📝 Paper Summary
Memory organization
Agent-based simulation
KGLA enhances LLM-based user agents by translating knowledge graph paths into natural language rationales, enabling agents to understand why users interact with items and build more precise profile memories.
Core Problem
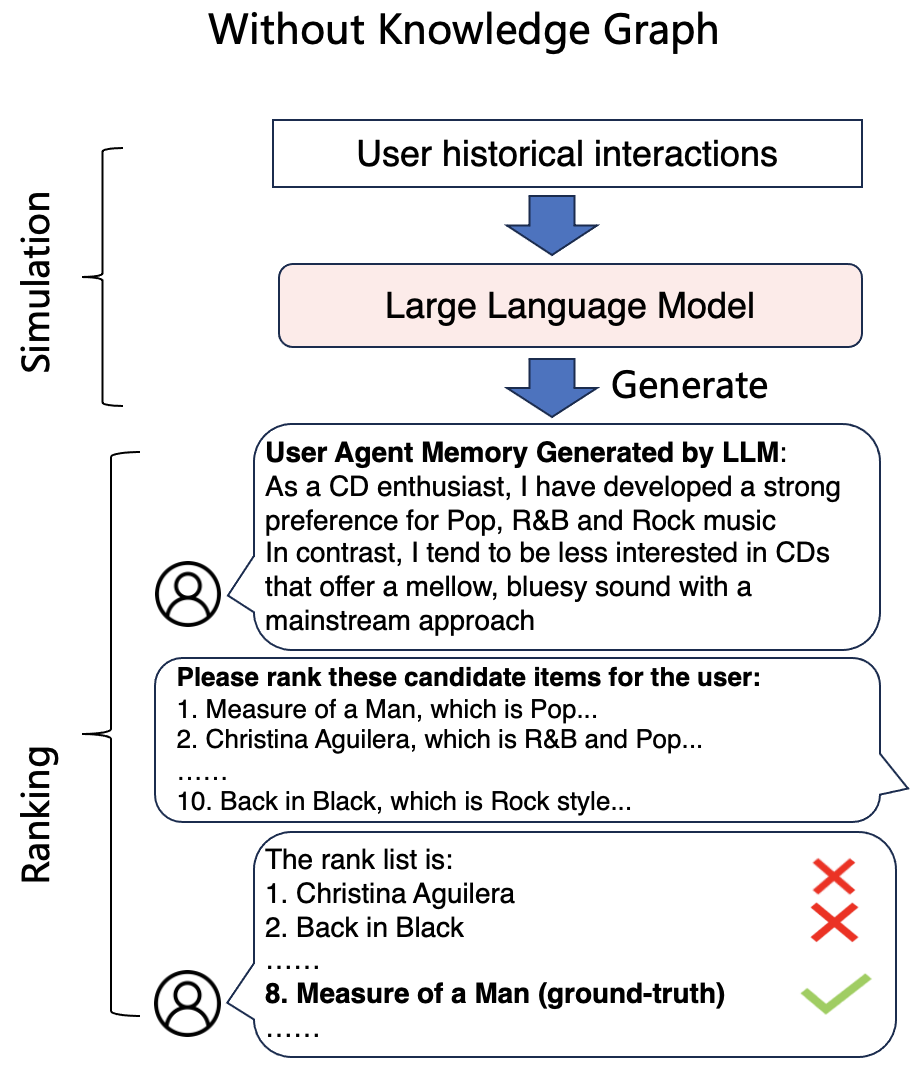
Current language agent-based recommendation simulators rely on superficial descriptions without rationalizing interactions, leading to generic, inaccurate user profiles that fail to capture specific preferences.
Why it matters:
- Inadequate memory profiles cause LLM agents to struggle with identifying precise user preferences, resulting in irrelevant recommendations.
- Existing simulation approaches neglect the underlying reasons (rationales) for user-item interactions, missing the 'why' behind behavior.
- Providing sufficient information for agents to build rational and precise user profiles remains an unresolved challenge in simulation-oriented recommendation.
Concrete Example:
A user might interact with a 'CD' because they like a specific feature mentioned in its description. Without KGLA, the agent only sees the interaction. With KGLA, the agent sees the path 'User mentions features -> describe_as -> CD', explicitly explaining the preference rationale.
Key Novelty
Knowledge Graph Enhanced Language Agents (KGLA)
- Treats recommendation reasoning as a 'path-to-text' problem where KG paths between users and items are translated into natural language explanations.
- Uses an inductive approach where the agent analyzes existing paths between known user-item pairs to reflect on preferences, rather than traversing the graph to find unknown entities.
- Incorporates translated KG paths (2-hop and 3-hop) into the agent's reflection phase to update memory with explicit rationales for likes/dislikes.
Architecture
The KGLA framework architecture, illustrating the flow from Knowledge Graph path extraction to LLM agent simulation.
Evaluation Highlights
- Achieves 95.34% relative improvement in NDCG@1 on the Amazon-Book benchmark compared to the previous best baseline (AgentCF).
- Consistent improvements across three datasets (Amazon-Book, ML-1M, Yelp) with relative NDCG@1 gains of 33.24% to 95.34%.
- Outperforms both traditional deep learning models (SASRec, LightGCN) and existing LLM-based agent methods (RecAgent, AgentCF).
Breakthrough Assessment
8/10
Significant performance jumps (up to 95%) demonstrate the high value of grounding LLM agents in structured knowledge for simulation. It effectively bridges the gap between symbolic KG reasoning and LLM-based user profiling.