📝 Paper Summary
Interpretability
Instruction Following
Inductive Biases
Transformer-based language models naturally learn to encode task-specific information by clustering hidden states corresponding to the same task, a process that evolves dynamically during training without explicit supervision.
Core Problem
The mechanisms underlying how Large Language Models (LLMs) successfully follow instructions are not well-understood, particularly how they internally represent different tasks.
Why it matters:
- LLMs show great instruction-following capabilities, but their internal decision-making processes remain opaque
- Understanding these mechanisms is crucial for explaining model behavior and improving alignment
- Current research focuses on training techniques (RLHF, instruction tuning) rather than analyzing the resulting internal representations
Concrete Example:
In a task like 'given a location, state its continent', the model must identify the function $f$ from the instruction. If the model cannot distinguish this task from a similar one sharing the same inputs (e.g., 'given a location, state its country'), it will fail. The paper investigates if the model groups these distinct tasks internally.
Key Novelty
Emergent Task Clustering in Hidden Space
- Demonstrates that Transformers spontaneously organize hidden states into clusters based on task identity, even when task labels are never explicitly provided during training
- Shows that this clustering is dynamic, improving throughout the training process until saturation, and becomes more pronounced in deeper layers of the network
Architecture
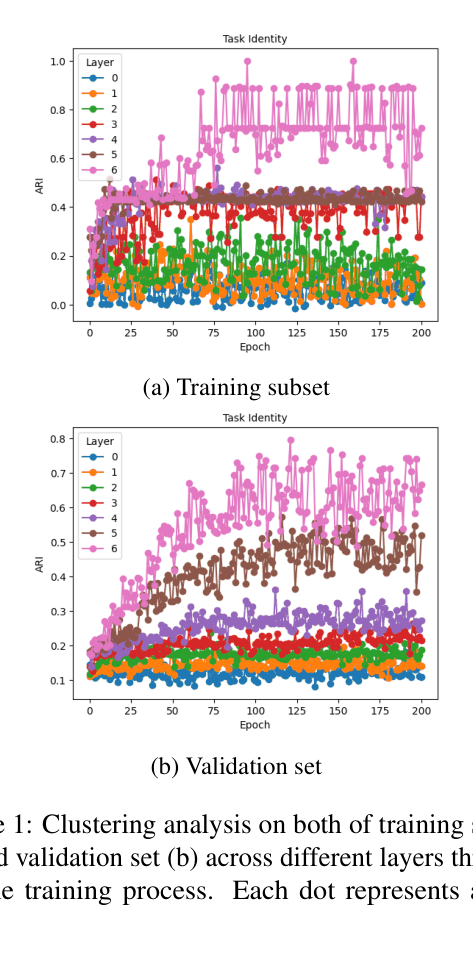
Scatter plots showing Clustering Performance (ARI) vs. Training Steps for different layers (Layer 0 to Layer 5) on both training and validation sets.
Evaluation Highlights
- Clustering performance (measured by Adjusted Rand Index) improves consistently throughout training on both training and validation sets
- Higher layers of the Transformer exhibit stronger clustering of task identities compared to the embedding layer (layer 0), which remains static
- The clustering effect generalizes to unseen validation instances, confirming it is a learned inductive bias rather than memorization
Breakthrough Assessment
4/10
Provides a specific, interesting insight into internal model representations using a simplified synthetic setting. While the finding is conceptually valuable for interpretability, the scope is limited to small synthetic experiments.