📝 Paper Summary
Modularized RAG pipeline
KBAlign adapts language models to small-scale textual knowledge bases by generating multi-grained synthetic QA pairs and refining the model through iterative self-verification, without external supervision.
Core Problem
Standard RAG models struggle with domain-specific small-scale knowledge bases (KBs): unsupervised training is ineffective, while fine-tuning is costly due to the lack of labeled data or reliance on expensive external models like GPT-4.
Why it matters:
- Real-world scenarios often involve private, small-scale documents (e.g., personal records, company wikis) where data privacy or cost prevents using large commercial APIs
- Vanilla unsupervised pre-training (language modeling) on small corpora often degrades instruction-following capabilities or fails to capture structured knowledge
- Current methods like RAFT rely on high-cost external supervision (GPT-4) to generate training data, which is impractical for resource-constrained settings
Concrete Example:
When asking about "LLM" in a legal context, a general model treats it as "Large Language Model." An unadapted RAG might miss the context entirely. KBAlign self-annotates the legal KB to learn that "LLM" means "Master of Laws" and generates synthetic questions to fine-tune this specific understanding.
Key Novelty
Self-Supervised Adaptation via Multi-Grained Annotation and Iterative Verification
- Analogy to student learning: The model first 'self-studies' the textbook (KB) by generating its own practice questions (short-dependency for facts, long-dependency for reasoning)
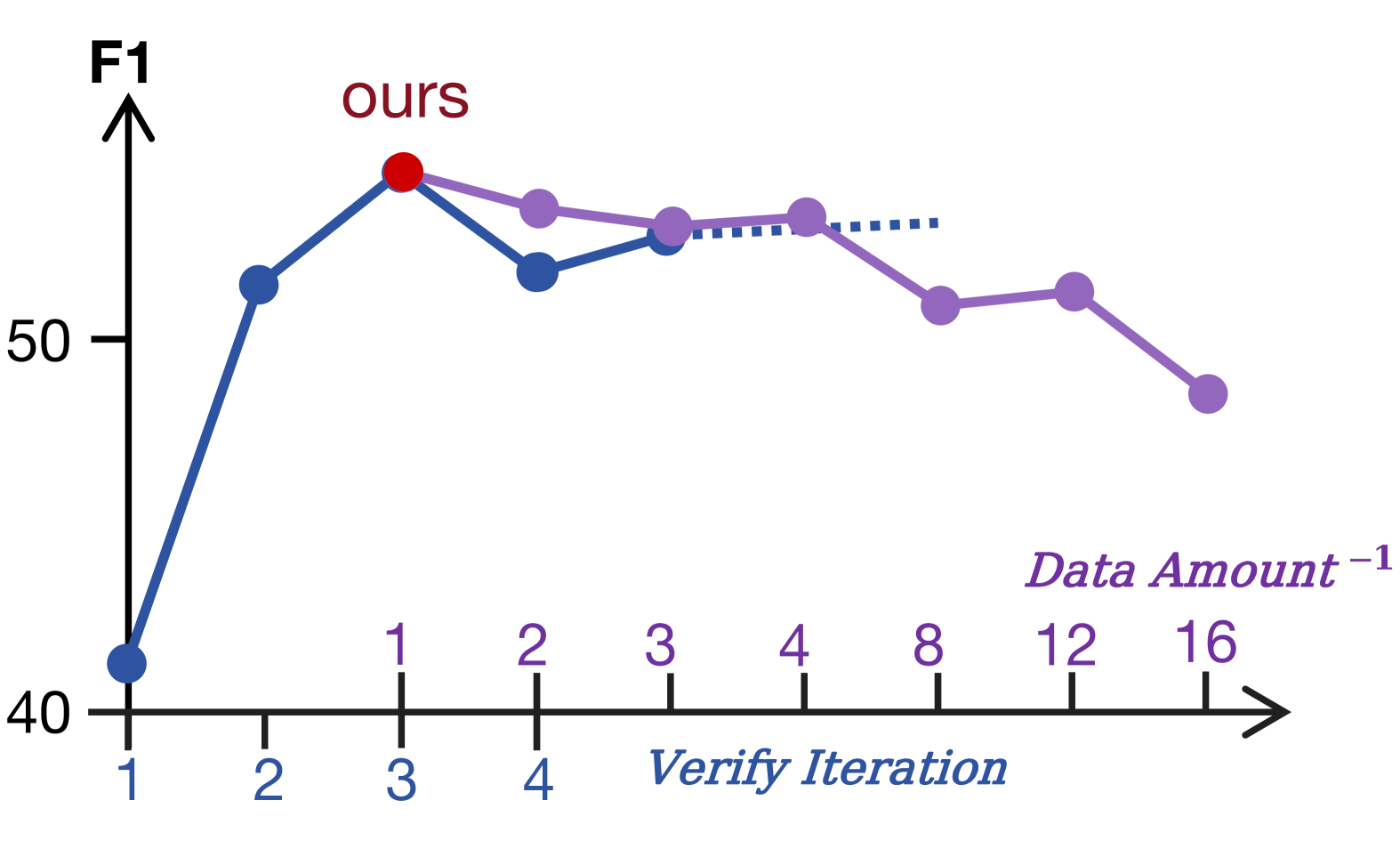
- The model then 'takes tests' (iterative tuning) where it answers its own questions using RAG, verifies the answers against the ground truth it generated, and learns from its mistakes
Architecture
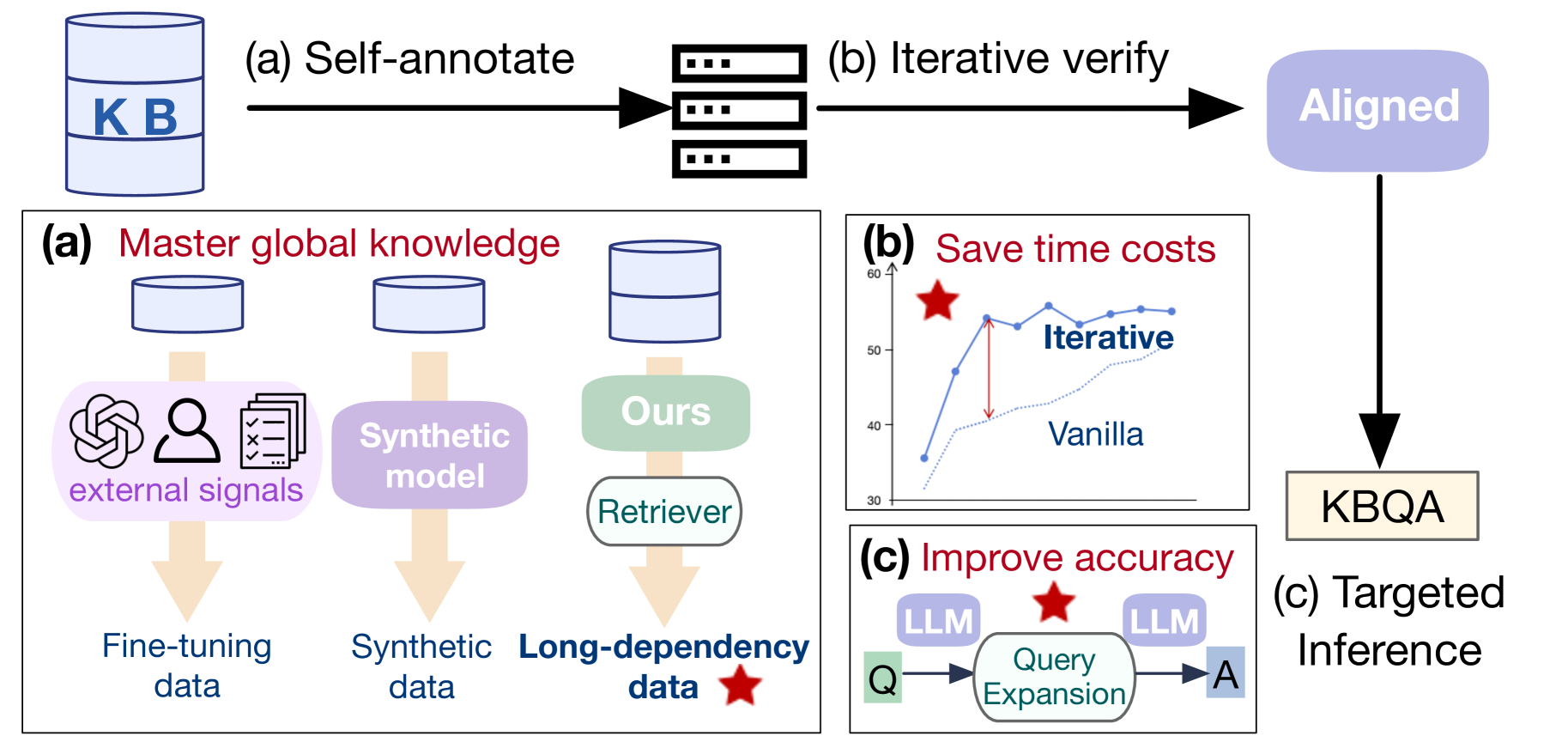
The overall KBAlign framework illustrating the three main phases: Self Annotation, Iterative Tuning, and Targeted Inference.
Evaluation Highlights
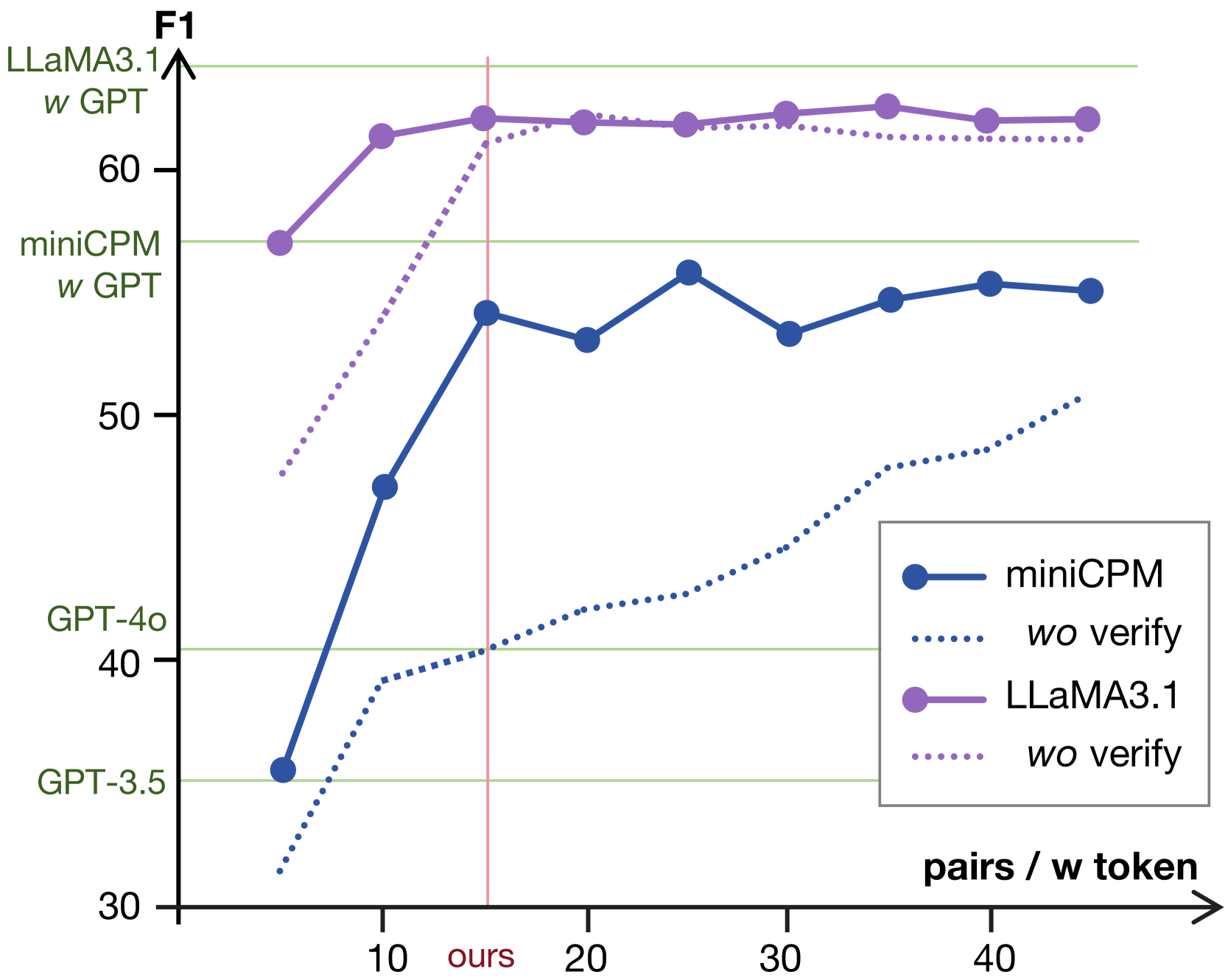
- Achieves 90% of the performance gain of GPT-4-supervised adaptation (RAFT) while using only a 2B parameter model for self-annotation
- +20.6 F1 score improvement on LooGLE (long-context knowledge) compared to vanilla RAG with MiniCPM-2B
- Surpasses LLaMA-3-8B-Instruct and GPT-4o performance on LooGLE using an adapted MiniCPM-2B model
Breakthrough Assessment
7/10
Strong practical contribution for low-resource domain adaptation. Demonstrates that small models can self-align to KBs effectively without massive external supervision, challenging the assumption that GPT-4 is required for high-quality synthetic data.