📝 Paper Summary
Sequential Recommendation
Large Language Models (LLMs) for Recommendation
Parameter-Efficient Fine-Tuning (PEFT)
iLoRA treats sequential recommendation as multi-task learning by dynamically assembling a personalized Low-Rank Adaptation (LoRA) module for each user sequence using a mixture of experts to capture individual behavioral variability.
Core Problem
Standard LoRA fine-tuning applies a uniform set of parameters across all user sequences, ignoring the significant variability in individual behaviors and causing negative transfer between dissimilar sequences.
Why it matters:
- User behaviors exhibit distinct interests and patterns; forcing a single model adaptation to handle all variations leads to suboptimal performance.
- Unrelated tasks (or dissimilar user sequences) exhibit different gradient trajectories, leading to conflicts and negative transfer when using shared parameters.
- Existing methods focus on prompt engineering but leave the fine-tuning mechanism static, limiting the model's ability to adapt to diverse user needs.
Concrete Example:
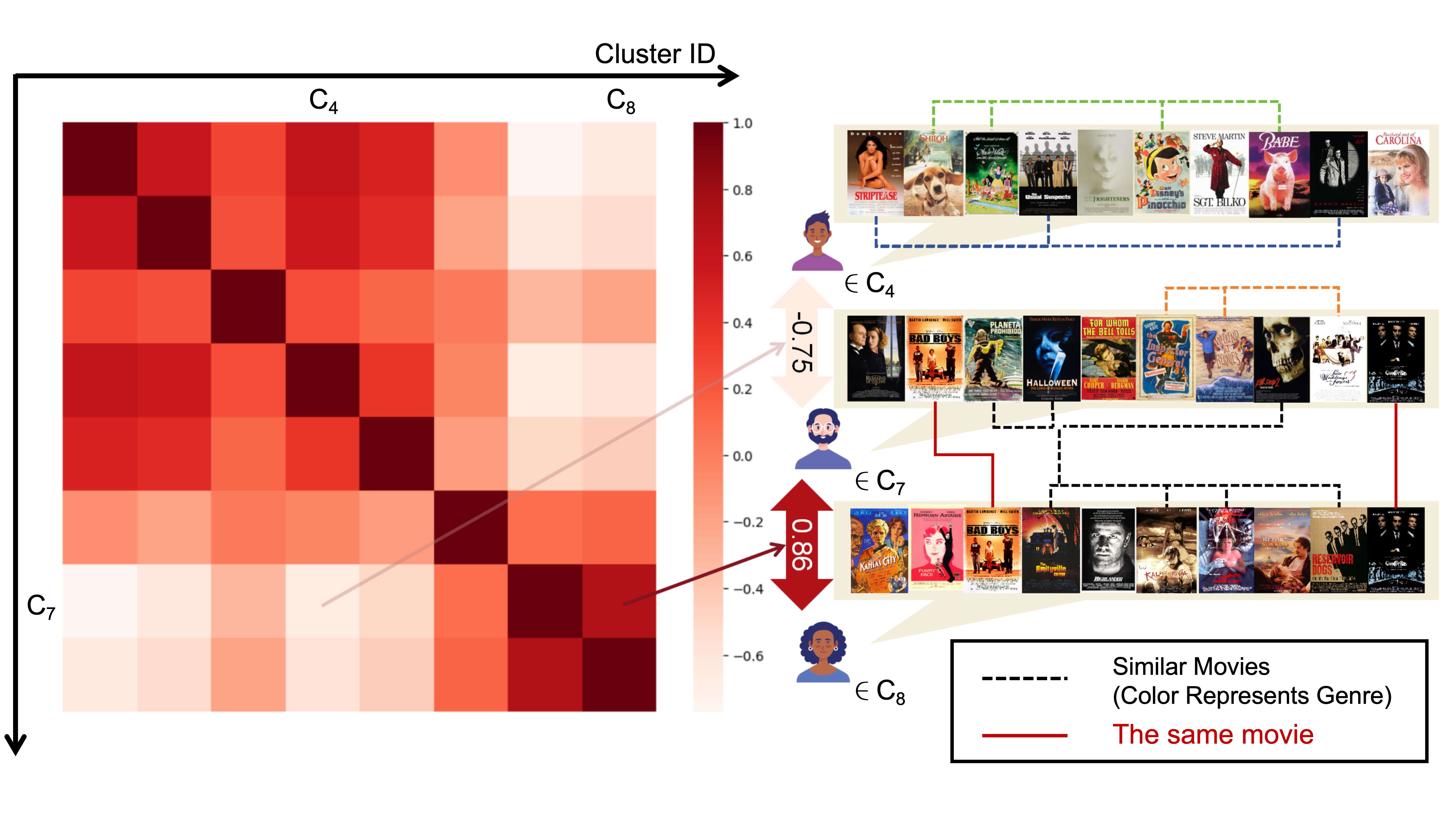
In LLaRA, gradients from distant user clusters in the collaborative space are misaligned (Figure 1). A uniform LoRA module tries to satisfy conflicting updates from these dissimilar sequences, resulting in a 'Jack of all trades, master of none' effect where the model fails to specialize for either user type.
Key Novelty
Instance-wise LoRA (iLoRA)
- Replaces the standard single LoRA matrices with a bank of 'expert' sub-matrices, where each expert specializes in different latent aspects of user behavior.
- Uses a gating network, guided by a dense representation of the user's history (from a standard recommender like SASRec), to calculate dynamic attention scores for each instance.
- Aggregates these experts on-the-fly to create a unique, instance-specific LoRA module for every input sequence without increasing the total inference parameter count compared to standard LoRA.
Architecture
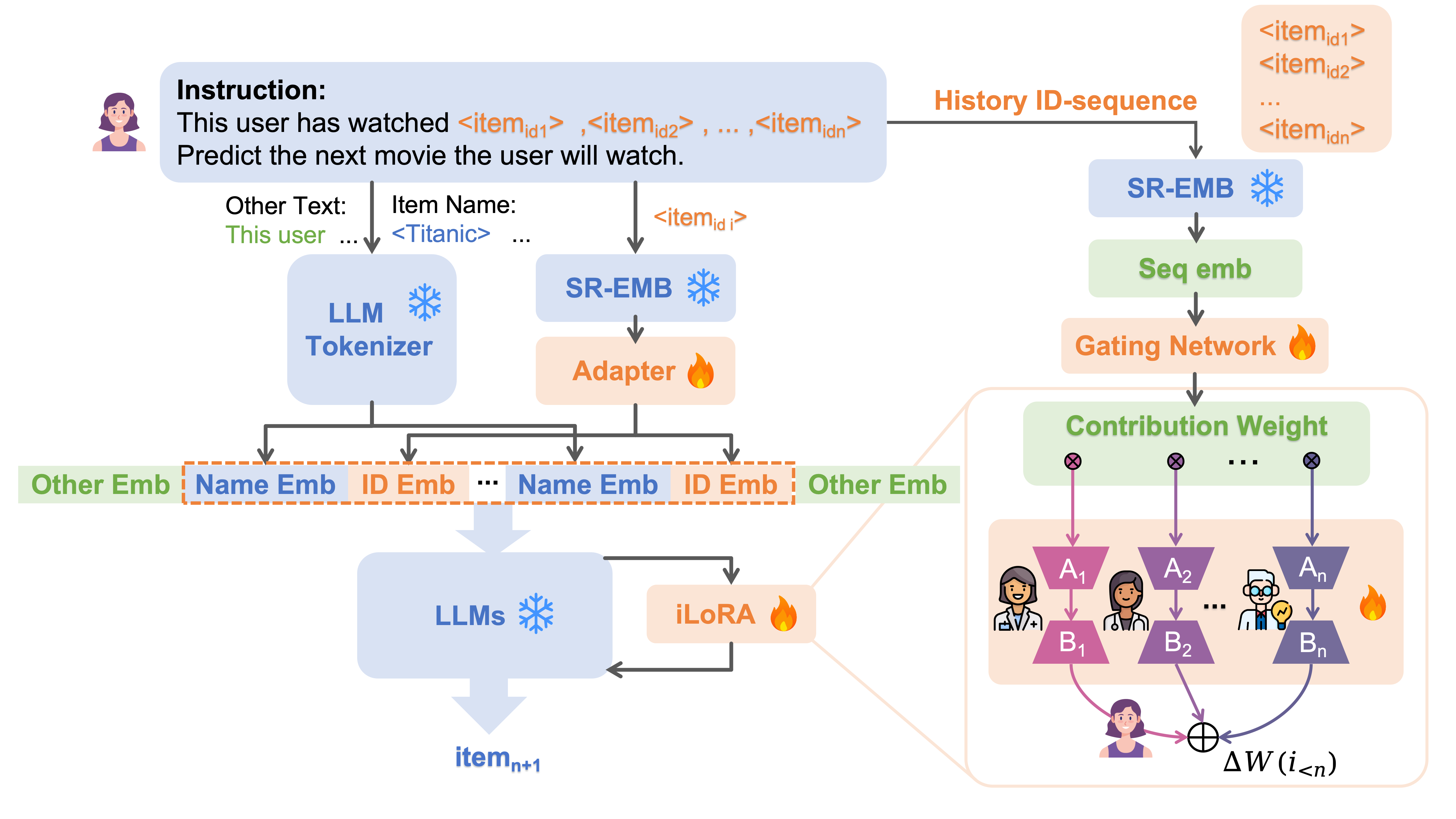
The iLoRA framework. It shows how a user sequence is processed by SASRec to get a representation z, which is then used by a Gating Network to output weights ω. These weights combine multiple LoRA experts (A_k, B_k) into specific A and B matrices for the LLM.
Evaluation Highlights
- Achieves an average relative improvement of 11.4% in Hit Ratio over basic LoRA across three datasets.
- Outperforms state-of-the-art LLM-based method LLaRA and traditional methods like SASRec on LastFM, MovieLens, and Steam datasets.
- Accomplishes these gains with less than a 1% relative increase in trainable parameters compared to standard LoRA.
Breakthrough Assessment
7/10
Offers a smart, parameter-efficient application of MoE to LoRA for recommendation. While the architectural components (LoRA, MoE) are known, their combination to solve the specific 'negative transfer in sequential recommendation' problem is novel and effective.