📝 Paper Summary
Tool retrieval
Benchmark datasets
Query alignment
MTRB is a new benchmark for retrieving tools from massive repositories, accompanied by a QTA framework that aligns user queries with tool documentation using reinforcement learning on limited data.
Core Problem
Existing retrieval methods struggle with massive tool repositories due to context length limits and the semantic gap between user queries and technical tool documentation.
Why it matters:
- Real-world applications involve thousands of tools (e.g., >100,000 characters for documentation), far exceeding the context windows of many LLMs (e.g., Llama-2's 4096 tokens)
- Standard fine-tuning methods like Sentence-BERT require large annotated datasets, which are scarce for new tool domains
- Current benchmarks focus on tool usage (planning/calling) rather than the preliminary step of retrieving the correct tools from a large database
Concrete Example:
A user query 'give me a movie cover from the Harry Potter collection' requires coordinating multiple tools like 'GET /search/collection', 'GET /collection/{id}', and 'GET /movie/{id}/images'. Standard retrievers fail to link the abstract request to these specific API endpoints without extensive training data.
Key Novelty
Query-Tool Alignment (QTA) with Direct Preference Optimization
- Uses an LLM to rewrite user queries into forms that better match tool documentation, bridging the semantic gap
- Aligns these rewrites using Direct Preference Optimization (DPO) derived from retrieval ranking feedback, rather than requiring a separate reward model
- Specifically designed for low-resource settings, showing effectiveness with as few as one annotated training sample
Architecture
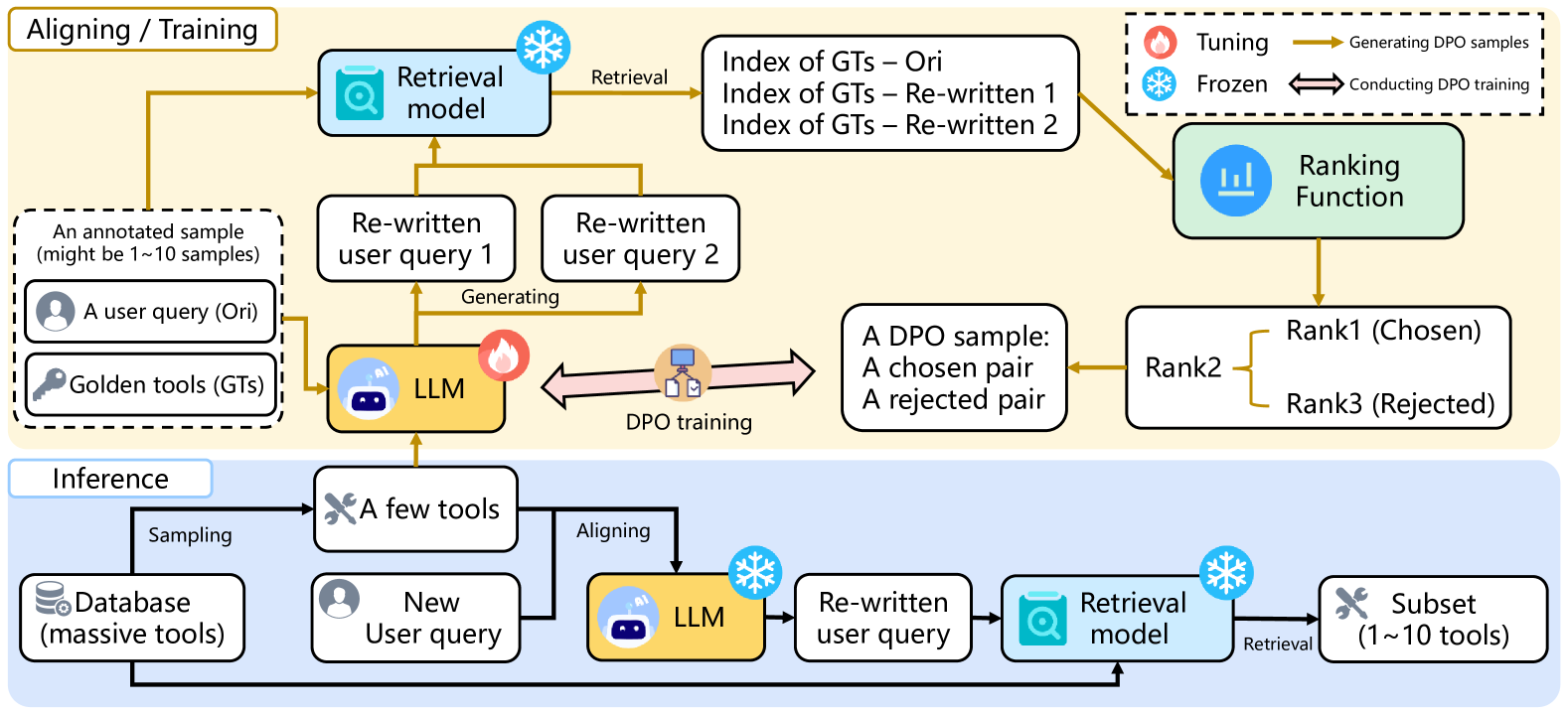
The QTA framework pipeline, including query rewriting, retrieval ranking, and the DPO training process.
Evaluation Highlights
- +93.28% improvement in Sufficiency@5 on the MTRB-RestBench subset compared to baseline methods
- Achieves 78.53% improvement in Sufficiency@5 on MTRB-RestBench using just a single annotated training sample
- Consistently outperforms state-of-the-art models in top-5 and top-10 retrieval tasks across the full MTRB benchmark
Breakthrough Assessment
7/10
Significant improvements in low-resource settings and a necessary new benchmark for massive tool retrieval. The approach is data-efficient but relies on existing retrieval backends.