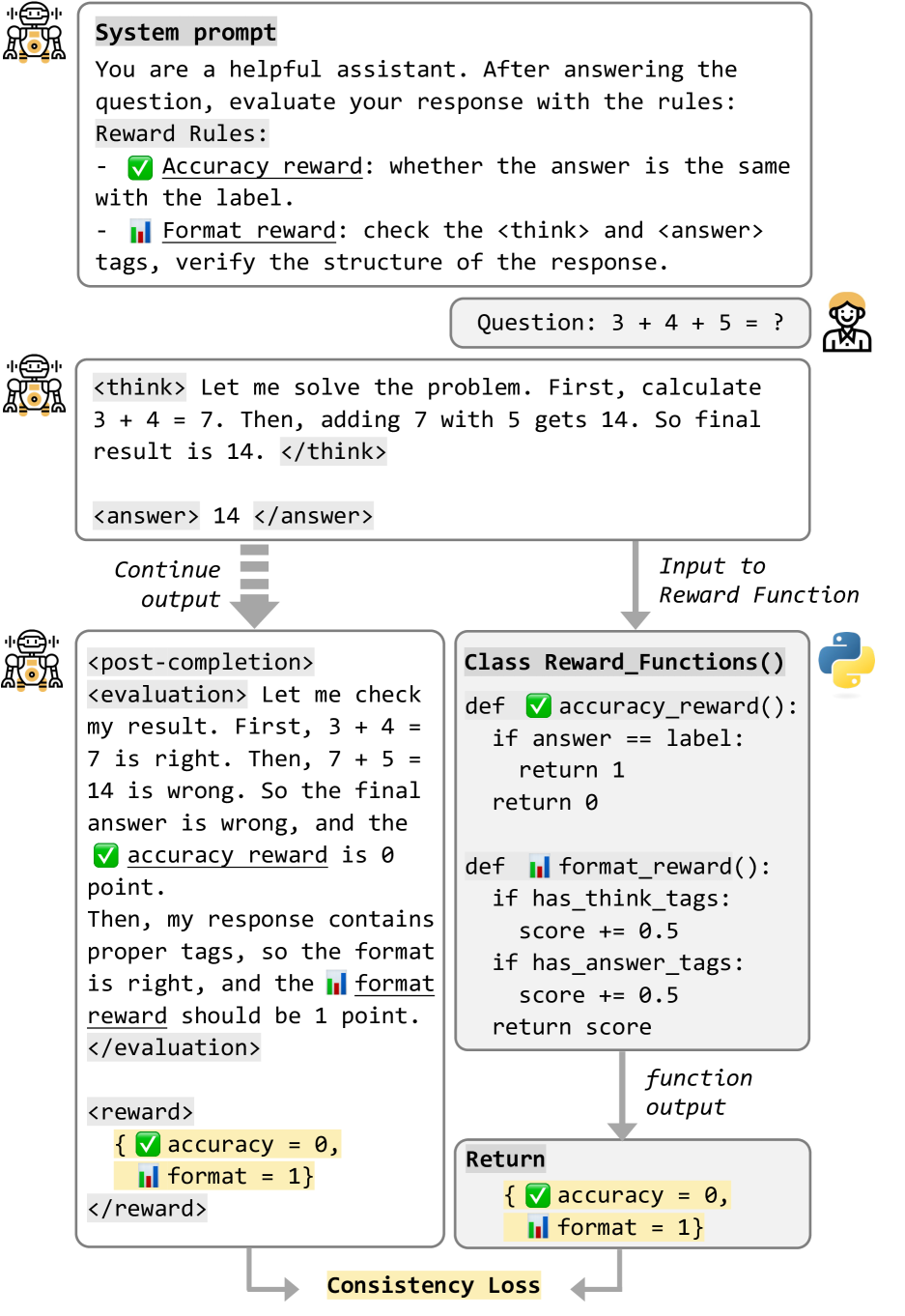
Conceptual comparison between traditional Black-box RL and PCL's White-box RL, plus the sequence structure.
Evaluation Highlights
- Consistent performance improvements over traditional SFT and RL methods on reasoning tasks (quantitative details pending specific table extraction)
- Validates effectiveness through 'white-box' reinforcement learning where models internalize reward functions
- Maintains inference efficiency by stopping generation before the self-evaluation block during deployment
Breakthrough Assessment
7/10
Cleverly utilizes the 'ignored' space after generation for training signals. It effectively combines self-correction principles with efficient inference, addressing the 'inference cost' bottleneck of methods like Reflexion.