📝 Paper Summary
Syntactic Inductive Bias
Transformer Interpretability & Control
Compositional Generalization
TreeReg is a differentiable regularizer that softly constrains transformer attention heads to encode hierarchical syntactic structure by maximizing the orthogonality of constituent representations relative to their context.
Core Problem
Transformers lack explicit hierarchical structure, processing text sequentially rather than compositionally, which leads to poor performance on tasks requiring syntactic generalization (e.g., tense inflection, question formation) and data inefficiency.
Why it matters:
- LLMs still struggle with compositional generalization (understanding familiar words in novel contexts) despite massive scale
- Existing methods to inject syntax (Syntactic LMs) often require complex architectures, slower inference, or rigid constraints that hamper scalability
- Humans process language hierarchically; aligning models with this structure could improve data efficiency and robustness
Concrete Example:
In the sentence 'I know who you introduced to them', a standard model might fail to assign higher surprisal to the third word compared to 'I know that you introduced to them' due to missing the hierarchical constraint of the embedded clause. TreeReg helps the model internalize these structural dependencies.
Key Novelty
Soft Syntactic Regularization via Orthogonality (TreeReg)
- Defines a 'Span Contextual Independence Score' (SCIN) that measures how independent a span's vector representation is from its surrounding context
- Adds a loss term that maximizes SCIN for valid syntactic constituents (from a parser) and minimizes it for non-constituents, forcing specific attention heads to encode tree structure
- Requires no architectural changes or inference-time overhead; the model remains a standard transformer after training
Architecture
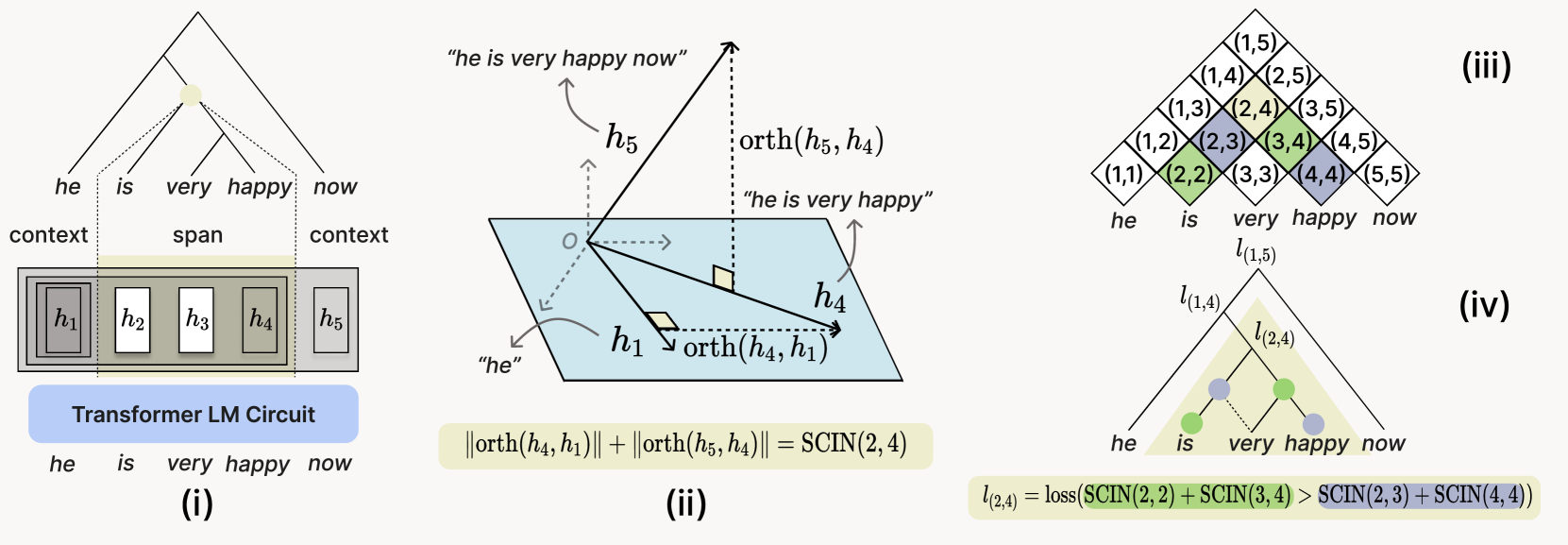
Conceptual illustration of the TreeReg objective applied to a transformer circuit
Evaluation Highlights
- Up to 10% lower perplexity on out-of-distribution data (WikiText-103) when pre-trained with TreeReg
- Achieves better syntactic generalization than standard LMs using less than half the training data
- Mitigates performance degradation on adversarial NLI benchmarks by 41.2 points when fine-tuning Sheared Llama
Breakthrough Assessment
7/10
A clean, mathematically elegant method to inject syntax without architectural bloat. Strong results on efficiency and robustness, though relies on 'silver' parses during training.