📝 Paper Summary
Modularized RAG pipeline
Retrieval
This paper classifies retrieval noise into beneficial and harmful categories, demonstrating that certain noise types like datatype mixtures or garbled text actually improve LLM reasoning and confidence.
Core Problem
Existing research assumes all retrieval noise is detrimental and focuses on limited types (e.g., irrelevant documents), failing to capture the complexity of real-world noise or its potential positive effects.
Why it matters:
- Real-world retrieval sources contain diverse non-standard noises (URLs, code, typos, fake news) that standard RAG evaluations overlook
- Current robustness methods focus solely on defense, potentially missing opportunities to leverage 'beneficial' noise for better model performance
- Lack of a comprehensive taxonomy and benchmark hinders the development of RAG systems robust to complex noisy environments
Concrete Example:
When asked about a specific fact, a standard RAG system might be misled by 'counterfactual noise' (fake news) claiming the opposite. However, the paper finds that adding 'illegal sentence noise' (random word salad) to the context helps the model ignore the fake news and focus on the correct evidence.
Key Novelty
NoiserBench & Beneficial Noise Discovery
- Defines a taxonomy of 7 noise types from a linguistic perspective, categorizing them into 'beneficial' (e.g., datatype, illegal sentence) and 'harmful' (e.g., counterfactual, prior)
- Establishes NoiserBench, a benchmark simulating these noise types across multiple reasoning tasks (single-hop, multi-hop, implicit)
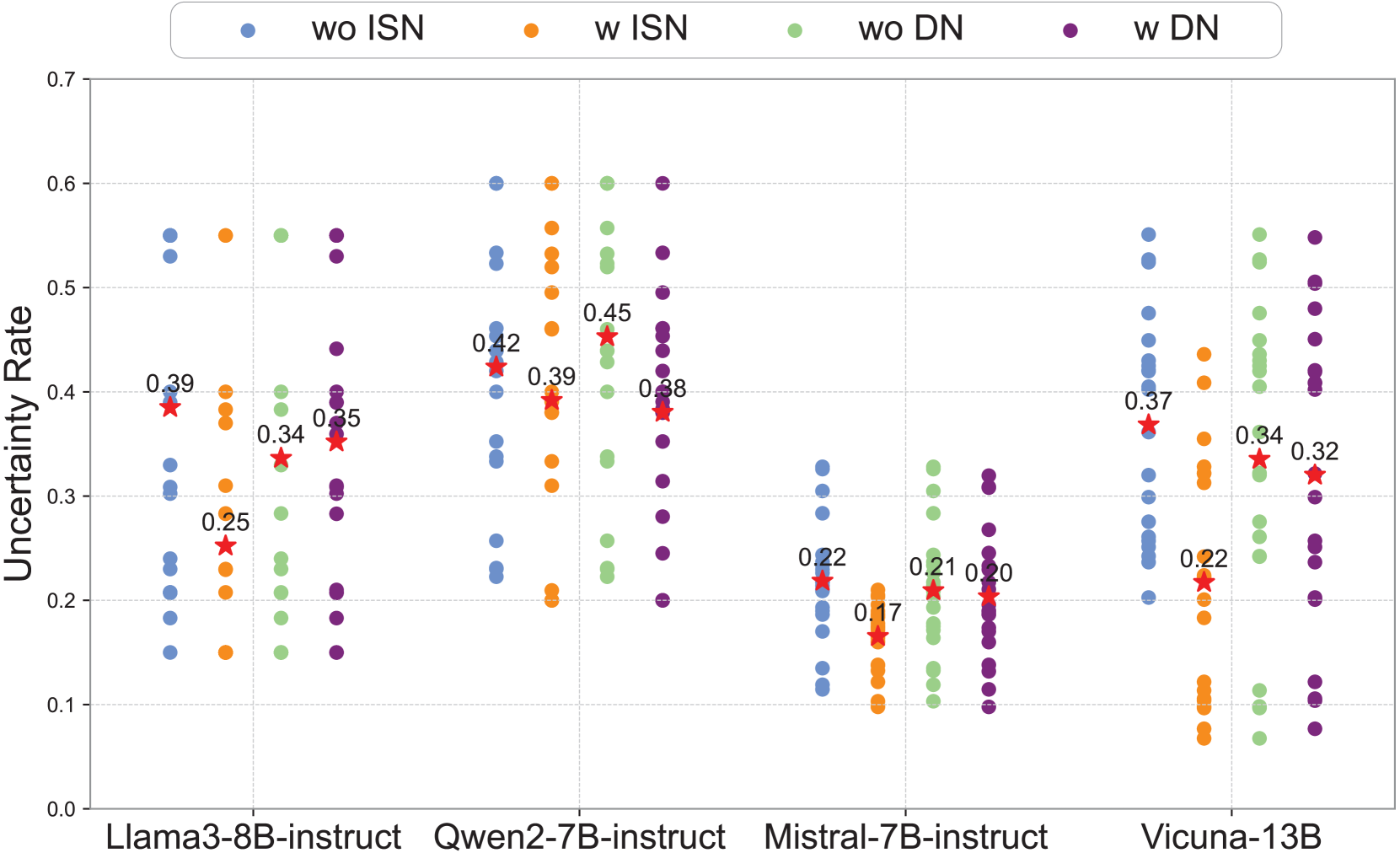
- Identifies the 'Aladdin’s Lamp' effect: beneficial noise triggers clearer reasoning paths and higher confidence in golden context, actively improving performance over noise-free baselines
Architecture
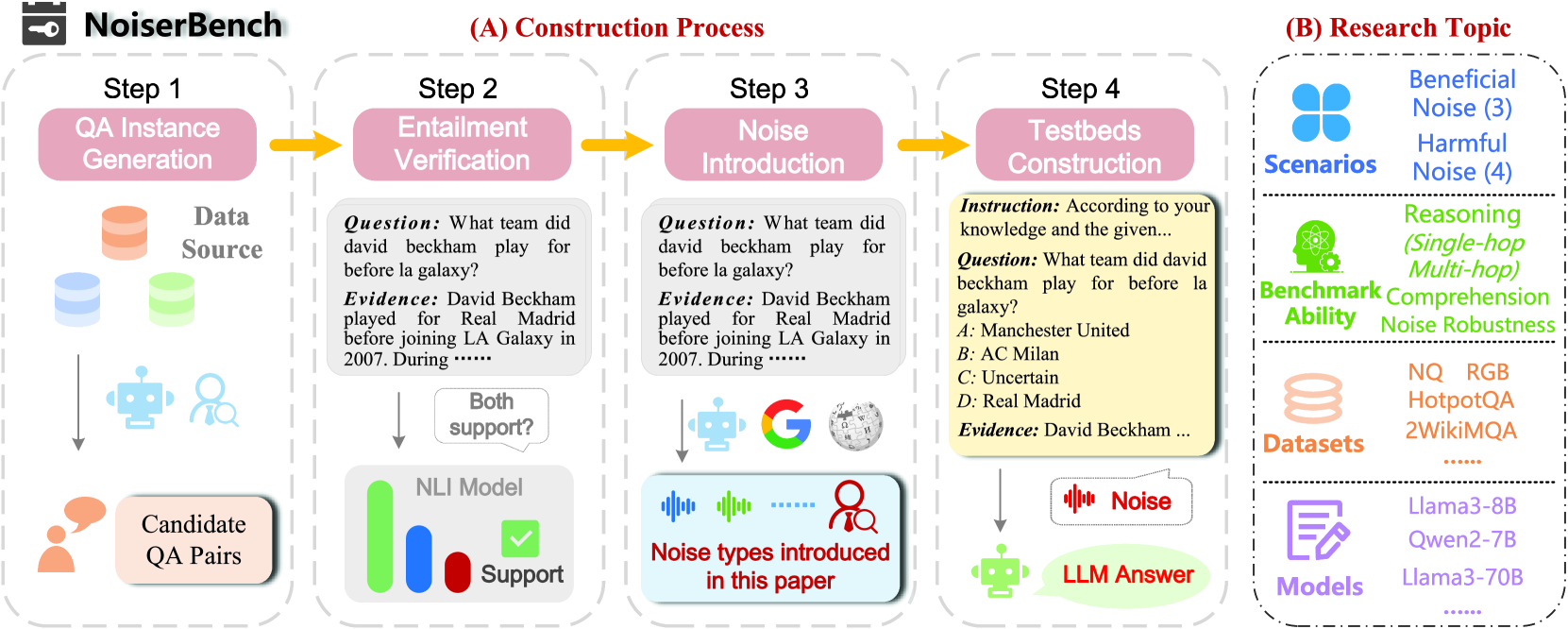
The NoiserBench construction framework pipeline.
Evaluation Highlights
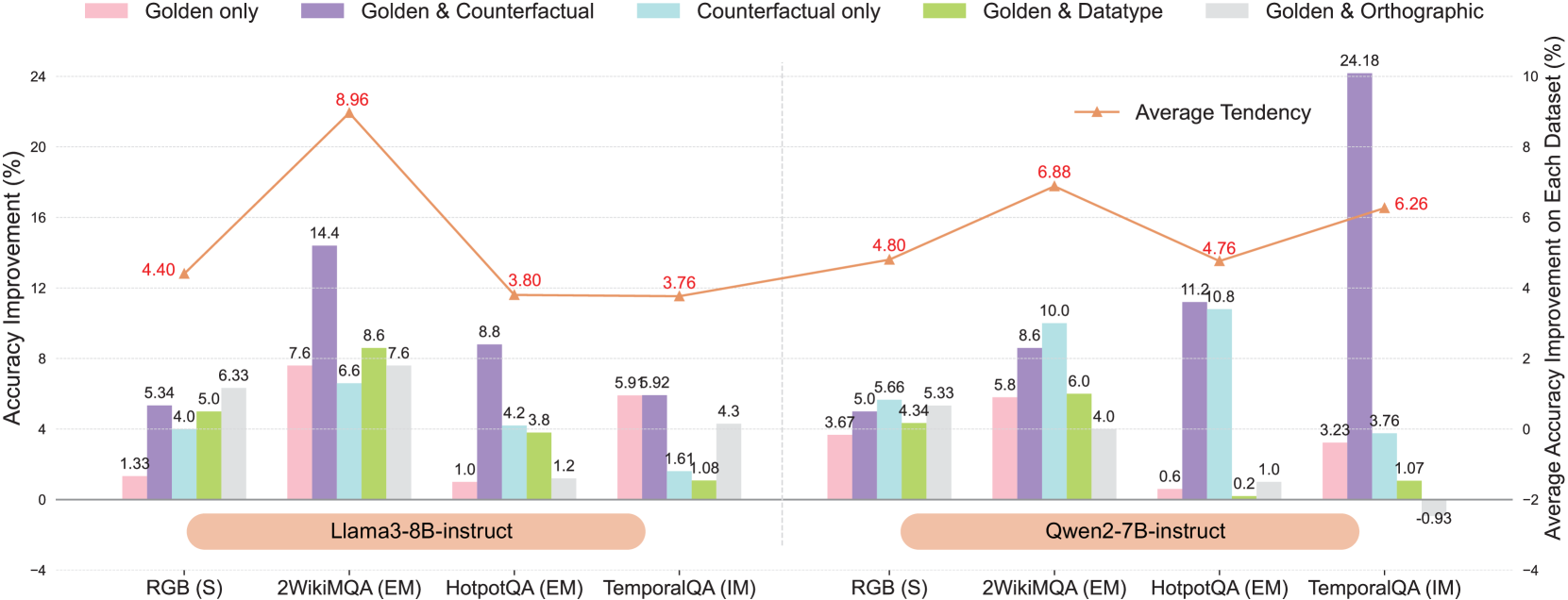
- Illegal Sentence Noise (ISN) improves accuracy by +3.32% on Llama3-8B-Instruct and +1.65% on Qwen2-7B-Instruct compared to clean baselines
- Adding beneficial noise (ISN) to harmful scenarios (e.g., counterfactual noise) boosts average accuracy by over 10% across datasets
- Self-RAG performance consistently improves with ISN across NQ, RGB, and StrategyQA datasets compared to no-noise settings
Breakthrough Assessment
7/10
Provides a counter-intuitive and empirically supported finding that specific noise types aid LLMs, alongside a structured taxonomy and benchmark. High practical value for RAG robustness.