📝 Paper Summary
Modularized RAG pipeline
Adaptive Retrieval
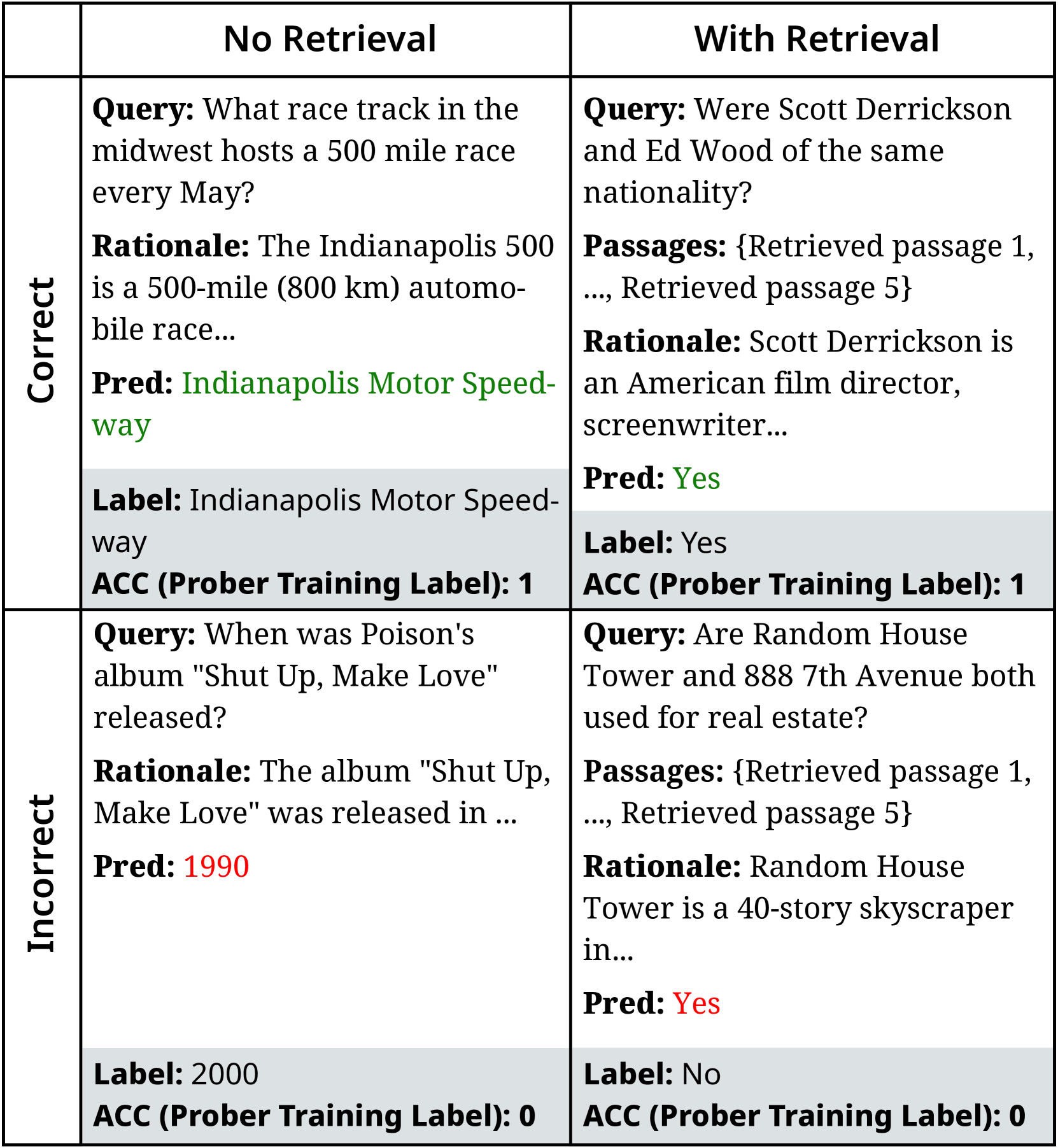
Probing-RAG attaches lightweight classifiers to a language model's intermediate layers to analyze hidden states and dynamically decide whether external document retrieval is necessary for a given query.
Core Problem
Standard RAG systems retrieve documents for every query, which is inefficient for simple questions the model already knows and can lead to knowledge conflicts or hallucinations when irrelevant documents are retrieved.
Why it matters:
- Unnecessary retrieval increases computational cost and latency in real-world applications
- Retrieving irrelevant context can confuse the model, causing it to override correct internal knowledge with incorrect external information (knowledge conflicts)
- Existing adaptive methods rely on external classifiers that ignore the model's own confidence or rely solely on final output probabilities, missing internal reasoning signals
Concrete Example:
For the question 'What is the capital of France?', a standard RAG pipeline might retrieve documents about French history unnecessarily. Adaptive-RAG might use a BERT classifier to guess complexity but fails to know if the specific generator (e.g., Gemma-2B) *actually* knows the answer, potentially triggering retrieval when not needed.
Key Novelty
Internal State Probing for Retrieval Decisions
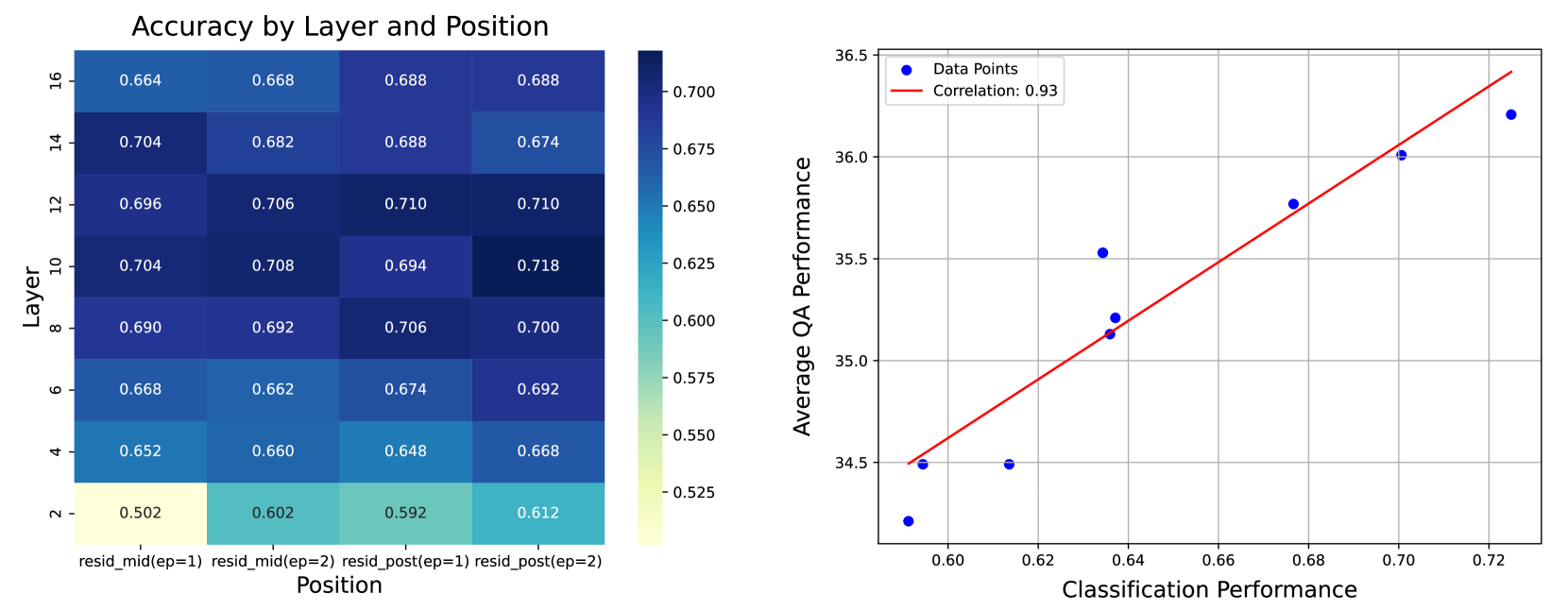
- Instead of using an external classifier or output log probabilities, this method inspects the 'hidden states' (internal numerical representations) of the LLM while it generates a preliminary answer
- A tiny binary classifier (prober) is trained to look at these internal states and predict if the generated answer is likely correct without retrieval; if not, it triggers the retrieval engine
Architecture
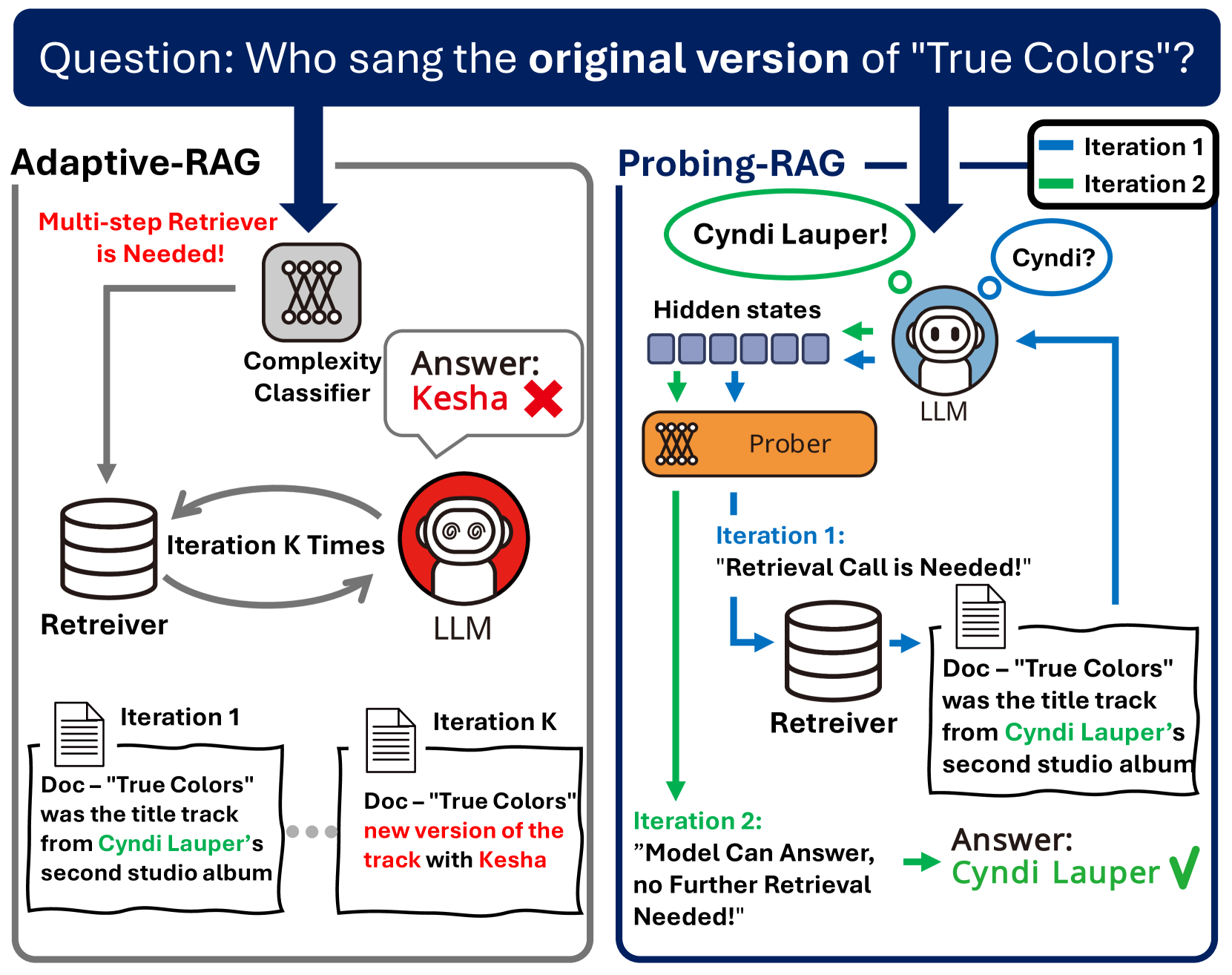
The Probing-RAG inference pipeline. It illustrates how the hidden states from the LLM are fed into a Prober to decide on retrieval.
Evaluation Highlights
- Reduces retrieval frequency by approximately 50% on average across five open-domain QA datasets while maintaining or improving accuracy
- Achieves +6.59% accuracy improvement over 'No Retrieval' and +8.35% over 'Single-step' retrieval baselines on average
- The prober is extremely lightweight (5 MB), which is 2,000 times smaller than the external classifier model used in Adaptive-RAG (T5-large)
Breakthrough Assessment
7/10
Offers a highly efficient mechanism for adaptive RAG by leveraging internal states, significantly reducing overhead compared to external classifier approaches. However, reliance on specific layer positioning and threshold tuning may require adaptation for different model architectures.