📝 Paper Summary
Large Language Model Pre-training
Knowledge Distillation
Model Compression
Pre-training distillation (transferring knowledge from a teacher LLM to a student LLM during pre-training via logits) consistently improves performance compared to standard language modeling, with optimal gains achieved by specific logits truncation and loss scheduling strategies.
Core Problem
Standard pre-training of smaller LLMs relies solely on hard labels (next-token prediction), missing the rich semantic information available in the probability distributions of larger, more capable teacher models.
Why it matters:
- Training smaller, efficient LLMs is crucial for deployment, but they often lack the reasoning capabilities of larger models.
- Post-training distillation is common, but applying distillation during the expensive and critical pre-training phase is underexplored due to massive data and computational costs.
- Storing full logits for pre-training corpora (trillions of tokens) is storage-prohibitive (petabytes), requiring efficient compression techniques.
Concrete Example:
Storing full float32 logits for a 150k vocabulary over 100B tokens would require ~58.6 PB of disk space. Without efficient truncation (like Top-p-K), pre-training distillation is practically impossible due to storage constraints.
Key Novelty
Systematic Design Space Exploration for Pre-training Distillation (PD)
- Proposes a 'Pre-training Distillation' (PD) framework where a student LLM learns from a teacher's logits on massive unlabeled corpora, not just instruction data.
- Identifies efficient logits storage techniques (Top-p + Top-k truncation) that reduce storage by ~4000x without hurting performance.
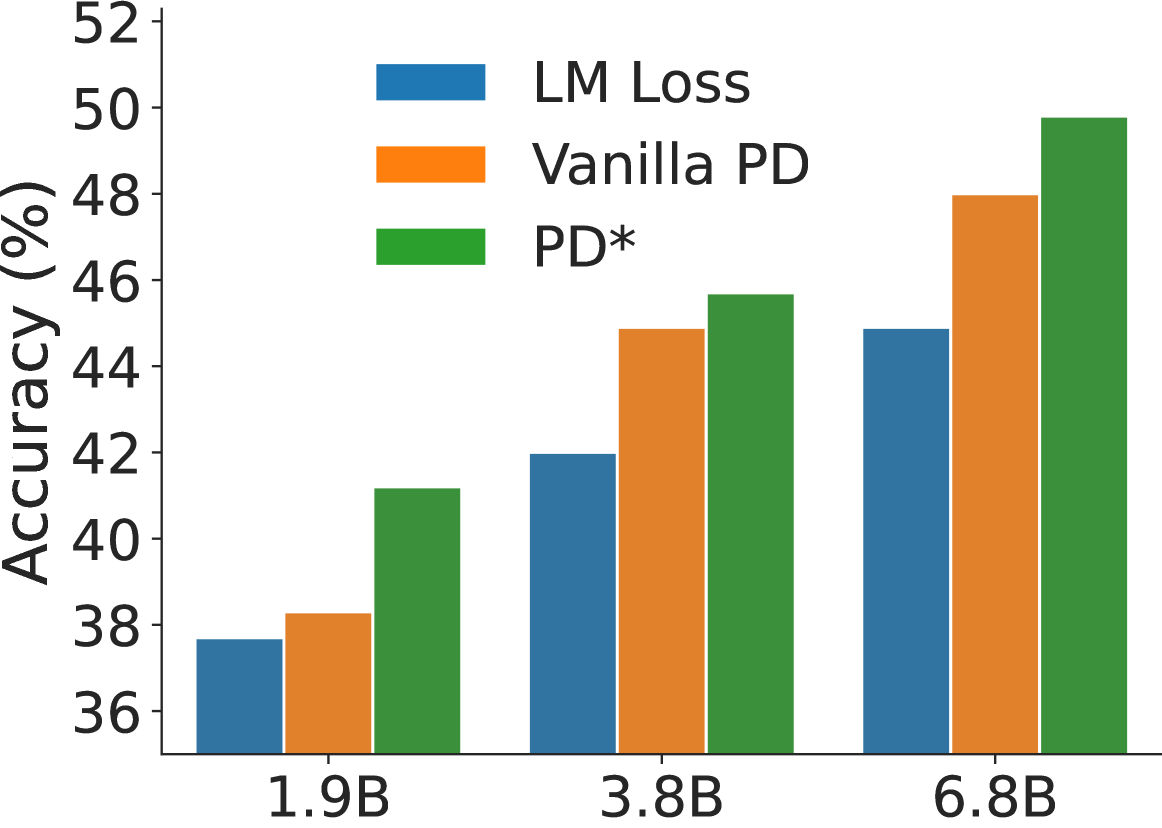
- Discovers that a dynamic mixture of distillation loss and standard language modeling loss (Warmup-Stable-Decay schedule) outperforms static mixing.
Architecture
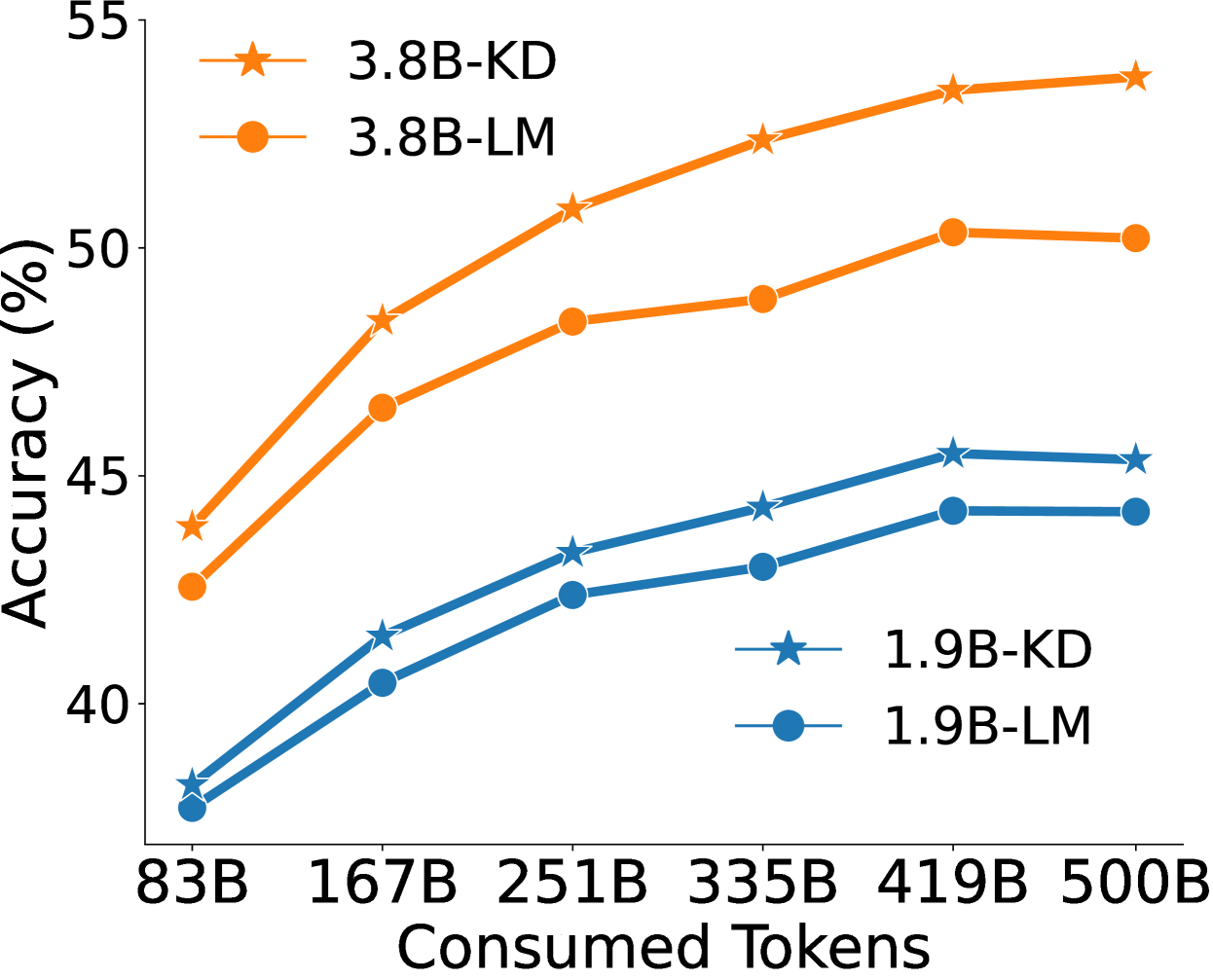
Comparison of validation loss curves and downstream performance between Baseline (LLM-LM) and Pre-training Distillation (PD/LLM-KD).
Evaluation Highlights
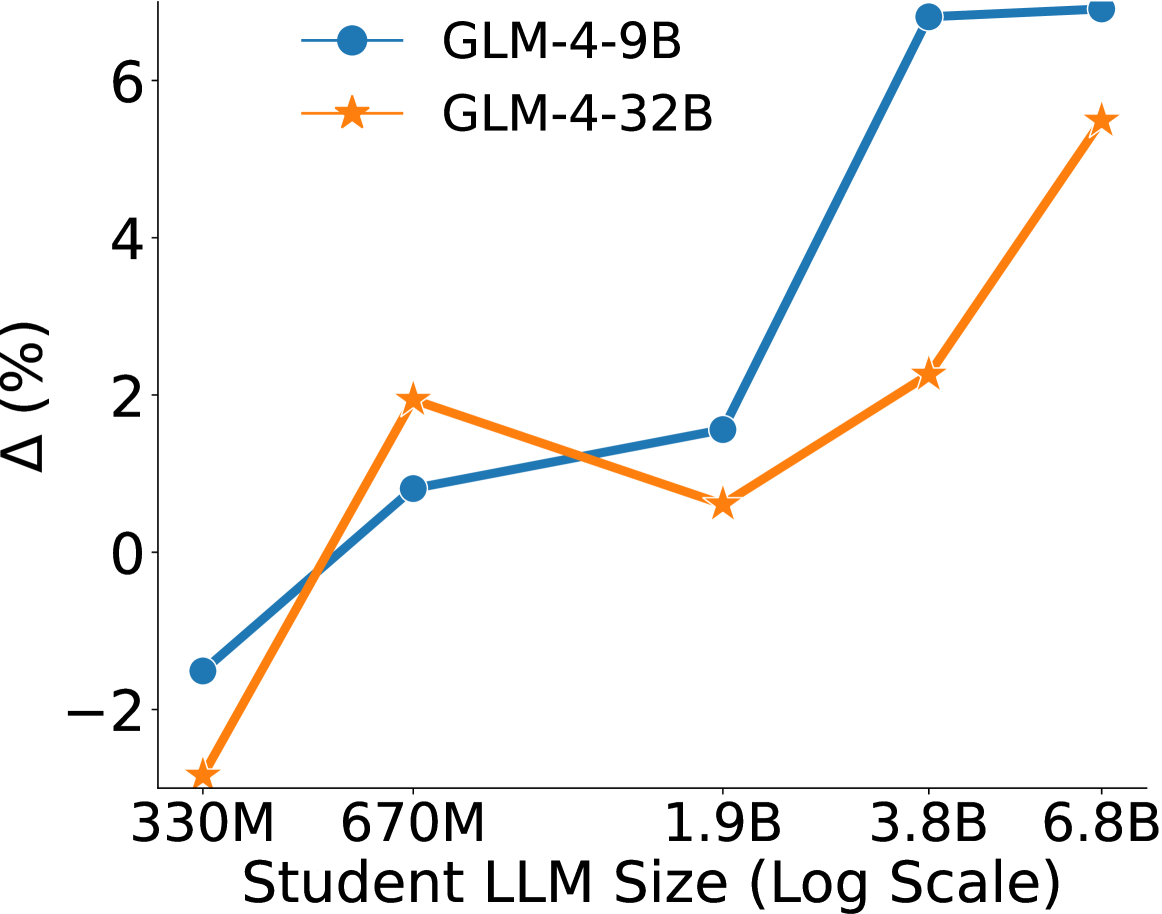
- +1.6% average improvement across 8 benchmarks (e.g., MMLU, GSM8k) for a 1.9B student distilled from GLM-4-9B on 100B tokens compared to standard pre-training.
- Efficient logits truncation (Top-p=0.95 followed by Top-k=100) reduces storage by 4,000x (58.6 PB → 15 TB) while maintaining distillation benefits.
- +8.0% improvement in average score using a Warmup-Stable-Decay (WSD) scheduler for the distillation loss weight compared to the baseline LM pre-training.
Breakthrough Assessment
7/10
Provides the first comprehensive empirical study on pre-training distillation for LLMs, offering practical recipes for scaling (storage reduction, loss scheduling). While the fundamental concept of KD is old, the application to LLM pre-training scale is significant.