📝 Paper Summary
Data-Efficient Fine-Tuning
Text Editing / Rewriting
Core-Set Selection
DEFT-UCS reduces fine-tuning data requirements by clustering unlabeled text embeddings and sampling hard/easy examples to train high-performance text-editing models.
Core Problem
Fine-tuning Pre-trained Language Models (PLMs) typically requires large amounts of high-quality data, which is expensive and difficult to acquire for niche domains.
Why it matters:
- Real-world applications often lack the massive annotated datasets (e.g., 52k-395k samples) used by standard instruction-tuning methods
- Existing pruning metrics (EL2N, perplexity) require labeled task data or reference models, making them impractical when annotations are scarce
- Current methods focus on parameter efficiency (PEFT) rather than data efficiency, missing the opportunity to reduce annotation costs
Concrete Example:
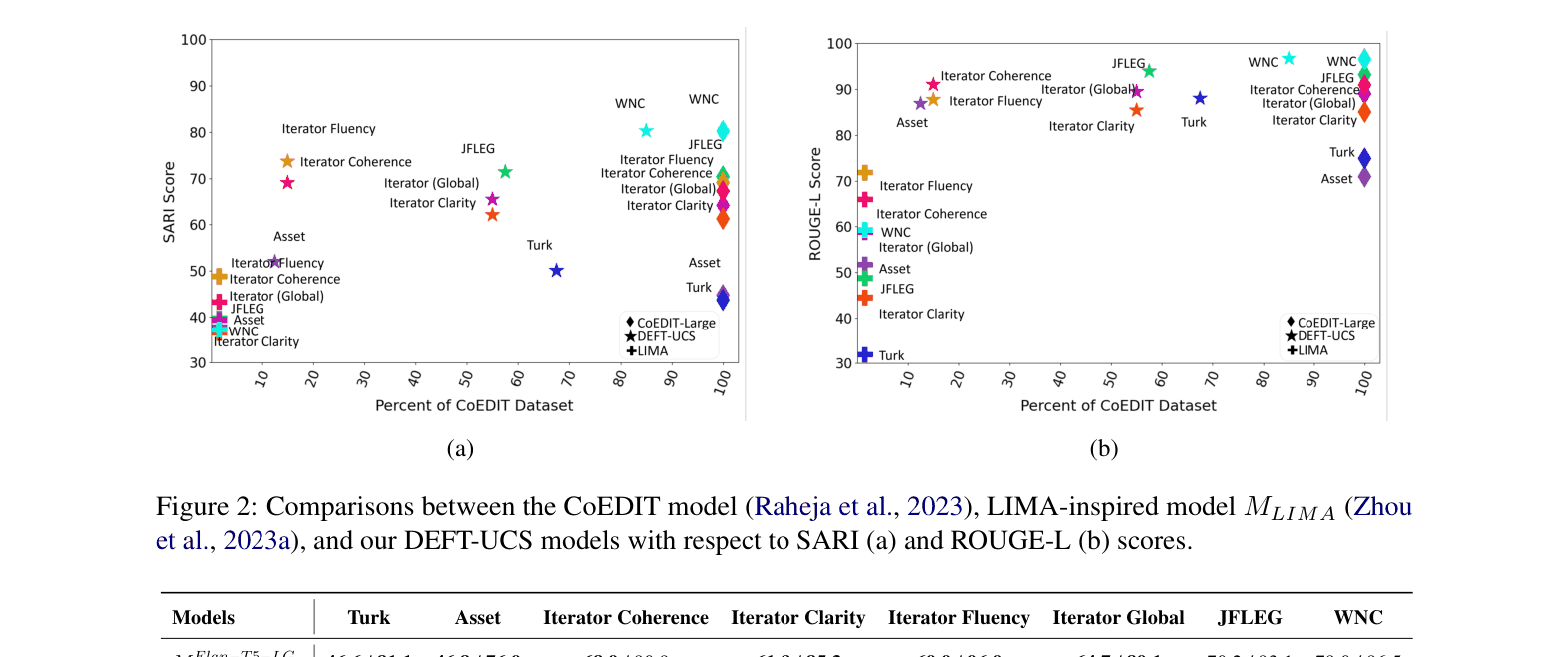
To fine-tune a model for text simplification using the Asset dataset, standard approaches use the full dataset. DEFT-UCS achieves superior SARI scores using only ~12% of the original CoEDIT training data by selectively sampling 'hard' examples farthest from cluster centroids.
Key Novelty
Unsupervised Clustering-based Core-Set Selection (DEFT-UCS) for Text Editing
- Embeds training instructions/inputs into a latent space (using Sentence-T5) and groups them using K-Means clustering
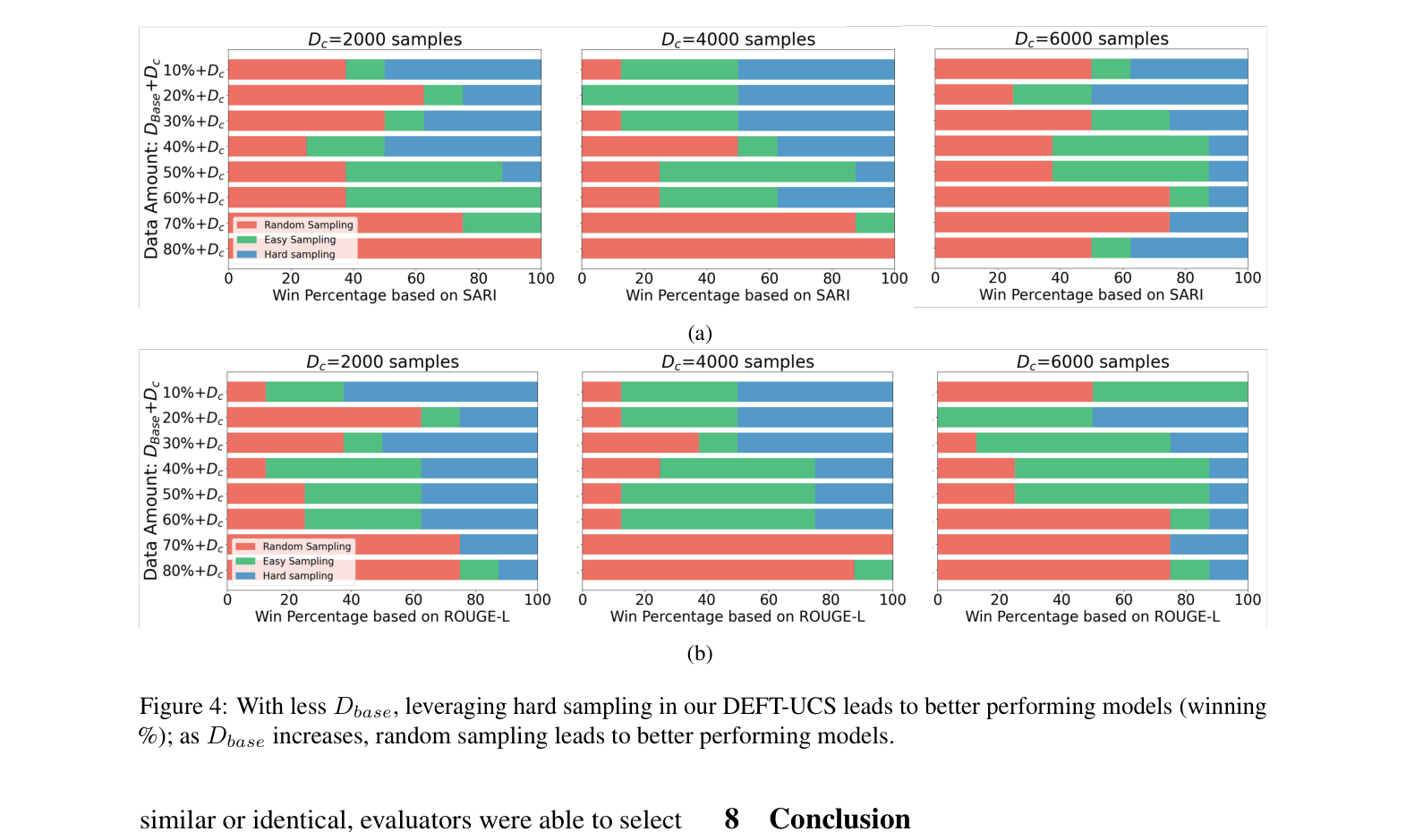
- Selects a 'core-set' of data by sampling specific ratios of 'easy' (close to centroid) and 'hard' (far from centroid) examples from each cluster without needing labels
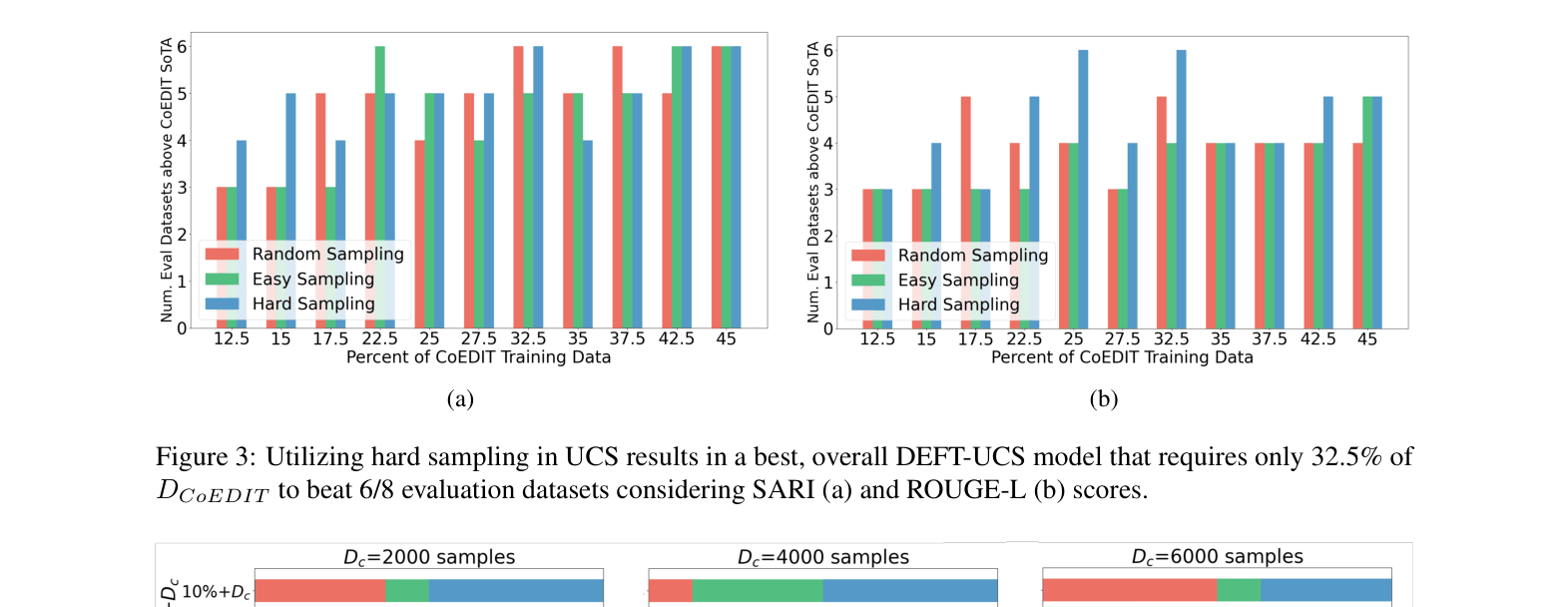
- Demonstrates that models fine-tuned on just 32.5% of data (via hard sampling) can match or beat models trained on the full dataset
Architecture
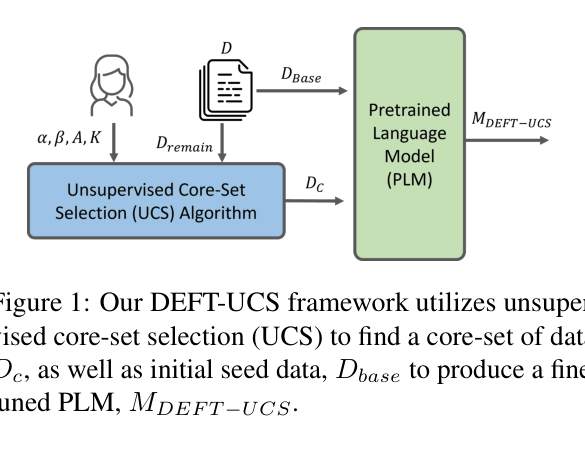
Conceptual framework of DEFT-UCS showing the data selection process.
Evaluation Highlights
- DEFT-UCS model trained on 32.5% of CoEDIT data surpasses the state-of-the-art CoEDIT model on 6 out of 8 evaluation datasets
- +4.2 SARI improvement on the Iterator Fluency dataset compared to the full-data CoEDIT baseline
- Human evaluators preferred or found DEFT-UCS edits accurate 83.8% of the time, compared to 70.5% for the full CoEDIT model
Breakthrough Assessment
7/10
Strong empirical evidence that unsupervised pruning works for generative text tasks, challenging the need for massive datasets. However, relies on existing clustering techniques rather than a novel algorithm.