📝 Paper Summary
LLM Pre-training
Korean Language Models
Data Curation
Mi:dm 2.0 is a bilingual LLM engineered through rigorous data filtering and synthetic augmentation to internalize Korean societal values and reasoning patterns rather than just linguistic translation.
Core Problem
Existing Korean LLMs are often trained on low-quality or insufficient data, leading to hallucinations, unnatural phrasing, and a lack of alignment with Korean cultural norms.
Why it matters:
- Models trained on generic web data often produce emotionally incongruent or culturally insensitive responses in high-stakes local applications
- The scarcity of high-quality Korean corpora compared to English creates a structural performance gap for non-English languages
- Prior models frequently revert to English or hallucinate when faced with specific Korean cultural contexts due to data misalignment
Concrete Example:
Existing models might translate a query about 'King Sejong' literally or factually incorrectly due to poor data, whereas Mi:dm 2.0 is trained on curated historical and cultural datasets to ensure culturally accurate outputs.
Key Novelty
Korea-centric Data Pipeline & Depth-up Scaling
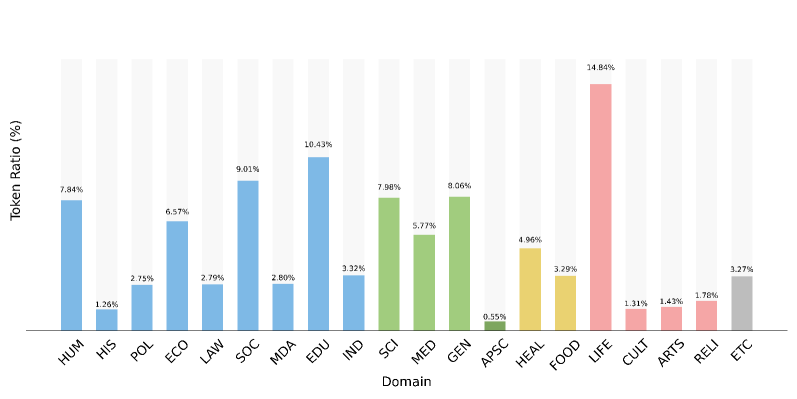
- Implements a rigorous 'Korea-centric' data pipeline that prioritizes cultural alignment and reasoning over raw token count, heavily supplementing organic data with synthetic textbook-style rewrites
- Utilizes Depth-up Scaling (DuS) to efficiently expand an 8B base model into an 11.5B model by leveraging learned representations without training from scratch
Architecture
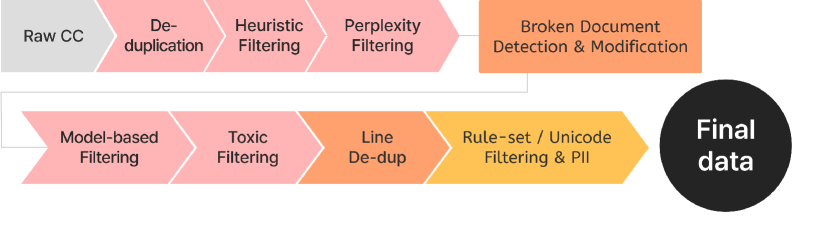
The 8-stage data filtering pipeline for Korean web data
Evaluation Highlights
- Achieves top-tier zero-shot results on KMMLU (Korean Massive Multitask Language Understanding) among Korean-specific benchmarks
- Demonstrates strong performance in internal evaluations across language, humanities, and social science tasks compared to comparable domestic models
- Successfully deployed in two sizes (2.3B Mini and 11.5B Base) to cover both resource-constrained and general-purpose use cases
Breakthrough Assessment
6/10
Solid contribution to region-specific LLMs with a strong focus on data quality and cultural alignment, though the architectural innovation (Depth-up Scaling) is an application of existing techniques rather than a novel method.