📝 Paper Summary
Mechanistic Interpretability
Factuality and Hallucination
Internal Knowledge Retrieval
The authors introduce PRISM, a method to disentangle fact completion into four distinct scenarios (exact recall, heuristics, guesswork, generic modeling), showing that previous interpretability findings conflate these behaviors.
Core Problem
Current mechanistic interpretability studies assume correct model predictions imply 'fact recall,' failing to distinguish between actual memorization, shallow heuristics, or lucky guesses.
Why it matters:
- Treating all correct predictions as 'knowledge' leads to misleading conclusions about where and how LMs store facts.
- Models relying on shallow heuristics (e.g., name bias) are unreliable and prone to hallucination, but current evaluation methods often mask this behavior.
- Existing datasets like CounterFact contain mixtures of these behaviors (e.g., 510/1209 samples likely rely on heuristics), contaminating interpretability results.
Concrete Example:
Given the query 'Astrid Lindgren was born in', a model might predict 'Sweden' because it memorized the fact (Recall) or because it associates Swedish-sounding names with Sweden (Heuristic). Previous methods treat both as identical 'knowledge,' obscuring the underlying mechanism.
Key Novelty
PRISM (Precise Identification of Scenarios for Model behavior)
- Decomposes 'fact completion' into four distinct scenarios: Generic Language Modeling, Guesswork, Heuristics Recall, and Exact Fact Recall based on diagnostic criteria (confidence, heuristics usage, fact completion).
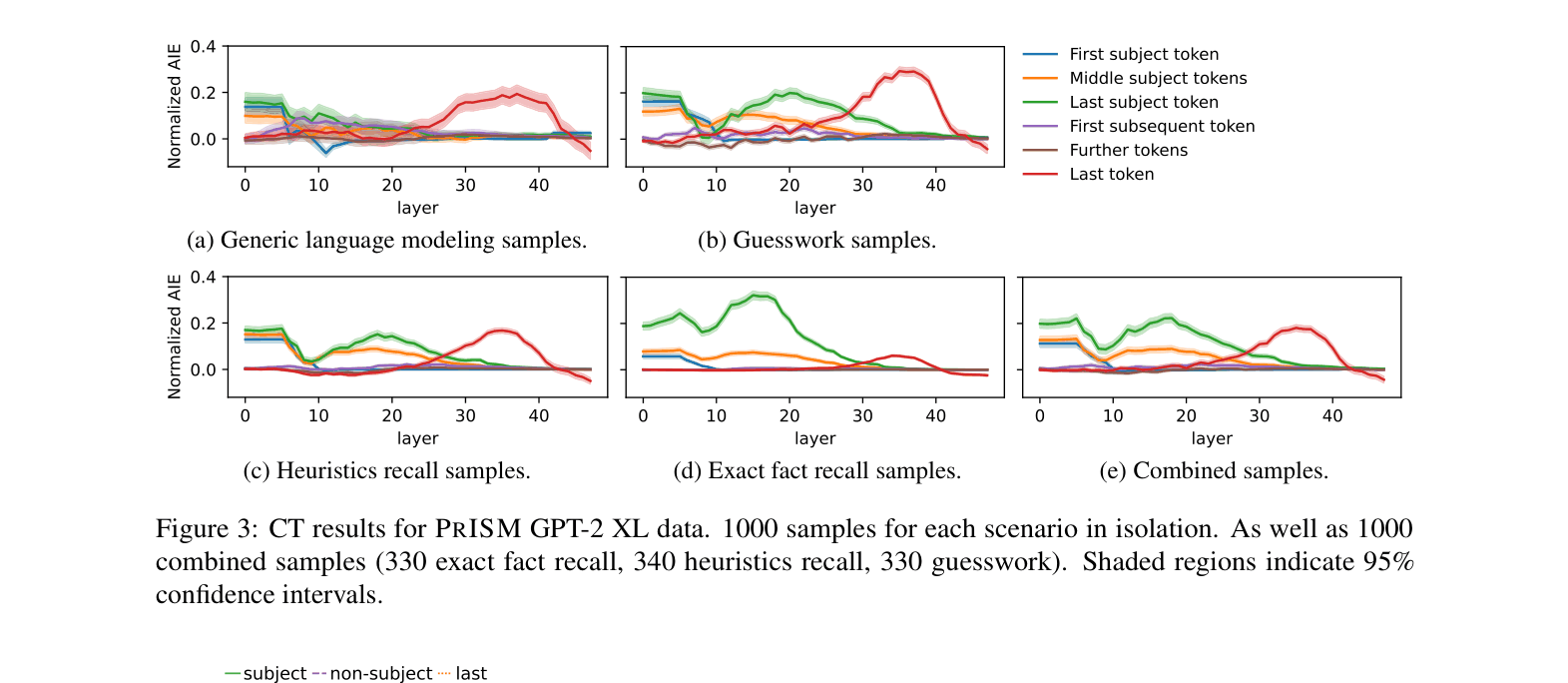
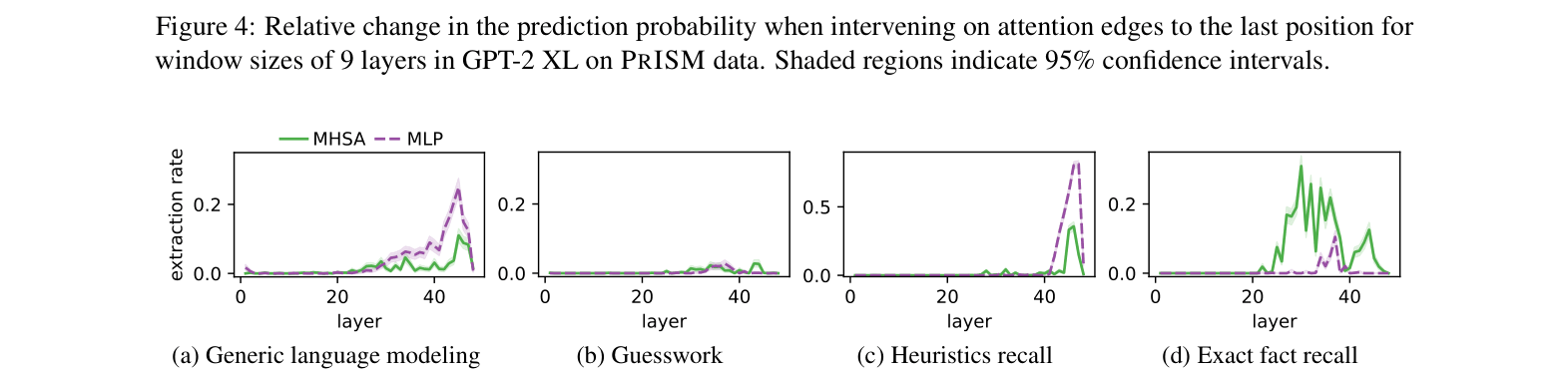
- Demonstrates that widely accepted interpretability signatures (like mid-layer MLP importance) primarily hold for 'Exact Fact Recall' but vanish or shift for Heuristics and Guesswork.
Architecture

Conceptual diagram of the four prediction scenarios (Generic LM, Guesswork, Heuristics, Exact Fact Recall) and their diagnostic criteria.
Evaluation Highlights
- Exact Fact Recall samples in GPT-2 XL confirm the importance of mid-range MLP sublayers (consistent with previous literature), but this pattern disappears for Heuristics Recall samples.
- Interpretability results on mixed samples (simulating previous datasets) reproduce prior findings, proving that earlier conclusions were dominated by high-confidence recall samples while masking other behaviors.
- A linear probe trained on internal states (Causal Tracing effects) achieves 0.72-0.78 accuracy in classifying the four prediction scenarios across GPT-2 XL and Llama 2 models.
Breakthrough Assessment
8/10
Significantly refines the understanding of 'knowledge' in LMs by proving that 'correct prediction' != 'fact recall.' The decomposition into four scenarios resolves inconsistencies in prior interpretability work.