📊 Experiments & Results
Evaluation Setup
Short-form QA evaluation where models generate answers constrained to <64 words. Evaluated against human-verified reference answers.
Benchmarks:
- CodeSimpleQA (Factual Question Answering) [New]
Metrics:
- F-score (Harmonic mean of Correct and Correct Given Attempted)
- Correct (CO)
- Not Attempted (NA)
- Incorrect (IN)
- Correct Given Attempted (CGA)
- Statistical methodology: Not explicitly reported in the paper
Key Results
| Benchmark | Metric | Baseline | This Paper | Δ |
|---|---|---|---|---|
| Results on the Chinese split of CodeSimpleQA show proprietary models leading, with RL post-training providing significant boosts to open models. | ||||
| CodeSimpleQA (Chinese) | F-score | 37.1 | 45.2 | +8.1 |
| CodeSimpleQA (Chinese) | F-score | 61.3 | 45.2 | -16.1 |
| Results on the English split generally show higher scores but similar ranking trends, with GPT-5 dominating. | ||||
| CodeSimpleQA (English) | F-score | 32.6 | 41.0 | +8.4 |
| CodeSimpleQA (English) | F-score | 62.9 | 41.0 | -21.9 |
| Analysis of RAG vs. RL shows trade-offs between dynamic and static knowledge. | ||||
| CodeSimpleQA (Post-2024 subset) | Score | 24.0 | 68.0 | +44.0 |
Experiment Figures
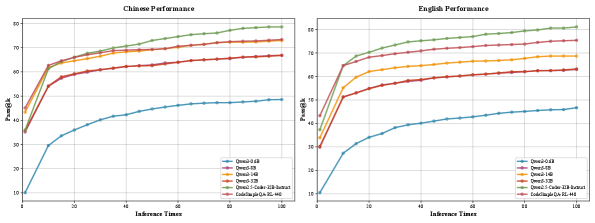
Test-time scaling (Pass@k) performance as inference budget increases from 1 to 100 attempts.
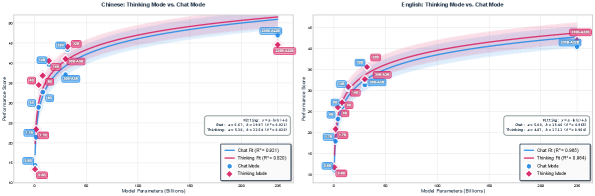
Scaling laws comparing 'Thinking' (reasoning) models vs. 'Chat' (standard) models across parameters.
Main Takeaways
- Proprietary models (GPT-5, o3) currently dominate factual code QA, but open weights models like DeepSeek-V3 are competitive.
- Reinforcement Learning (RL/GRPO) significantly improves factual accuracy over simple Supervised Fine-Tuning (SFT), proving the value of factuality-aware alignment.
- Thinking models (with reasoning traces) scale logarithmically better with size than standard chat models, suggesting reasoning helps factuality.
- RAG is superior for rapidly changing knowledge (libraries, APIs), while SFT/RL is better for stable core concepts; a hybrid approach is likely optimal.