📝 Paper Summary
Modularized RAG pipeline
Parameter-efficient fine-tuning (PEFT)
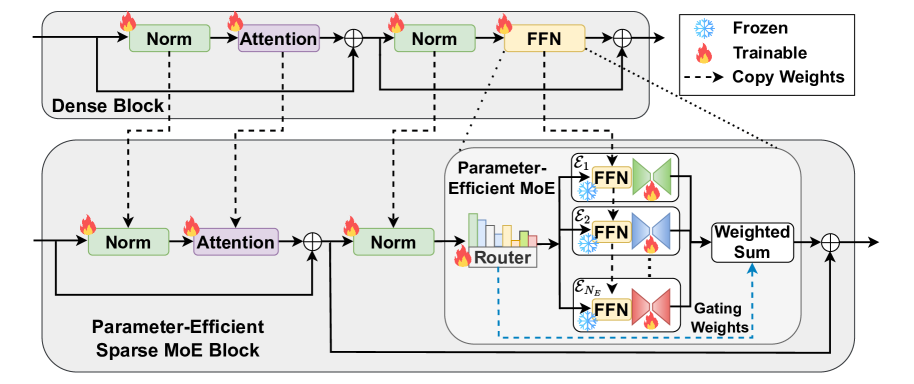
Open-RAG transforms dense open-source LLMs into parameter-efficient sparse Mixture of Experts models trained to navigate distracting retrieved contexts and dynamically decide when to retrieve.
Core Problem
Existing open-source RAG models struggle with reasoning over noisy or misleading retrieved documents and lack efficient mechanisms to determine when retrieval is actually necessary.
Why it matters:
- Retrievers are imperfect and often return irrelevant or distracting passages that confuse standard LLMs
- Current adaptive retrieval methods often rely on slow, repetitive external model calls or iterative generation, increasing latency
- Small open-source models generally lack the reasoning capabilities of proprietary giants like GPT-4 when handling complex multi-hop queries
Concrete Example:
In a multi-hop query about a specific entity, a standard RAG model might retrieve a passage about a similar but different entity (a distractor). Instead of ignoring it, the model hallucinates an answer by merging facts from the distractor, whereas Open-RAG identifies the distractor as 'Irrelevant' and produces a grounded response.
Key Novelty
Parameter-Efficient Sparse MoE for RAG + Hybrid Adaptive Retrieval
- Transforms a dense LLM into a sparse Mixture of Experts (MoE) by upcycling the Feed-Forward Networks (FFN) using parameter-efficient adapters, allowing specialized experts for different reasoning complexities (e.g., single vs. multi-hop)
- Trains the model to generate special reflection tokens (Retrieval, Relevance, Grounding, Utility) that guide the generation process and filter out misleading distractors in the retrieved context
- Uses a hybrid adaptive retrieval strategy that combines generated reflection tokens with model confidence scores to skip retrieval when the model is confident, balancing speed and accuracy
Architecture
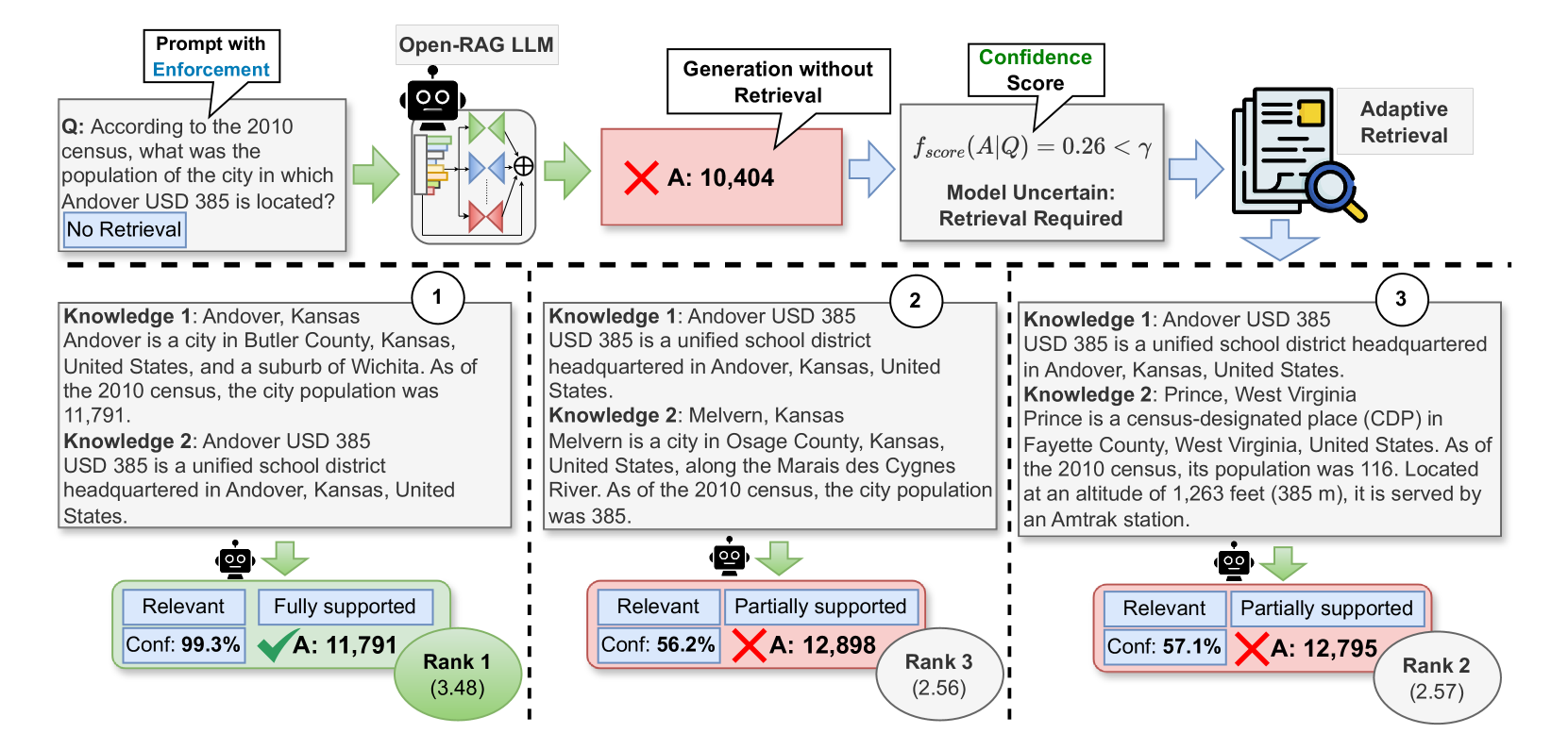
Overview of the Open-RAG inference framework. It shows the process from input query, to the adaptive retrieval decision, retrieval of documents (if needed), parallel processing of documents by the MoE LLM to generate reflection tokens and answers, and the final ranking step.
Evaluation Highlights
- Open-RAG (Llama2-7B base) outperforms ChatGPT-RAG and matches/exceeds proprietary Self-RAG and Command R+ on multiple benchmarks
- Achieves higher factual accuracy than 104B parameter Command R+ on specific tasks despite being a 7B parameter model
- Outperforms standard Llama2-7B baselines by significant margins on complex multi-hop reasoning datasets like HotpotQA and 2WikiMultiHopQA
Breakthrough Assessment
8/10
Significantly boosts open-source RAG performance by cleverly combining sparse MoE upcycling with self-reflection, allowing 7B models to rival much larger proprietary systems.