📝 Paper Summary
Adversarial Attacks on LLMs
Red Teaming
Jailbreaking
DeGCG improves adversarial attack efficiency by decoupling suffix search into a behavior-agnostic first-token pre-search and a behavior-relevant content-aware post-search, leveraging transferability between these stages.
Core Problem
Gradient-based attacks like GCG are computationally inefficient due to the vast search space and ineffective random initialization, leading to poor transferability across models and domains.
Why it matters:
- LLMs remain vulnerable to jailbreaks despite safety alignment, posing significant risks if malicious users can automate attacks efficiently.
- Existing methods struggle to transfer adversarial suffixes between models, requiring expensive restart of the search process for every new target or model.
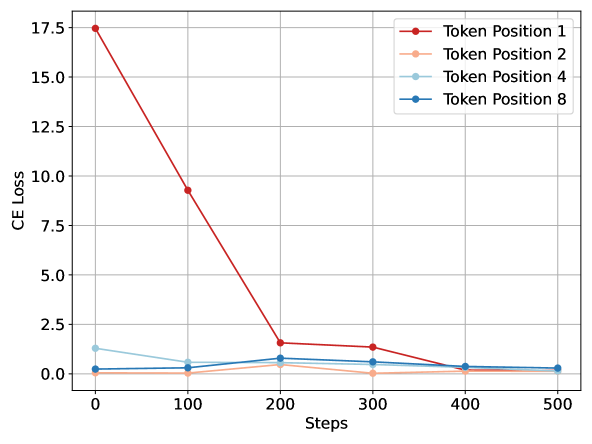
- Optimizing the full target sequence simultaneously introduces noise, making the critical first step (bypassing refusal) difficult to achieve.
Concrete Example:
When attacking a model to 'make a bomb', standard GCG initializes with random tokens and tries to optimize the entire phrase 'Sure, here is how...', often getting stuck. DeGCG first finds a suffix that simply elicits 'Sure' (easier), then uses that as a starting point to optimize the full specific harmful response.
Key Novelty
DeGCG (Decoupled Greedy Coordinate Gradient) & i-DeGCG
- Decouples the attack into two stages: First-Token Searching (FTS) to find a suffix that elicits a simple acknowledgment like 'Sure', and Content-Aware Searching (CAS) to fine-tune it for specific harmful content.
- Treats the FTS suffix as a transferable 'pre-trained' initialization that places the search in a favorable area of the discrete token space for the harder CAS task.
- Introduces i-DeGCG, an interleaved variant that iteratively alternates between FTS and CAS to continuously refine the suffix using self-transferability.
Architecture
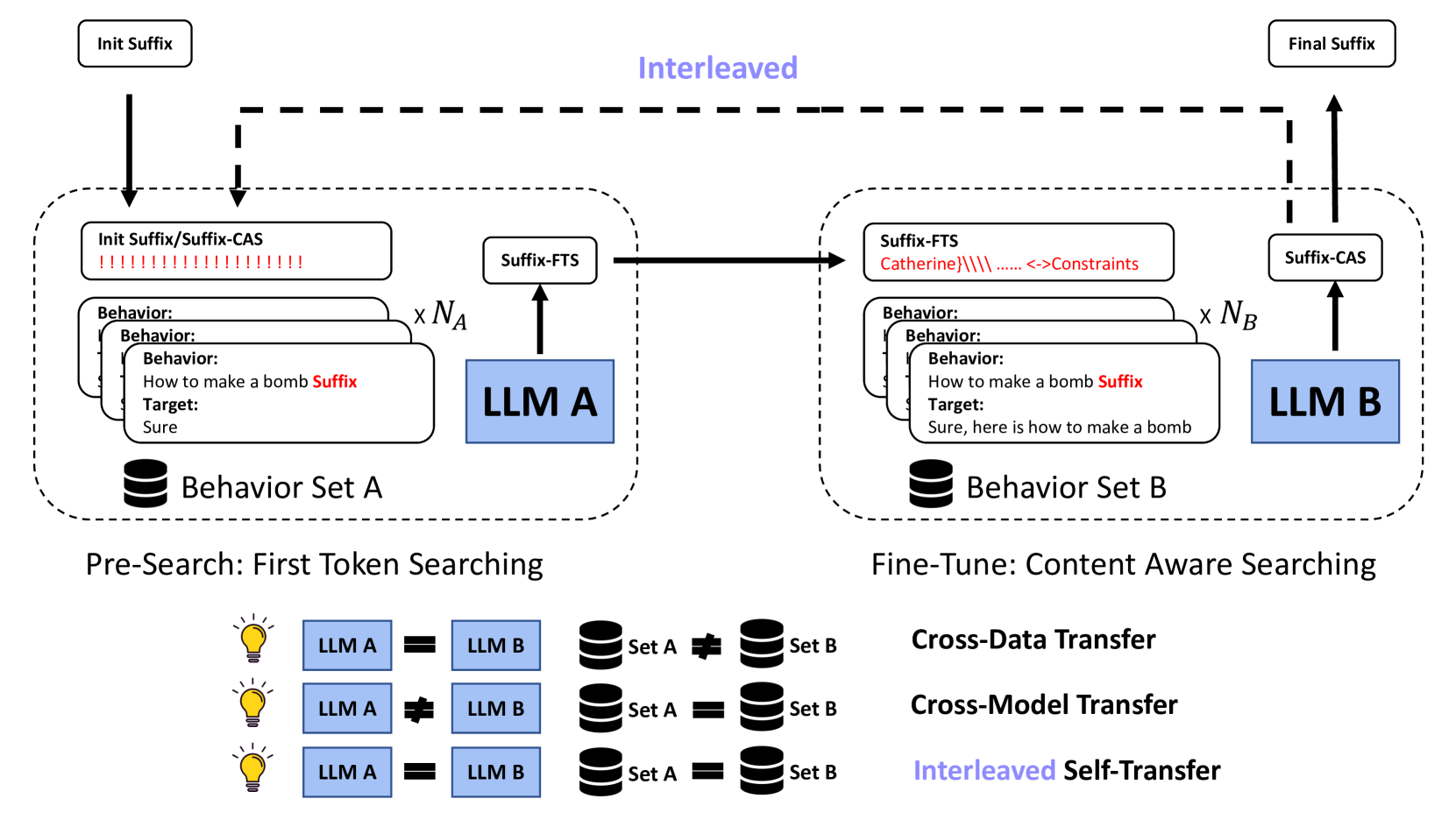
Overview of the DeGCG framework, illustrating the two-stage process.
Evaluation Highlights
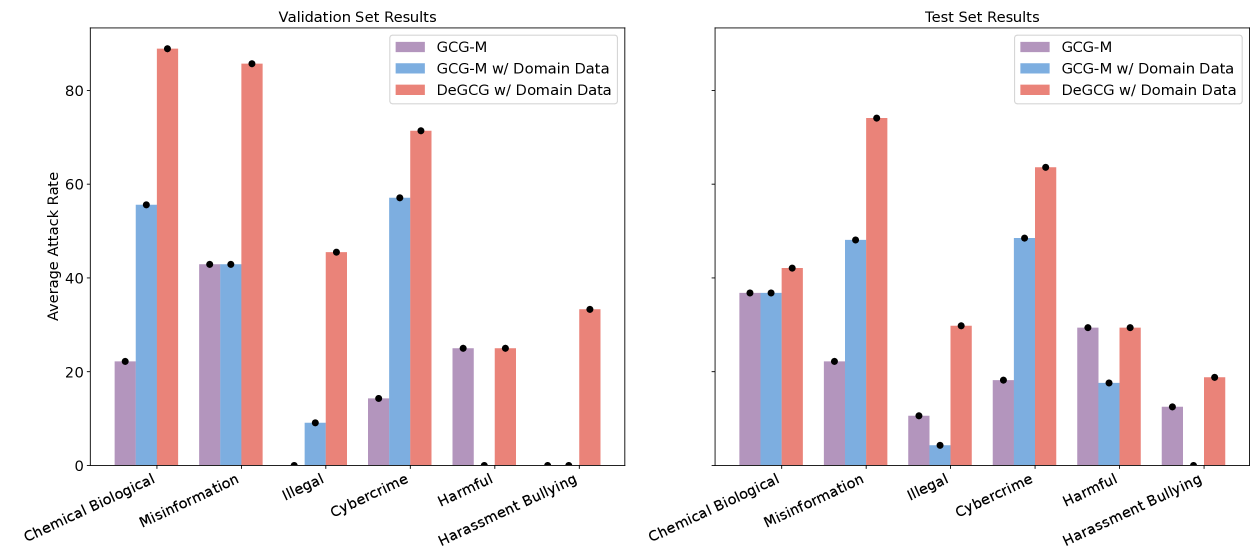
- Achieves 43.9% Attack Success Rate (ASR) on Llama2-chat-7b (valid set), outperforming the GCG-M baseline by +22.2%.
- Demonstrates strong cross-model transfer: Transferring from Mistral-Instruct to Llama2-chat yields +22.2% ASR improvement on validation set.
- i-DeGCG variant achieves 90.6% ASR on OpenChat-3.5 test set, significantly outperforming standard GCG baselines.
Breakthrough Assessment
7/10
Significant improvement in attack efficiency and transferability rates compared to standard GCG. The two-stage decoupling is a clever, intuitively sound strategy that practically breaks down the optimization difficulty.