📝 Paper Summary
Modularized RAG pipeline
Fact-Checking
Contrastive Fact-Checking Reranker (CFR) improves fact-checking retrieval by fine-tuning a dense retriever on evidence pairs distilled from GPT-4 relevance judgments and answer equivalence metrics.
Core Problem
Retrieving evidence for fact-checking is difficult because relevant documents often address claims obliquely or require inference, causing standard retrievers to fail even when topical documents are found.
Why it matters:
- Standard retrieval bottlenecks fact-checking pipelines; without the right evidence, downstream veracity judgments are impossible
- Existing dense retrievers are optimized for simple factoid questions (like NQ) and struggle with the nuanced, open-ended queries required for complex real-world claims
- Gold-standard evidence is scarce and sometimes lacks lexical overlap with the claim, making supervised training difficult
Concrete Example:
For the claim 'How was REGN-COV2 developed?', a standard retriever selects a topical document about clinical trials. The proposed CFR model correctly selects a document about 'mice' and 'human antibodies' because it learns the subquestion implies checking for 'fetal tissue' usage, even though the document doesn't explicitly mention the claim's context.
Key Novelty
Contrastive Fact-Checking Reranker (CFR)
- Fine-tunes a dense retriever (Contriever) using contrastive learning on dataset-specific hard negatives and positives derived from weak supervision
- Generates supervision signals by distilling GPT-4 relevance judgments and measuring answer equivalence (LERC) between retrieved documents and gold answers
- Constructs training pairs that encourage the retriever to prefer documents supporting the correct answer, even if they lack high lexical overlap with the query
Architecture
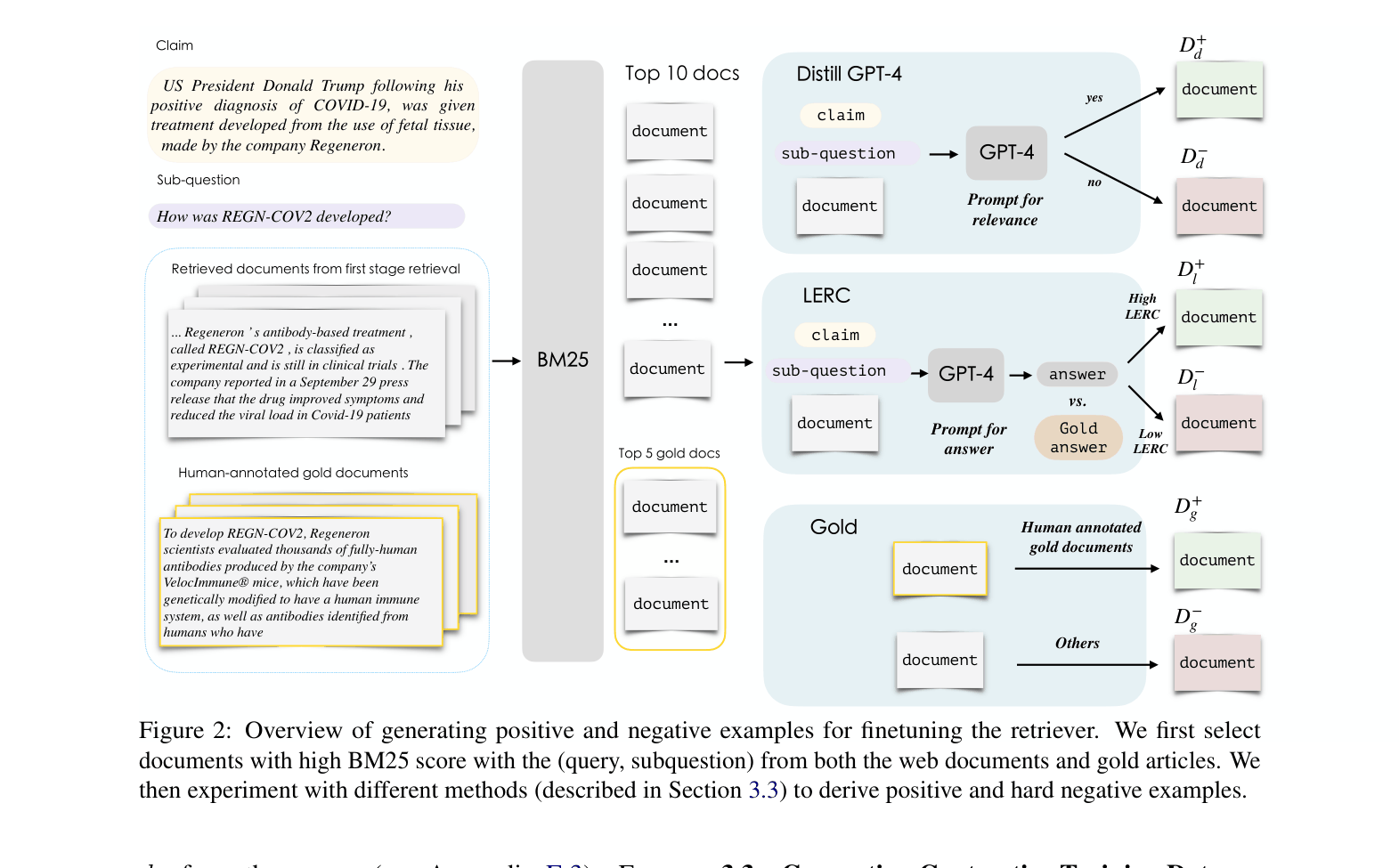
The pipeline for generating positive and negative examples for contrastive fine-tuning. It illustrates three data sources: distilling GPT-4 relevance, LERC answer equivalence, and gold annotations.
Evaluation Highlights
- +6% improvement in veracity classification accuracy on the AVeriTeC dataset compared to the baseline Contriever
- +9% increase in Top-1 document relevance on AVeriTeC, as determined by GPT-4 relevance judgments
- Achieves 0.79 MRR on a synthetic dataset requiring reasoning, significantly outperforming baseline Contriever (0.68 MRR)
Breakthrough Assessment
7/10
Strong practical improvements on complex fact-checking by leveraging LLM distillation for retriever training. Demonstrates that answer-equivalence is a better signal than gold-document IDs for retrieval.
