📝 Paper Summary
Video Temporal Grounding (VTG)
Video Large Language Models (Video-LLMs)
Mixture-of-Experts (MoE)
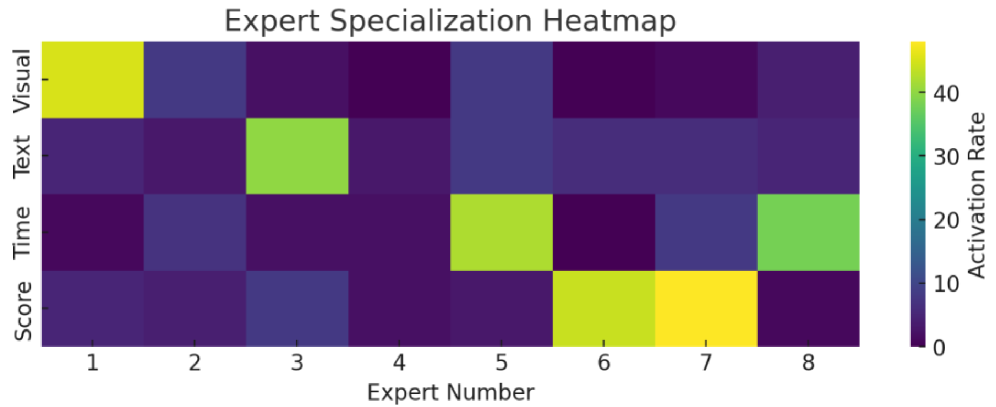
TimeExpert decomposes video grounding tasks by dynamically routing specific token types (timestamps, saliency scores, text) to specialized experts within a Mixture-of-Experts architecture.
Core Problem
Existing Video-LLMs process distinct task tokens (temporal boundaries, saliency scores, captions) through a single shared pathway, failing to specialize for the fundamentally different nature of these subtasks.
Why it matters:
- Humans effortlessly recognize actions but struggle with precise second-level temporal boundaries, a gap current models fail to bridge effectively
- Standard parameter-sharing in Video-LLMs causes task interference, where learning to generate text might degrade the precision of timestamp prediction
- Traditional grounding models cannot handle multiple subtasks concurrently, requiring separate models for retrieval, captioning, and highlighting
Concrete Example:
In a cooking video, a model must simultaneously predict the exact start/end time of 'frying bacon', assign a saliency score to that segment, and generate a caption. A standard LLM treats the timestamp '00:45' and the word 'bacon' identically, leading to imprecise localization.
Key Novelty
TimeExpert (Task-Aware MoE for VTG)
- Replaces the monolithic LLM decoder with a Mixture-of-Experts (MoE) architecture that specializes different experts for different output types (timestamps vs. text)
- Introduces a dynamic routing mechanism that considers the 'type' of token being processed (e.g., score token vs. time token) to direct it to the most relevant expert
- Uses a token-adaptive strategy that adds new experts if current ones are insufficient and prunes redundant ones to maintain efficiency
Architecture
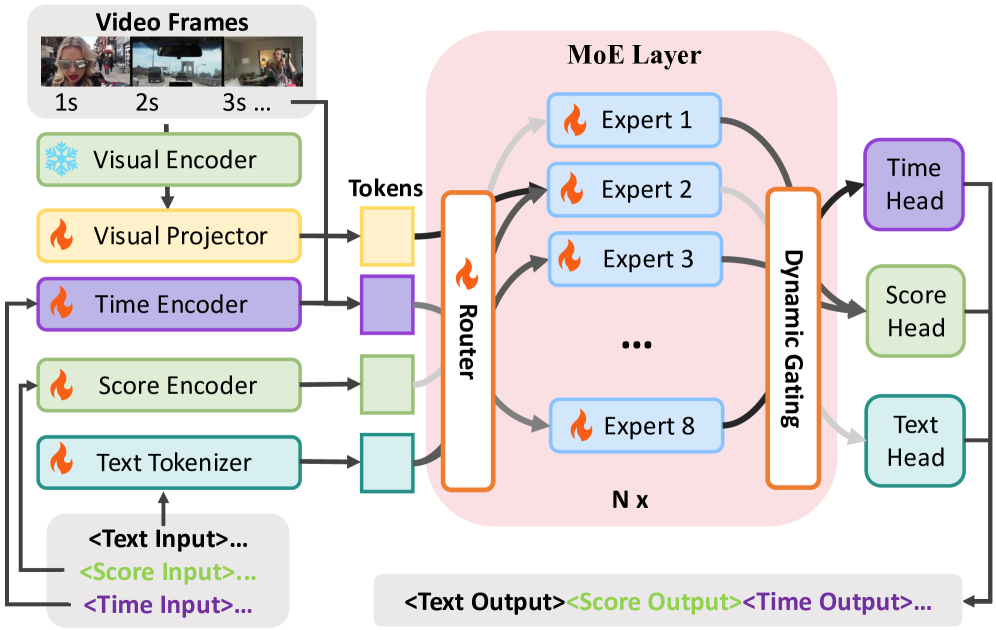
The TimeExpert framework, illustrating the MoE decoder with Task-aware Dynamic Gating and Token-adaptive Routing.
Evaluation Highlights
- +2.8% mAP (IoU=0.5) and +4.2% HIT@1 improvement on QVHighlights over the state-of-the-art TRACE model
- +2.5% Recall@1 (IoU=0.5) on Charades-STA Moment Retrieval compared to TRACE
- Achieves superior performance with fewer activated parameters (approx. 3.5B-4.8B) compared to 7B dense baselines like TimeChat and TRACE
Breakthrough Assessment
8/10
Significant architectural shift for Video-LLMs by explicitly decoupling task tokens via MoE. Strong empirical gains across multiple VTG tasks with improved efficiency.