📝 Paper Summary
Visual Language Models (VLMs)
Efficient Deep Learning
Model Compression
NVILA optimizes Visual Language Models by scaling up resolution for accuracy and then compressing visual tokens for efficiency, alongside system-level improvements in training and deployment.
Core Problem
Current VLMs are computationally expensive to train, memory-intensive to fine-tune, and resource-heavy to deploy, while simpler architectures like VILA struggle with limited spatial/temporal resolution.
Why it matters:
- Training state-of-the-art VLMs takes hundreds of GPU days, creating a high entry barrier
- Fine-tuning requires massive GPU memory (e.g., >64GB for 7B models), limiting accessibility
- Deployment on edge devices is constrained by limited computational budgets and strict latency requirements
Concrete Example:
Original VILA resizes all images to 448x448 regardless of aspect ratio, causing distortion and detail loss in text-heavy images. Doubling resolution improves accuracy but quadruples cost due to quadratic self-attention scaling.
Key Novelty
Scale-then-Compress Architecture & Full-Lifecycle Efficiency
- First scales up image resolution (using Dynamic-S2) and video frame counts to capture details, then compresses visual tokens (via spatial-to-channel reshape or temporal averaging) to reduce compute
- Uses DeltaLoss to prune training data by filtering out examples that are too easy or too hard (where small/large models agree or disagree in specific patterns)
- Implements system-level optimizations like FP8 mixed-precision training and 4-bit quantization for deployment
Architecture
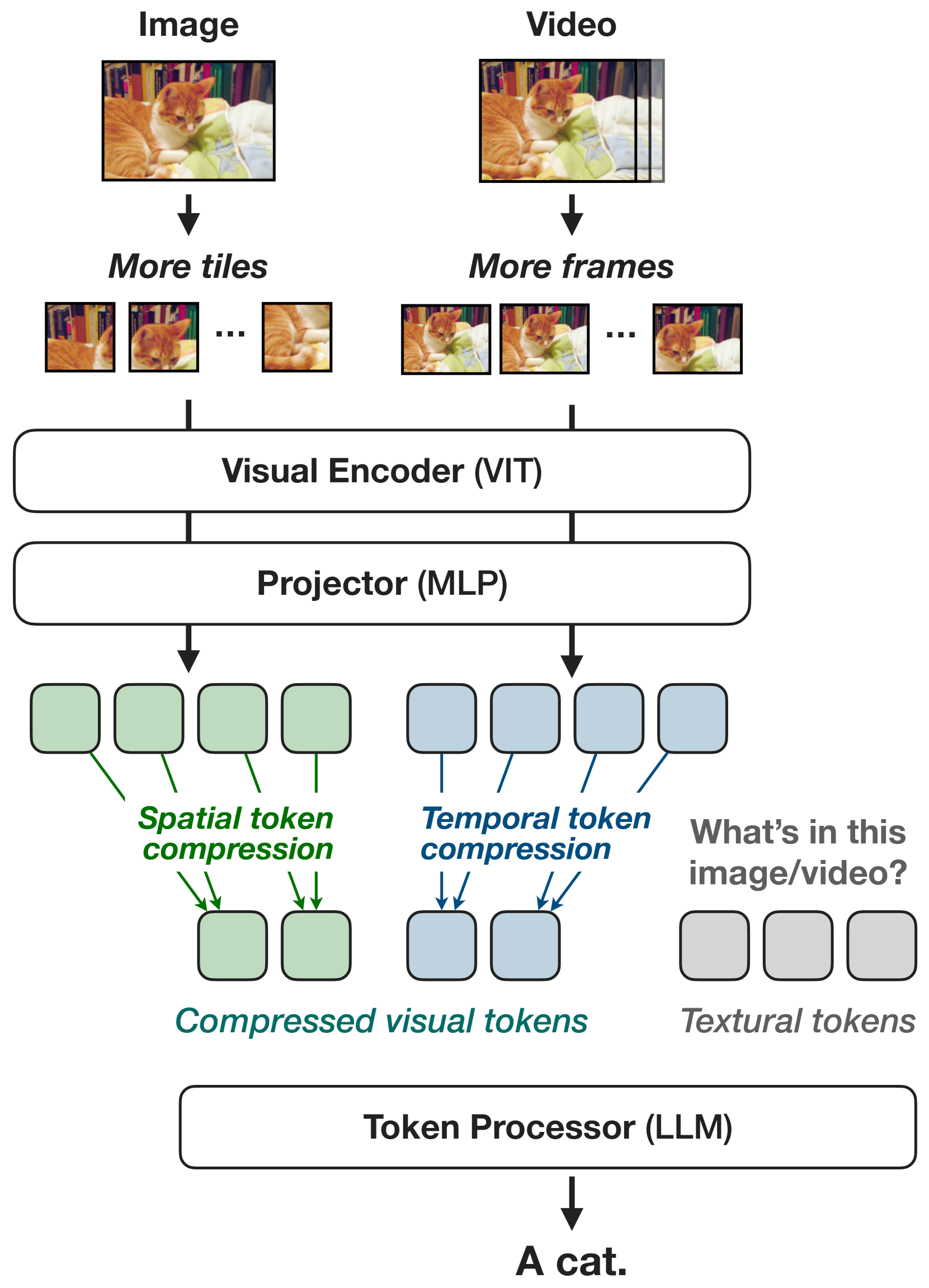
The NVILA architecture pipeline.
Evaluation Highlights
- +30% accuracy improvement on text-heavy benchmarks compared to limited-resolution baselines (Table 1)
- Reduces training costs by 1.9-5.1x and prefilling latency by 1.6-2.2x compared to baselines
- Matches or surpasses accuracy of leading open VLMs (e.g., LLaVA-NeXT, InternVL-1.5) and proprietary models (GPT-4V) across diverse benchmarks
Breakthrough Assessment
9/10
Comprehensive full-stack optimization (architecture, data, system) yielding massive efficiency gains while achieving SOTA accuracy. Highly practical contribution.