📝 Paper Summary
Hallucination suppression
Mechanistic Interpretability
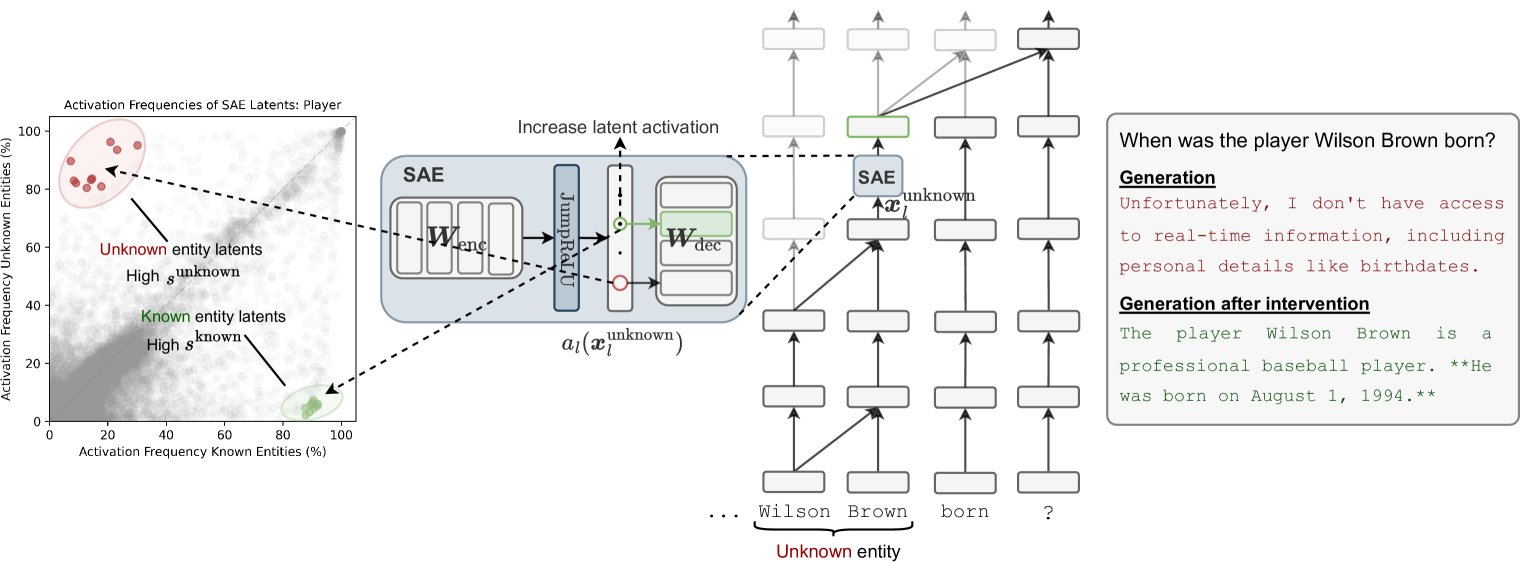
The paper identifies specific directions in LLM representation space using Sparse Autoencoders that encode whether the model recognizes an entity, enabling causal steering of refusal behaviors to reduce hallucinations.
Core Problem
LLMs frequently hallucinate when prompted about entities they do not know, and the internal mechanisms governing whether a model refuses to answer or invents facts are poorly understood.
Why it matters:
- Hallucinations limit LLM deployment in critical fields like healthcare where factuality is essential
- Current understanding focuses on factual recall of *known* facts, leaving a gap in understanding the mechanism of *unknown* facts and refusals
- Fine-tuning for refusal behavior is effective but opaque; understanding the underlying mechanism allows for more robust control
Concrete Example:
When asked 'When was the player Wilson Brown born?' (a non-existent entity), a base model might hallucinate a date. The proposed method detects the model's lack of recognition and can force a refusal ('I don't know...') or conversely force a hallucination on a known entity.
Key Novelty
Entity Recognition Directions via SAEs
- Discovers specific directions in the residual stream (via SAE latents) that activate when the model processes a known vs. an unknown entity
- Demonstrates these directions are causal: steering along them can force a chat model to refuse a known entity or hallucinate an unknown one
- Finds that these mechanisms, discovered in the base model, are repurposed by the chat model to implement refusal behaviors
Architecture
The mechanistic circuit of factual recall and how the discovered latents interfere with it.
Evaluation Highlights
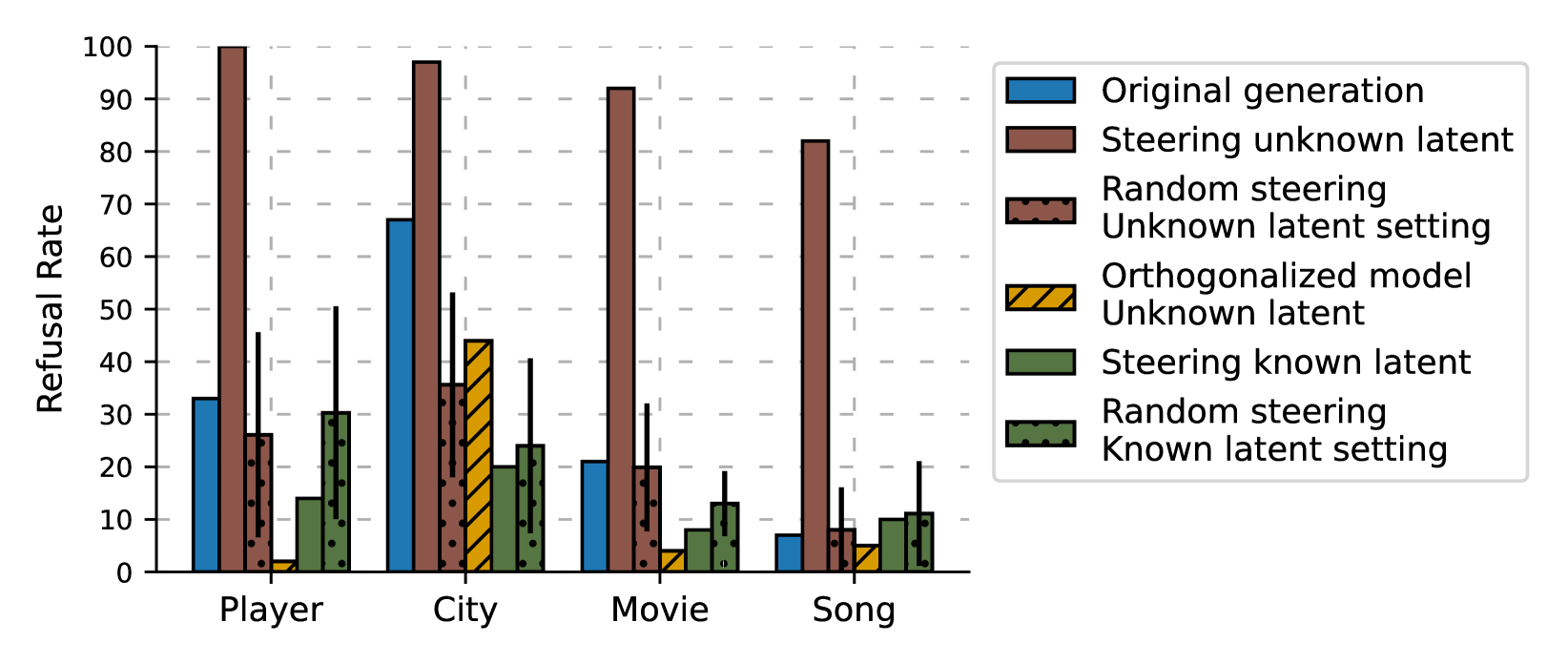
- Steering with the 'unknown entity' latent induces nearly 100% refusal rates across diverse entity types (players, movies, cities) in Gemma 2 2B
- Latents distinguishing known/unknown entities generalize across types (e.g., a latent found for athletes also works for songs)
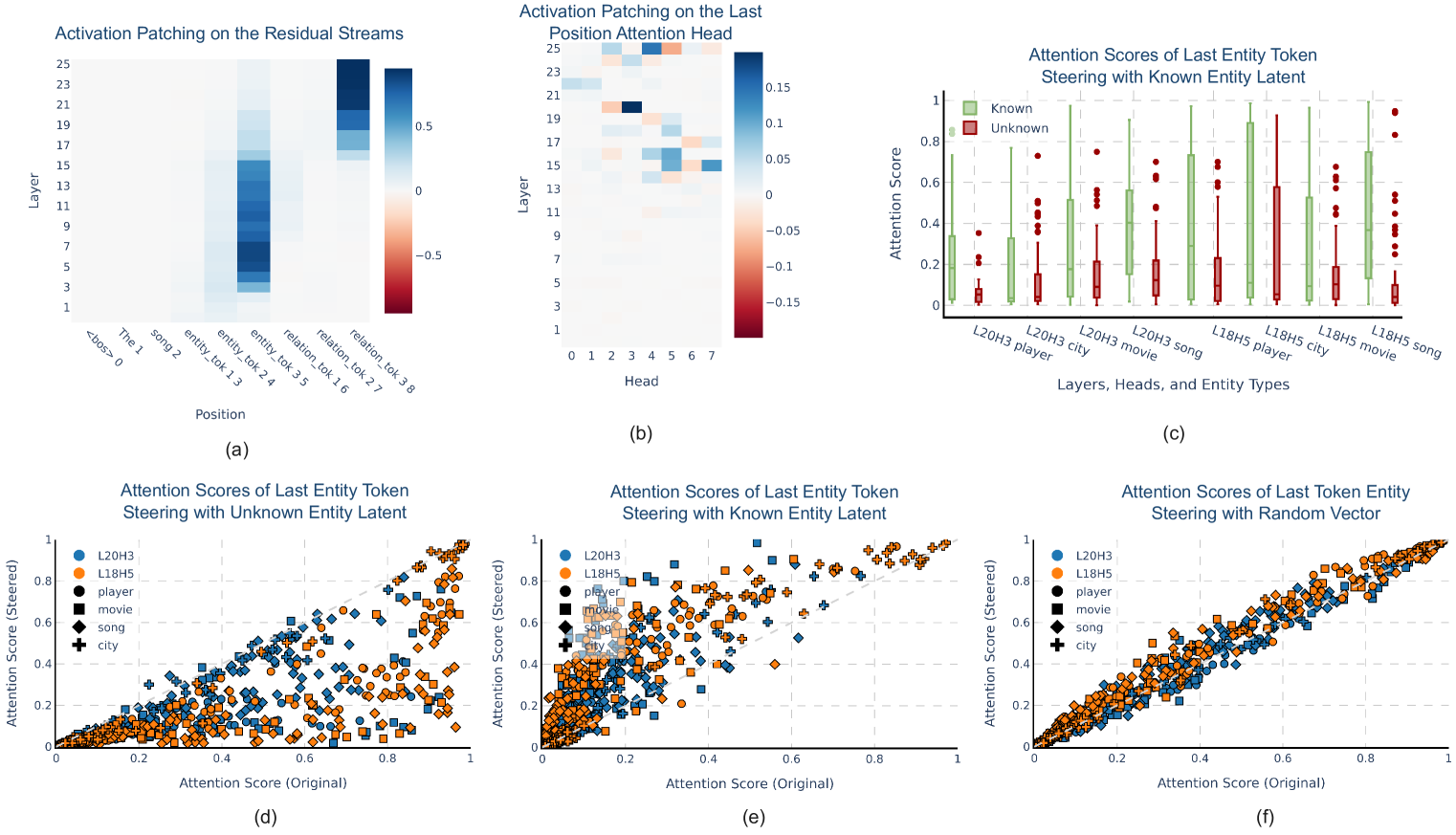
- Identifies that 'unknown' directions mechanically disrupt downstream attention heads responsible for attribute extraction
Breakthrough Assessment
8/10
Strong mechanistic evidence linking specific SAE features to high-level refusal behavior. The finding that base model features are repurposed for chat refusal is a significant insight for alignment.