📝 Paper Summary
Data Preprocessing (DP) with LLMs
Instruction Tuning for Structured Data
Jellyfish instruction-tunes small, local LLMs (7B–13B) specifically for data preprocessing tasks using knowledge injection and reasoning distillation, offering a secure alternative to cloud-based GPT APIs.
Core Problem
Existing LLM-based data preprocessing solutions rely on external APIs (like GPT-4), creating data privacy risks and high costs, while non-LLM methods lack generalization across different tasks.
Why it matters:
- Data breach concerns prevent sensitive industries (finance, healthcare) from using powerful API-based LLMs for cleaning data
- Specialized domains often require custom fine-tuning which is impossible or prohibitively expensive with closed-source APIs
- Previous non-LLM methods are task-specific, requiring separate models for error detection, matching, and imputation
Concrete Example:
In Entity Matching, a standard model might fail to match 'Sequoia American Amber Ale' and 'Aarhus Cains Triple A' because it lacks reasoning about brewery variations. Jellyfish incorporates reasoning data to explicitly explain why product names differ, improving decision accuracy.
Key Novelty
Universal Local DP Solver with Reasoning Distillation
- Instruction-tunes open local models (Mistral, Llama 3) on a unified collection of four distinct preprocessing tasks (Error Detection, Imputation, Schema/Entity Matching)
- Injects domain knowledge (e.g., 'missing values are not matches') directly into prompts during tuning to prevent common failures
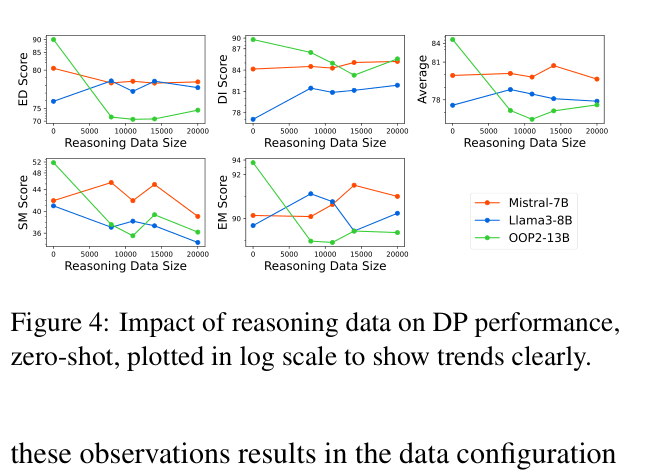
- Distills reasoning capabilities from a larger teacher model (Mixtral-8x7B) so the smaller local model can explain its preprocessing decisions
Architecture
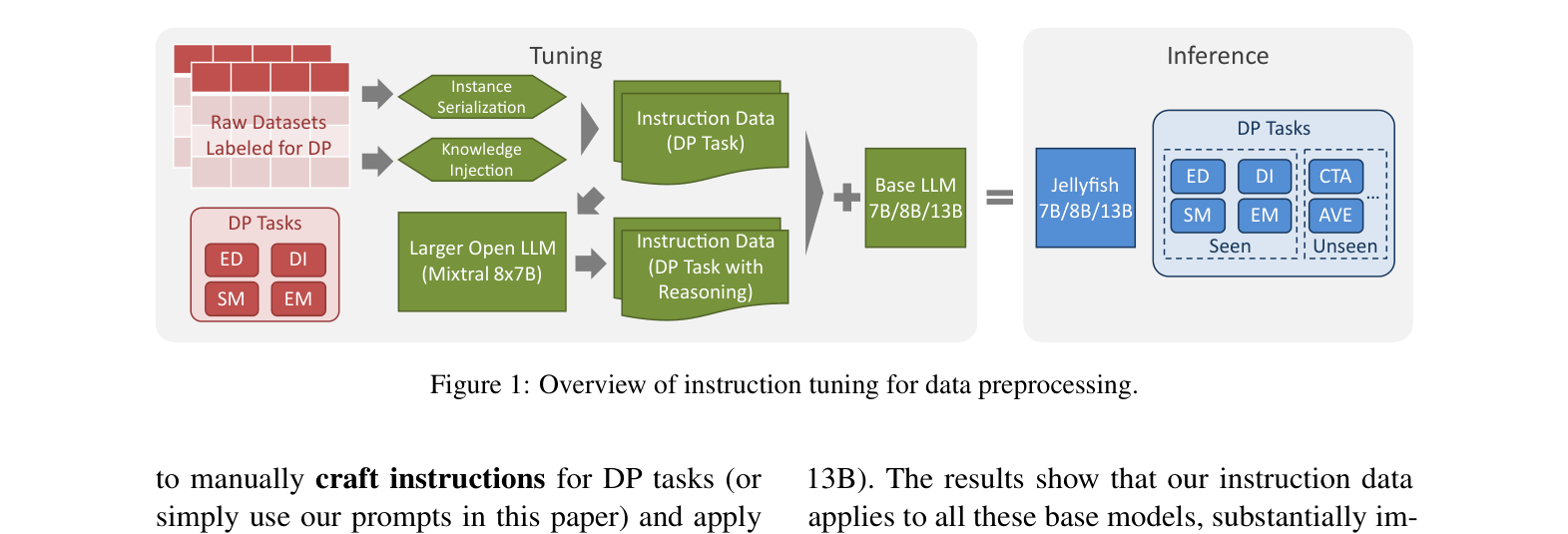
Overview of the instruction tuning pipeline: preparing data from raw datasets, creating instruction prompts with knowledge injection and reasoning, tuning base LLMs, and inference on seen/unseen tasks.
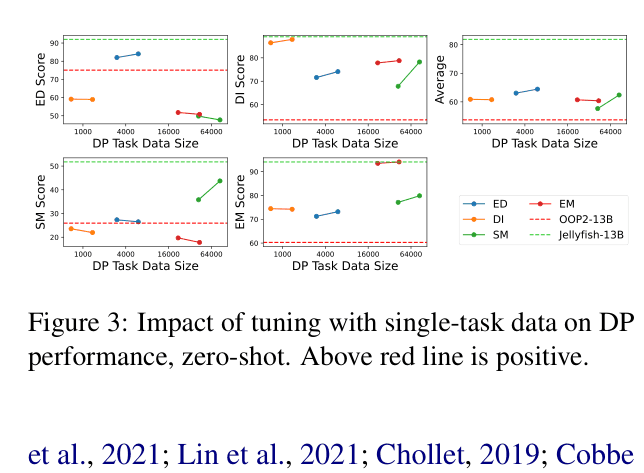
Evaluation Highlights
- Jellyfish-13B outperforms previous best non-LLM methods on all 19 tested datasets (seen and unseen), establishing a new state-of-the-art for local models
- Jellyfish-13B achieves 86.02 average score across seen tasks, surpassing GPT-3.5 (84.17) and rivaling GPT-4 (not directly averaged but close on specific tasks)
- Zero-shot generalization to unseen tasks (Column Type Annotation) improves by +25.6 points (Jellyfish-13B vs base model), showing transfer learning capability
Breakthrough Assessment
8/10
Strong practical contribution: demonstrates that small, secure local models can beat GPT-3.5 and specialized non-LLM baselines on dirty data tasks. The reasoning distillation and knowledge injection are effective adaptations.