📝 Paper Summary
Commonsense Reasoning
Knowledge Generation
Small-scale LLMs
GuideKG improves commonsense reasoning in small LLMs by using a lightweight filter to select helpful knowledge sentences during generation, guiding the model toward accurate answers without human annotation.
Core Problem
Small-scale LLMs (under 10B parameters) struggle with commonsense reasoning because they often generate inaccurate or irrelevant knowledge, and external retrieval is limited by coverage and noise.
Why it matters:
- LLMs frequently halluncinate incorrect facts during reasoning, leading to wrong answers in tasks requiring world knowledge.
- Existing methods relying on external knowledge bases (like Wikipedia) fail when the retrieval system retrieves irrelevant context.
- Manual annotation of 'good' vs 'bad' reasoning chains is expensive, hindering the training of effective verifiers.
Concrete Example:
When answering 'It is labeled a month only if it lasts at least 31 days?', retrieved knowledge about 'weeks' is irrelevant. An unguided LLM might hallucinate that 'a month is defined as a specific number of days' (leading to a wrong answer). GuideKG filters these out, guiding the LLM to generate 'A month is considered long if it has 31 days... but February has 29', leading to the correct answer.
Key Novelty
Guided Knowledge Generation (GuideKG)
- Treats knowledge generation as a search process where a small 'Know-Filter' scores the utility of each generated sentence for solving the specific question.
- Automates training data creation by labeling generated knowledge based on whether it leads the LLM to the correct answer, eliminating manual labeling costs.
- Injects the best filtered knowledge back into the prompt sentence-by-sentence to steer the LLM's subsequent generation (Sentence-Level Fusion Generation).
Architecture
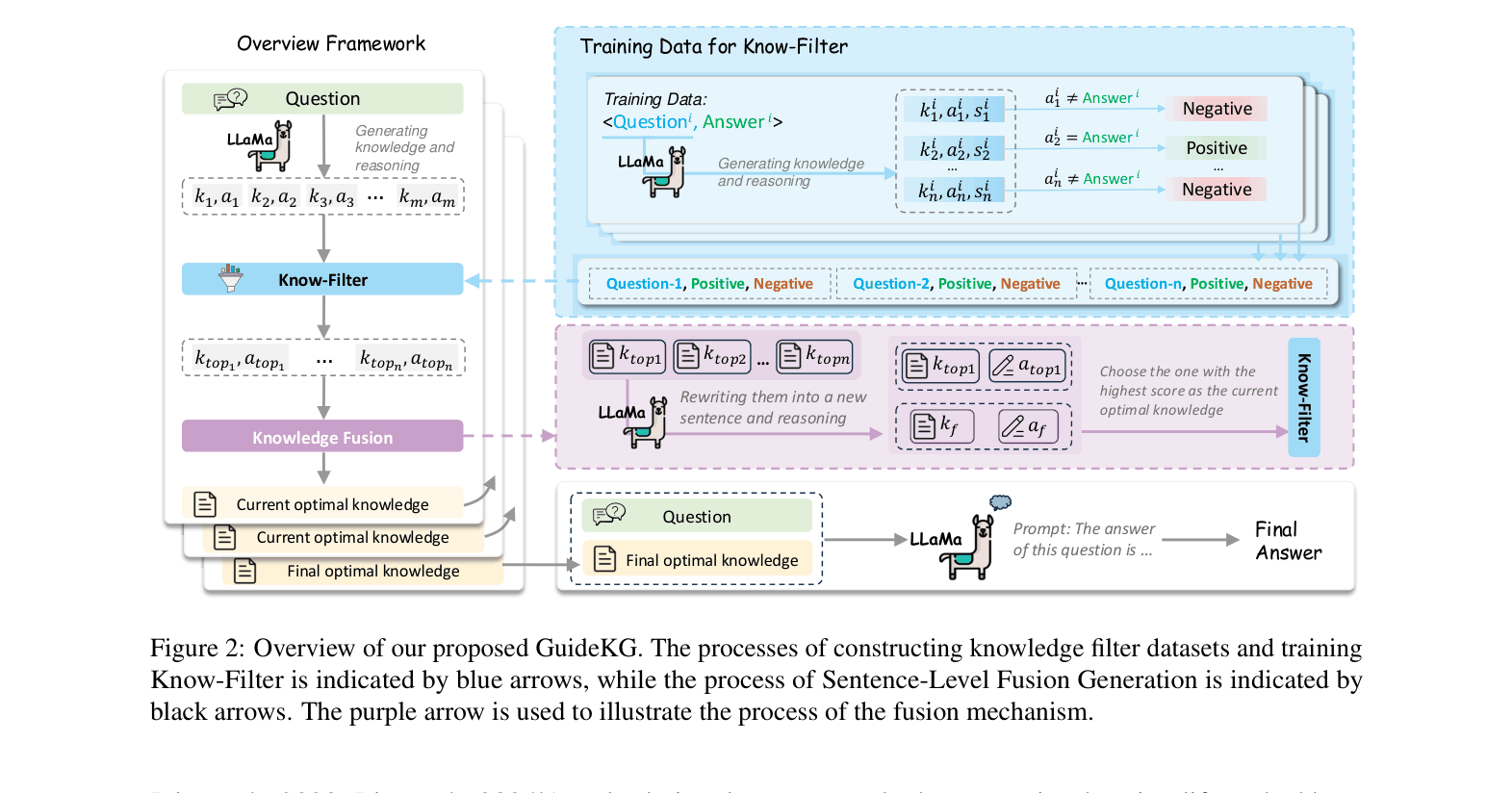
The complete GuideKG framework. It illustrates the pipeline: generating candidate knowledge, filtering with Know-Filter, fusing top candidates, and iteratively generating the next sentence.
Evaluation Highlights
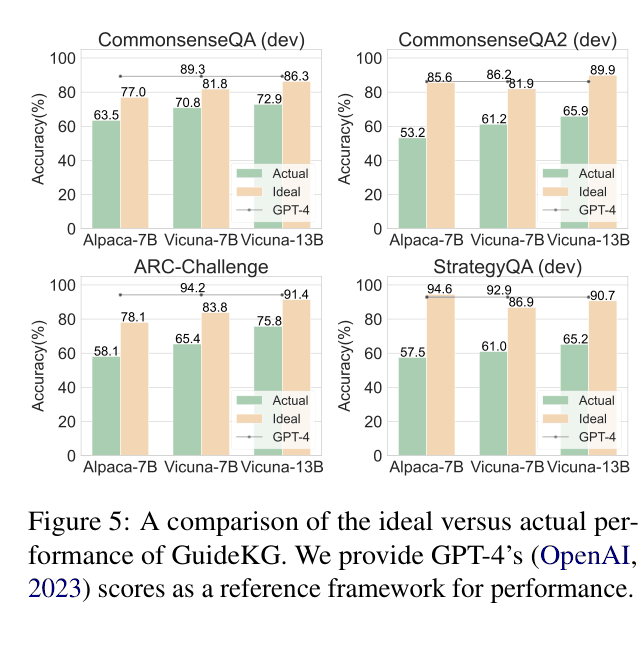
- Outperforms standard prompting by +8.6% accuracy on CommonsenseQA using Vicuna-7B (70.8% vs 62.2%).
- Surpasses retrieval-augmented baselines by +7.6% on CommonsenseQA2 using Vicuna-7B (60.4% vs 52.8%).
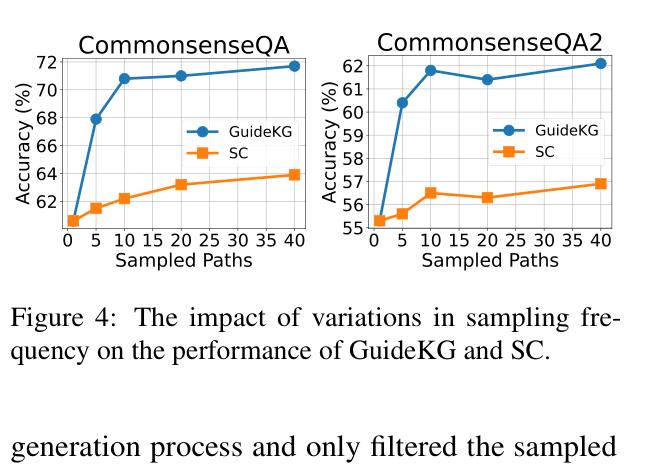
- Achieves higher accuracy than self-consistency (SC) across four benchmarks, e.g., +2.4% over SC on ARC-Challenge with Vicuna-13B.
Breakthrough Assessment
7/10
Strong empirical results on small LLMs and a clever self-supervised training loop for the filter. While not a fundamental architectural shift, it offers a practical, cost-effective way to boost reasoning without massive external indices.