📝 Paper Summary
Modularized RAG pipeline
Query rewriting / query generation
QPaug improves Open-Domain QA by augmenting the original question with LLM-generated sub-questions to enhance retrieval, and augmenting retrieved contexts with LLM-generated factual passages to guide answer extraction.
Core Problem
Retrieval-Augmented Generation (RAG) often fails on complex/ambiguous questions because standard retrievers fetch irrelevant passages, and readers struggle when retrieved contexts are distracting or incomplete.
Why it matters:
- Standard retrievers (like BM25 or dense retrieval) often miss relevant documents for complex multi-hop questions
- LLMs have vast parametric knowledge that is often overridden or ignored when relying solely on potentially noisy retrieved contexts
- Fine-tuning LLMs to handle retrieval noise is computationally expensive or impossible for black-box APIs
Concrete Example:
For the question 'Who is the spouse of the director of film Eden And After?', standard retrieval fetches irrelevant biographical info about actors. QPaug first decomposes this into 'Identify the Director' -> 'Research the Director's spouse', retrieves better documents, and self-generates a passage containing the correct spouse (Catherine Robbe-Grillet), enabling the correct answer.
Key Novelty
Dual-stage augmentation via In-Context Learning (QPaug)
- Question Augmentation (Qaug): Uses Chain-of-Thought prompting to decompose a complex question into a plan of sub-questions, which are appended to the query to guide the retriever toward more relevant documents.
- Passage Augmentation (Pgen): Explicitly prompts the LLM to generate a 'factual' passage from its own parametric knowledge (or output [NONE]), which is then treated as an additional context document alongside retrieved ones.
Architecture
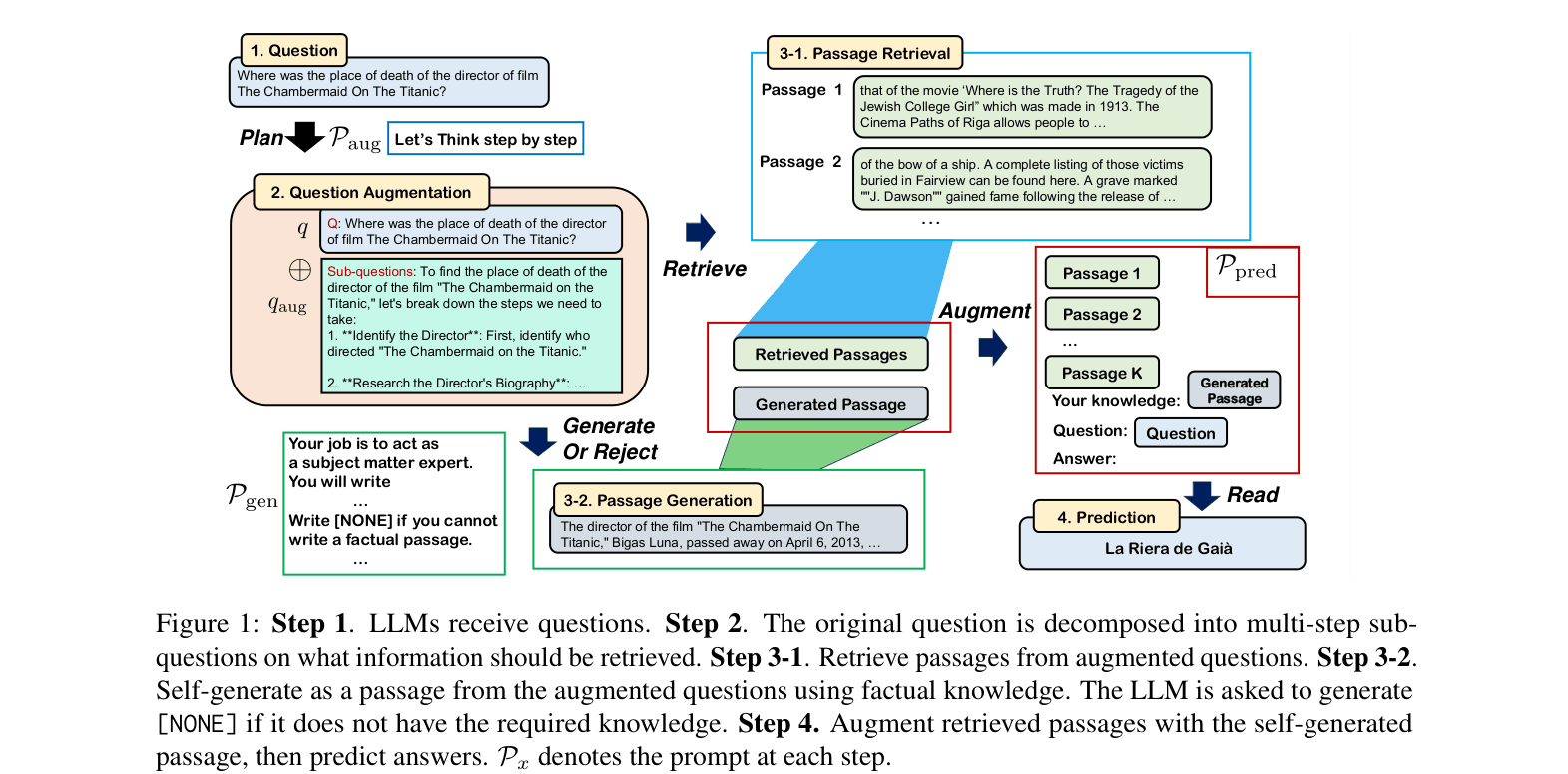
The QPaug workflow: Question Augmentation (Step 2), Passage Retrieval (Step 3-1), Passage Self-Generation (Step 3-2), and Answer Prediction (Step 4).
Evaluation Highlights
- Outperforms SuRE (previous SOTA) by +10.4% F1 on Natural Questions and +34.2% F1 on HotpotQA using GPT-3.5 and Contriever
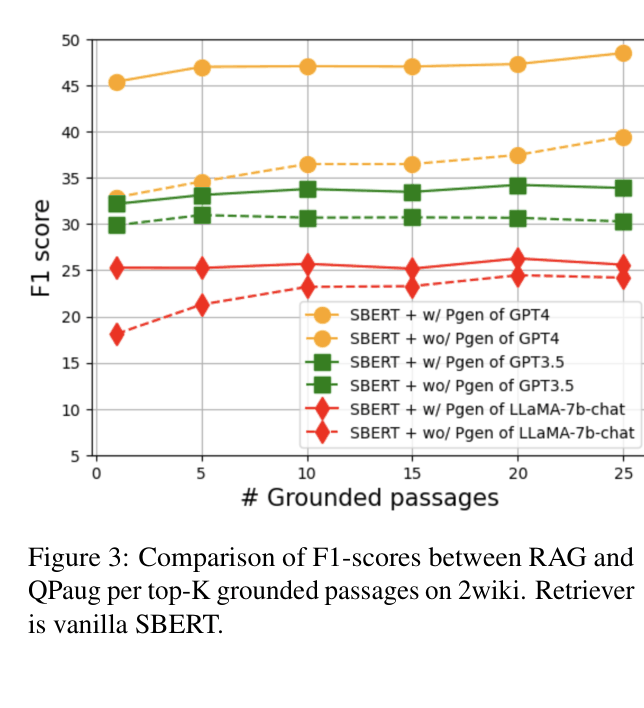
- Achieves large gains on multi-hop datasets: +34.2% Rouge improvement on 2WikiMultihopQA using GPT-4 with SBERT compared to no retrieval
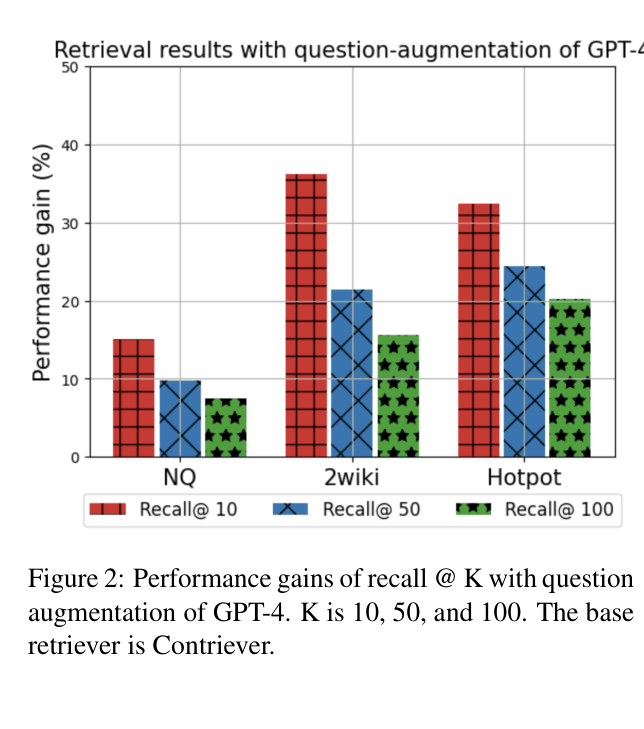
- Question augmentation alone improves retrieval Recall@10 by up to 30% with GPT-4 compared to standard retrieval
Breakthrough Assessment
8/10
Simple yet highly effective prompting strategy that harmonizes parametric and non-parametric knowledge. Significant gains on multi-hop benchmarks without requiring model fine-tuning.