📝 Paper Summary
Remote Sensing Vision-Language Models (RS-VLMs)
Hallucination Mitigation in Multimodal LLMs
GeoReason aligns the internal reasoning of remote sensing models with their final decisions using a logic-driven dataset and a consistency-aware reinforcement learning strategy that penalizes logical drift.
Core Problem
Current remote sensing models suffer from 'logical hallucinations' where correct answers are derived from flawed reasoning or positional shortcuts rather than spatial evidence, undermining reliability in decision-making.
Why it matters:
- Decoupling between reasoning and answers makes models unreliable for strategic spatial tasks like functional zoning or capacity estimation.
- Perception-centric models often use 'pseudo-reasoning'—guessing the right answer for the wrong reasons—which prevents genuine high-level cognitive interpretation.
Concrete Example:
In a parking area utilization task, a baseline model might correctly select 'Sparsely used' but justify it by paradoxically claiming the area is 'near saturation' with 'numerous objects', revealing a complete disconnect between vision and logic.
Key Novelty
Consistency-Aware Reinforcement Learning with Logical Consistency Reward (LCR)
- Creates a dataset (GeoReason-Bench) by synthesizing geometric primitives into high-fidelity reasoning trajectories, ensuring ground truth logic exists.
- Uses a novel Logical Consistency Reward (LCR) during training that permutes option orders and checks if the model's reasoning trace leads to the same logical conclusion, penalizing reasoning that drifts despite identical evidence.
Architecture
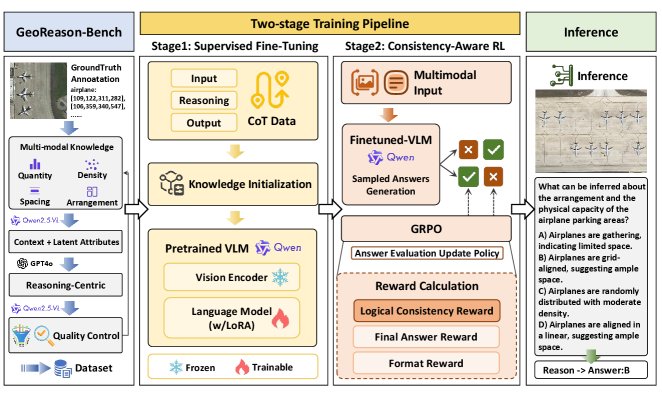
The overall architecture of GeoReason, illustrating the transition from perception to reasoning. It shows the data curation pipeline (left) and the two-stage training strategy (right).
Evaluation Highlights
- +19.65% improvement in Reasoning task accuracy over the base Qwen2.5-VL model on GeoReason-Bench.
- Achieves 51.27% Overall Accuracy, significantly outperforming baselines which struggle with logical grounding.
- Logical Consistency Reward (LCR) specifically drives Reasoning Accuracy from 36.49% (standard RL) to 43.51%, proving it effectively mitigates hallucinations.
Breakthrough Assessment
8/10
Strong methodological contribution in aligning CoT with outcomes via option permutation in RL. Addresses a critical, specific failure mode (pseudo-reasoning) in RS-VLMs with verifiable gains.
